في ظهر يوم 20 يناير، أعلنت X عن إتاحة أحدث خوارزمية توصية لها كمصدر مفتوح.
علق ماسك: "ندرك أن هذه الخوارزمية بسيطة وما زالت بحاجة إلى تطويرات كبيرة، لكن على الأقل بإمكانك متابعة جهودنا لتحسينها بشكل فوري. بقية منصات التواصل الاجتماعي لن تجرؤ على ذلك."
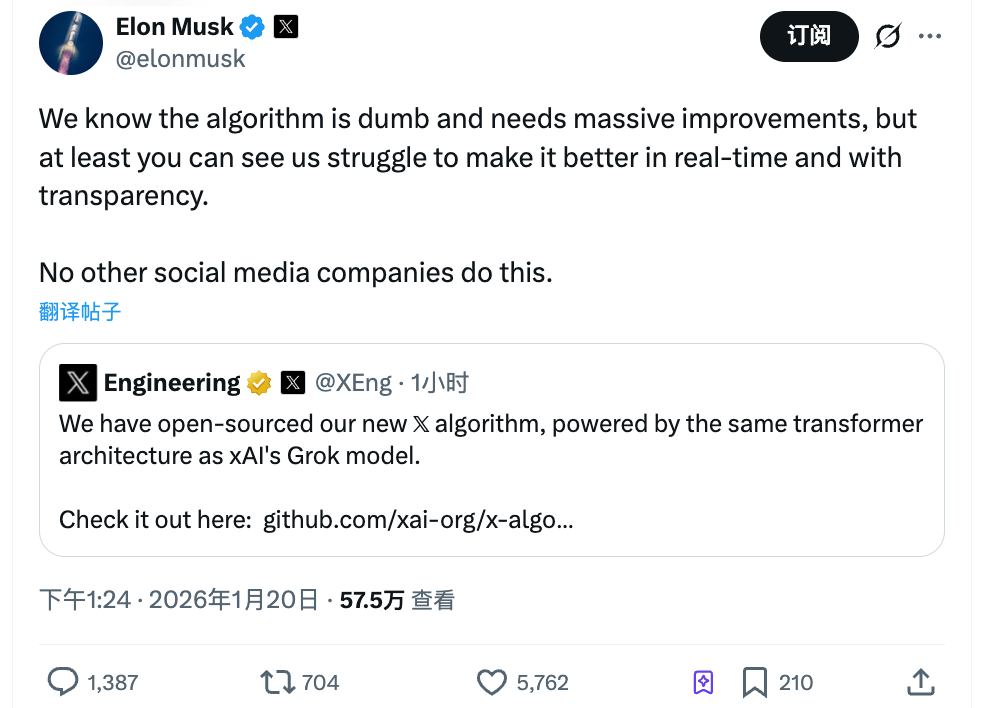
تصريحه يبرز نقطتين أساسيتين: أولًا، إقراره بوجود نواقص في الخوارزمية. ثانيًا، اعتماده على الشفافية كميزة تنافسية رئيسية.
هذه هي المرة الثانية التي تتيح فيها X خوارزميتها كمصدر مفتوح. النسخة السابقة في 2023 ظلت دون تحديثات لثلاث سنوات وكانت معزولة عن نظام الإنتاج. أما هذه المرة، فقد أُعيدت كتابة الشيفرة بالكامل. وانتقل النموذج الأساسي من التعلم الآلي التقليدي إلى محول Grok. ووفقًا للبيان الرسمي: "تم الاستغناء تمامًا عن هندسة الميزات اليدوية."
بعبارة مبسطة: في السابق كان المهندسون يضبطون معلمات الخوارزمية يدويًا. أما الآن، فالذكاء الاصطناعي يحلل سجل تفاعلك ليقرر ما إذا كان سيتم الترويج لمحتواك.
بالنسبة لصناع المحتوى، هذا يعني أن استراتيجيات مثل "أفضل توقيت للنشر" أو "الوسوم المؤثرة" قد لا تعود فعالة.
راجعنا أيضًا مستودع GitHub مفتوح المصدر، وبمساعدة الذكاء الاصطناعي، اكتشفنا بعض الشيفرة المبرمجة يدويًا التي تستحق التحليل.
تحول منطق الخوارزمية: من القواعد اليدوية إلى حكم الذكاء الاصطناعي
لنوضح أولًا الفرق بين النسختين القديمة والجديدة لتفادي أي لبس في النقاش القادم.
في 2023، كانت خوارزمية X مفتوحة المصدر تحمل اسم Heavy Ranker وتعتمد كليًا على التعلم الآلي التقليدي. كان المهندسون يحددون يدويًا مئات الميزات مثل: وجود صور بالمنشور، عدد متابعي الكاتب، زمن النشر، وجود روابط، وغيرها.
كل ميزة كانت تحصل على وزن معين، ويتم تعديل هذه الأوزان باستمرار للوصول لأفضل نتيجة.
الإصدار الجديد مفتوح المصدر يُسمى Phoenix. بنيته مختلفة جذريًا—فكر به كخوارزمية تعتمد على نماذج الذكاء الاصطناعي الضخمة. جوهرها محول Grok، نفس التقنية المستخدمة في ChatGPT وClaude.
الملف التوثيقي الرسمي README يوضح: "تم الاستغناء عن جميع الميزات المصممة يدويًا."
النظام القديم المعتمد على القواعد واستخلاص ميزات المحتوى يدويًا اختفى تمامًا.
فما الذي تعتمده الخوارزمية الآن لتقييم جودة المحتوى؟
الإجابة: تسلسل سلوكياتك. ما الذي أعجبك، لمن رددت، أي منشورات توقفت عندها أكثر من دقيقتين، وأي الحسابات حظرتها. يقوم Phoenix بتغذية هذه السلوكيات إلى المحول ليقوم النموذج بتعلم الأنماط وتلخيصها.
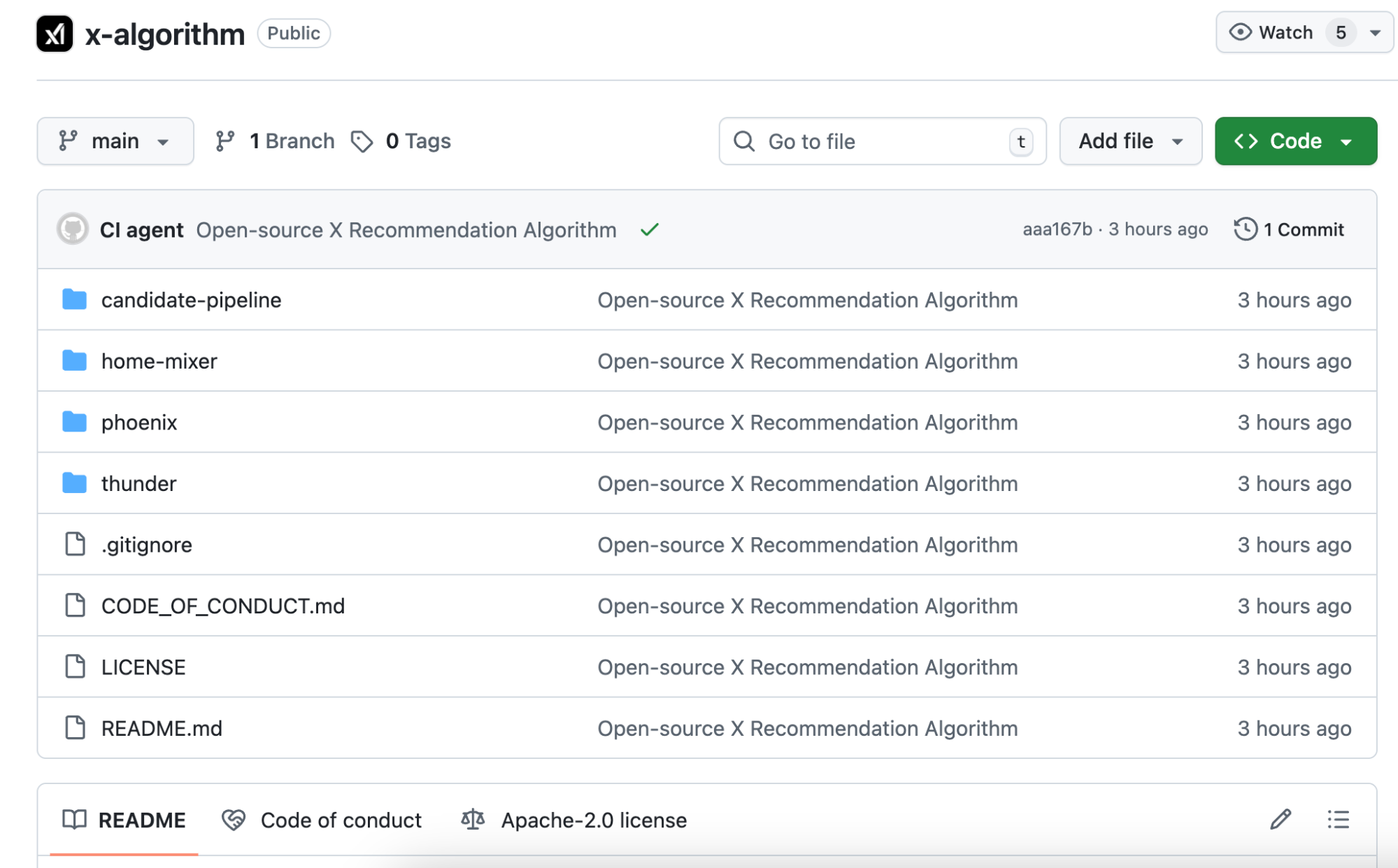
للتوضيح: الخوارزمية القديمة كانت بمثابة بطاقة تقييم يدوية تمنح نقاطًا لكل سلوك.
أما الخوارزمية الجديدة فهي بمثابة ذكاء اصطناعي يطلع على سجل تصفحك بالكامل ويتنبأ بما سترغب برؤيته لاحقًا.
بالنسبة لصناع المحتوى، هذا ينعكس في نقطتين:
أولًا، التكتيكات مثل "أفضل توقيت للنشر" أو "الوسوم الذهبية" لم تعد فعالة كما في السابق. النموذج لم يعد يركز على ميزات ثابتة بل على تفضيلات كل مستخدم.
ثانيًا، الترويج لمحتواك أصبح مرتبطًا أكثر بـ"تفاعل المستخدمين مع محتواك". هذه التفاعلات تُحول إلى 15 نوعًا من التنبؤات السلوكية سنستعرضها لاحقًا.
الخوارزمية تتنبأ بـ 15 نوعًا من تفاعلات المستخدم
عند تقييم Phoenix لأي منشور بهدف التوصية، يقوم بتوقع 15 إجراءً محتملاً للمستخدم:
- الإجراءات الإيجابية: الإعجاب، الرد، إعادة النشر، إعادة النشر مع اقتباس، النقر على المنشور، النقر على ملف الكاتب، مشاهدة أكثر من نصف الفيديو، توسيع صورة، مشاركة، البقاء لفترة معينة، متابعة الكاتب
- الإجراءات السلبية: اختيار "غير مهتم"، حظر الكاتب، كتم الكاتب، الإبلاغ
لكل إجراء احتمالية متوقعة. مثلًا، قد يقدّر النموذج وجود فرصة %60 لإعجابك بمنشور ما وفرصة %5 لحظرك للكاتب.
بعدها، تضرب الخوارزمية كل احتمال في وزنه الخاص وتجمع الناتج للحصول على النتيجة النهائية.
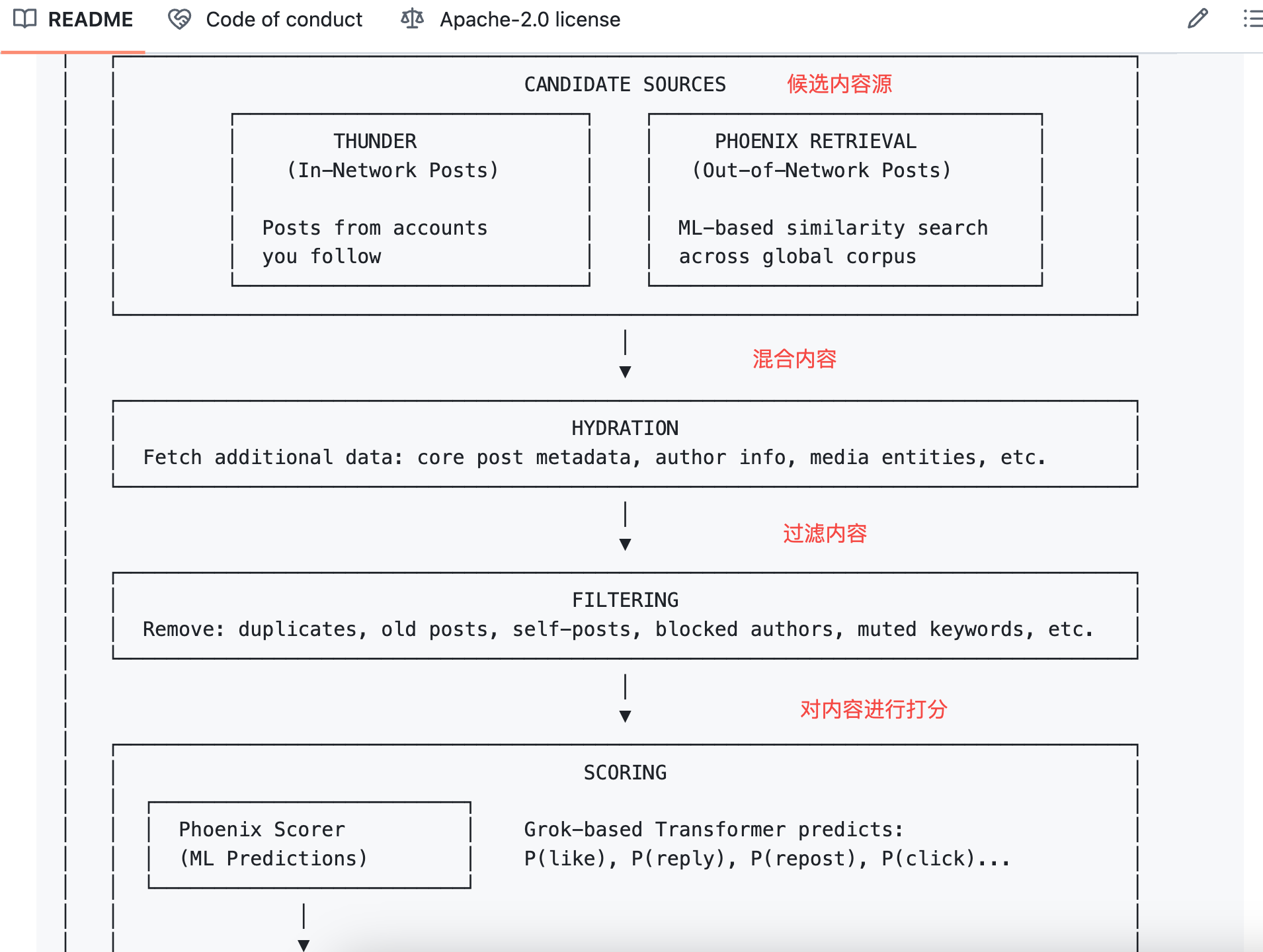
الصيغة كالآتي:
النتيجة النهائية = Σ (الوزن × P(الإجراء))
الإجراءات الإيجابية لها أوزان موجبة، والسلبية أوزان سالبة.
المنشورات الأعلى نتيجةً تظهر في الترتيب الأعلى، أما المنشورات ذات النتائج المنخفضة فتنخفض في الترتيب.
عمليًا، لم يعد تقييم جودة المحتوى يعتمد فقط على جودته الداخلية (مع بقاء قابلية القراءة والقيمة شرطين أساسيين للمشاركة)، بل أصبح يعتمد على "ردود الفعل التي يثيرها محتواك". الخوارزمية لا تهتم بالمحتوى ذاته، بل بسلوك المستخدمين.
وبهذه الآلية، قد يحصل منشور منخفض الجودة يثير الكثير من الردود على نتيجة أعلى من منشور عالي الجودة بلا تفاعل. قد يكون هذا هو المنطق الأساسي للنظام.
مع ذلك، الخوارزمية الجديدة مفتوحة المصدر لا تكشف عن الأوزان الدقيقة لكل سلوك، بينما نسخة 2023 كانت تفعل ذلك.
مرجع النسخة القديمة: إبلاغ واحد = 738 إعجابًا
لنستعرض بيانات 2023. رغم أنها قديمة، لكنها توضح كيف تقيم الخوارزمية كل إجراء.
في 5 أبريل 2023، نشرت X علنًا بيانات الأوزان على GitHub.
فيما يلي الأرقام:
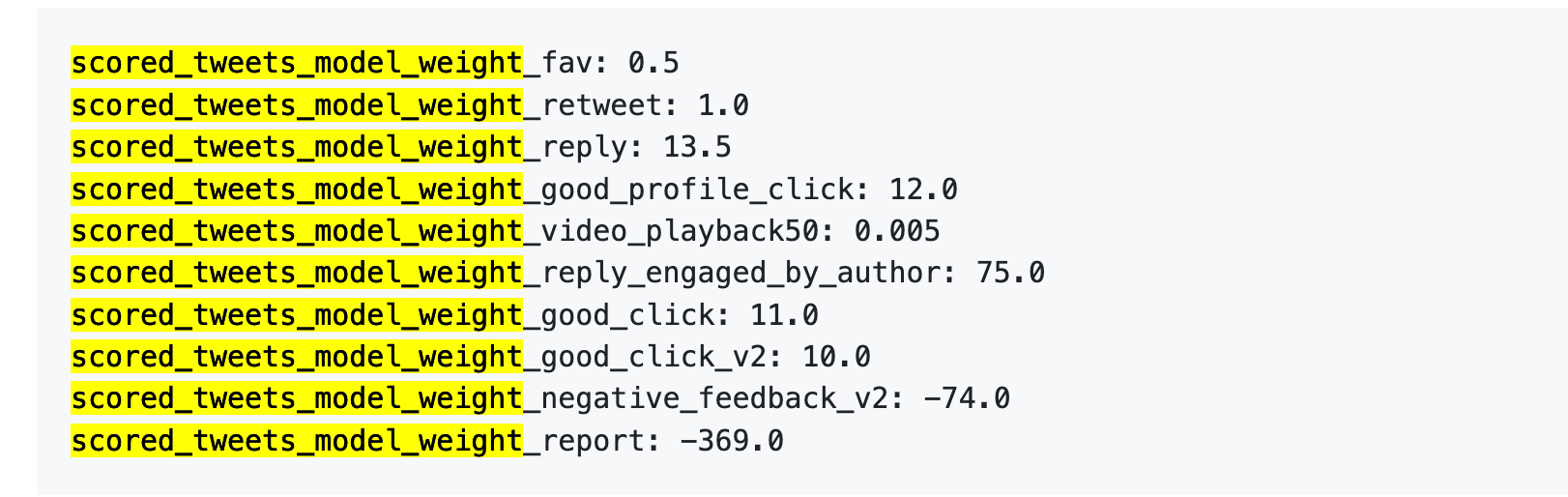
لتبسيط الفكرة:
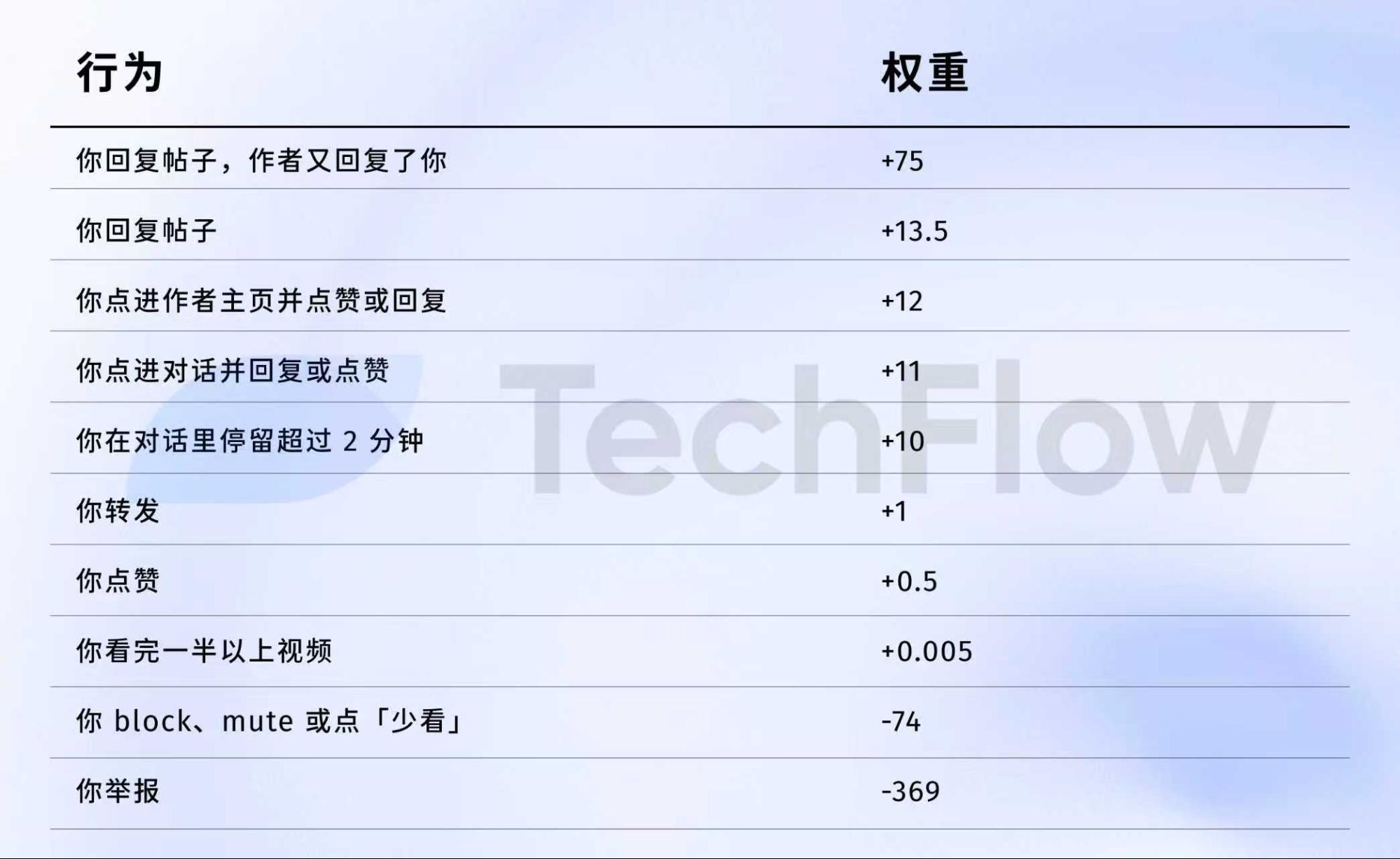
مصدر البيانات: النسخة القديمة من مستودع GitHub twitter/the-algorithm-ml. اضغط هنا للاطلاع على الخوارزمية الأصلية.
هناك عدة نقاط بارزة:
أولًا، الإعجابات شبه معدومة القيمة. وزنها فقط 0.5، وهو الأدنى بين الإجراءات الإيجابية. الخوارزمية تعتبر الإعجاب بلا قيمة تقريبًا.
ثانيًا، المحادثة هي الأهم. "ترد على تعليق فيرد الكاتب عليك" وزنها 75—أي أعلى بـ 150 مرة من الإعجاب. الخوارزمية تعطي أولوية كبيرة للحوار المتبادل مقارنة بالإعجابات العادية.
ثالثًا، التعليقات السلبية تحمل عقوبات كبيرة. الحظر أو الكتم الواحد (-74) يحتاج 148 إعجابًا لمعادلة أثره. الإبلاغ الواحد (-369) يتطلب 738 إعجابًا. هذه النتائج السلبية تتراكم في سمعة حسابك وتؤثر على توزيع منشوراتك القادمة.
رابعًا، معدل إكمال الفيديو له وزن ضئيل جدًا—فقط 0.005، يكاد لا يُذكر. وهذا يختلف كثيرًا عن منصات مثل TikTok التي تعتبر معدل الإكمال معيارًا أساسيًا.
كما توضح الوثيقة الرسمية: "يمكن تعديل الأوزان في أي وقت... ومنذ ذلك الحين، نقوم بتعديلها دوريًا لتحسين مؤشرات المنصة."
الأوزان قابلة للتغيير في أي وقت، وهذا ما حدث فعلاً.
الإصدار الجديد لا يفصح عن القيم المحددة، لكن الإطار المنطقي في README هو نفسه: الإجراءات الإيجابية تضيف نقاطًا، والسلبية تخصم، والنتيجة النهائية هي مجموع الأوزان.
قد تتغير القيم الفعلية، لكن ترتيب الأهمية على الأرجح لم يتغير. الرد على تعليق شخص أهم من مئة إعجاب. الحظر أسوأ من عدم التفاعل إطلاقًا.
كيف يستفيد صناع المحتوى من هذه المعلومات؟
بعد مراجعة شيفرة خوارزمية Twitter الجديدة والقديمة، إليك بعض التوصيات العملية:
1. رد دائمًا على تعليقات متابعيك. في جدول الأوزان، "رد الكاتب على المعلق" هو أعلى إجراء من حيث النقاط (+75)، أي 150 مرة أكثر قيمة من الإعجاب. لست بحاجة لطلب التعليقات، لكن دائمًا رد إذا علق أحد—even كلمة "شكرًا" تُحتسب في الخوارزمية.
2. تجنب إثارة رغبة المستخدمين في حظرك. الحظر الواحد يتطلب 148 إعجابًا لمعادلة أثره. قد يجذب الجدل تفاعلًا، لكن إذا كان التفاعل سلبيًا ("هذا الشخص مزعج، احذفه")، ستتأثر سمعة حسابك على المدى الطويل، ما يؤثر على انتشار منشوراتك. الجدل سلاح ذو حدين—فكر قبل أن تثيره.
3. ضع الروابط الخارجية في التعليقات. الخوارزمية لا ترغب بخروج المستخدمين من المنصة. وضع الروابط في النص الرئيسي سيؤدي إلى تقليل الوصول—وقد أكد ماسك ذلك علنًا. إذا رغبت في توجيه حركة المرور، ضع المحتوى الرئيسي في المنشور والرابط في أول تعليق.
4. لا تكرر النشر بشكل مزعج. الشيفرة الجديدة تتضمن Author Diversity Scorer، الذي يعاقب على المنشورات المتتالية من نفس الكاتب. الهدف تنويع محتوى تغذية المستخدمين، لذا من الأفضل نشر محتوى واحد عالي الجودة بدلًا من سلسلة منشورات متتالية.
6. لم يعد هناك "أفضل توقيت للنشر". الخوارزمية القديمة اعتمدت "وقت النشر" كميزة يدوية، لكن Phoenix أزالها. Phoenix يركز فقط على سلوك المستخدم وليس توقيت النشر. لذا، استراتيجيات "الثلاثاء الساعة 3 مساءً" لم تعد فعالة.
هذه هي الخلاصات المستخلصة من الشيفرة.
هناك أيضًا قواعد مكافآت وعقوبات في وثائق X العامة لم تُدرج في هذا الإصدار مفتوح المصدر: التحقق بالشارة الزرقاء يزيد الوصول، المنشورات المكتوبة بأحرف كبيرة كلها تُعاقب، والمحتوى الحساس يؤدي إلى تقليل الوصول بنسبة %80. هذه القواعد ليست مفتوحة المصدر، لذا لم يتم تناولها هنا.
عمومًا، هذا الإصدار المفتوح المصدر شامل ومهم.
يتضمن بنية النظام الكاملة، منطق استدعاء المحتوى، عملية التقييم والترتيب، وعدة عوامل تصفية. الشيفرة مكتوبة أساسًا بلغة Rust وPython، وبنية واضحة وREADME أكثر تفصيلًا من كثير من المشاريع التجارية.
مع ذلك، هناك عناصر أساسية مفقودة.
1. معايير الأوزان ليست معلنة. الشيفرة توضح فقط أن "الإجراءات الإيجابية تضيف نقاطًا والسلبية تخصم"، لكنها لا تحدد قيمة الإعجاب أو الحظر. نسخة 2023 كشفت عن الأرقام؛ أما الآن، فالإطار فقط متاح.
2. أوزان النموذج غير معلنة. Phoenix يستخدم محول Grok، لكن معايير النموذج غير متاحة. يمكنك رؤية كيفية استدعاء النموذج، لكن ليس طريقة عمله الداخلية.
3. بيانات التدريب غير متاحة. لا يوجد وضوح حول نوعية البيانات المستخدمة لتدريب النموذج أو كيفية اختيار سلوكيات المستخدمين أو بناء العينات الإيجابية والسلبية.
بمعنى آخر، هذا الإصدار المفتوح المصدر يوضح "نستخدم مجموع الأوزان لحساب النتائج"، لكنه لا يذكر الأوزان الفعلية؛ ويذكر "نستخدم المحولات لتوقع احتمالات السلوك"، لكنه لا يكشف عن تفاصيل المحول الداخلية.
بالمقارنة، لم تنشر TikTok وInstagram حتى هذا القدر من التفاصيل. إصدار X مفتوح المصدر بالفعل أكثر شمولًا من المنصات الكبرى الأخرى، لكنه لا يزال غير شفاف بالكامل.
مع ذلك، فإن إتاحة الشيفرة أمر ذو قيمة. لصناع المحتوى والباحثين، القدرة على مراجعة الشيفرة أفضل من عدم إتاحتها نهائيًا.
بيان:
- تمت إعادة نشر هذه المقالة من [TechFlow]، وتعود حقوق النشر للمؤلف الأصلي [David]. إذا كان لديك أي استفسار بخصوص إعادة النشر هذه، يرجى التواصل مع فريق Gate Learn، وسيتم التعامل معه فورًا وفق الإجراءات المعتمدة.
- إخلاء مسؤولية: جميع الآراء الواردة في هذه المقالة تعبر عن رأي الكاتب فقط ولا تشكل نصيحة استثمارية.
- تمت ترجمة النسخ اللغوية الأخرى من هذه المقالة بواسطة فريق Gate Learn. ما لم يُذكر صراحة Gate، يُحظر نسخ أو توزيع أو سرقة المقالة المترجمة.








