باختصار
- أطلقت OpenAI GPT-5.4 وسط تزايد ردود الفعل السلبية على QuitGPT بسبب عقد الذكاء الاصطناعي مع البنتاغون.
- يضيف GPT-5.4 نافذة سياق من مليون رمز، وقدرات تفكير أقوى، وميزات وكيلة.
- يستفيد المستخدمون المؤسساتيون بشكل أكبر حيث يوفر GPT-5.4 وكلاء ذكاء اصطناعي أسرع مع رموز أقل.
بدأت OpenAI في طرح GPT-5.4—أكثر نماذجها قدرة حتى الآن—يوم الخميس، في وقت تكافح فيه الشركة لاحتواء أزمة علاقات عامة أدت إلى اتخاذ حوالي 2.5 مليون مستخدم إجراءات ضد الشركة، إما بإلغاء اشتراكهم أو بمشاركة حملة المقاطعة على وسائل التواصل الاجتماعي.
انفجر ما يُعرف بحركة QuitGPT بعد أن كشفت OpenAI عن صفقة مع وزارة الدفاع الأمريكية بعد ساعات من انسحاب شركة Anthropic علنًا من نفس العقد—مما أكسب صانع Claude سخرية عامة من الرئيس ترامب ومسؤولين حكوميين آخرين.
نقطة الخلاف مع Anthropic: رفضت وزارة الدفاع الأمريكية تضمين لغة تمنع صراحة نشر الأسلحة الذاتية والاستخدام الواسع للمراقبة على المواطنين الأمريكيين.
مع ذلك، قبلت OpenAI الصفقة. يحتاج الرئيس التنفيذي سام ألتمان، الذي يتلقى أسئلة حول الفجوة الظاهرة بين الخطوط الحمراء المعلنة لسلامة شركته ولغة العقد الفعلية، إلى عودة هؤلاء المستخدمين.
وهنا يأتي GPT-5.4… بعد يومين فقط من تقديم GPT-5.3.
يُدمج النموذج الجديد قدرات التفكير، والبرمجة، والوكالة في إصدار واحد. كما يمتلك قدرة سياق بمليون رمز، مما يمنح المستخدمين حرية أكبر في التعامل مع كميات كبيرة من المعلومات في جلسة واحدة.
على الورق، تبدو الأرقام واعدة. على مقياس GDPval—وهو اختبار قياسي لمعرفة مدى قدرة العمل المعرفي عبر 44 مهنة—يتطابق GPT-5.4 أو يتفوق على المحترفين في 83.0% من المقارنات، مرتفعًا من 70.9% لـ GPT-5.2. أكبر قفزة كانت في استخدام الحاسوب: على OSWorld-Verified، الذي يقيس قدرة النموذج على تشغيل سطح المكتب عبر لقطات الشاشة وإجراءات لوحة المفاتيح/الفأرة، حقق GPT-5.4 معدل نجاح بنسبة 75.0% مقابل 47.3% لـ GPT-5.2—وتجاوز الحد الأدنى البشري البالغ 72.4%.
وفي اختبار BrowseComp، وهو اختبار للبحث في الويب العميق، قفز بنسبة 17 نقطة مئوية عن GPT-5.2. وتكتمل الميزات الرئيسية بوجود نافذة سياق من مليون رمز وميزة توجيه أثناء الاستجابة—تسمح للمستخدمين بإعادة توجيه النموذج أثناء تفكيره—وهي ميزة توفر الوقت والحسابات بعدم الحاجة إلى التخلص من جميع الرموز التي تم إنشاؤها سابقًا عند اكتشاف خطأ.
من سيستفيد من GPT 5.4؟
من المهم ملاحظة أن بعض المقاييس تقارن بشكل رئيسي بين GPT-5.4—وغالبًا ما يكون التفكير مضبوطًا على جهد عالي جدًا، وهو ما لا يستمتع به مستخدمو النسختين المجانية وPlus—وGPT-5.2، متجاوزين GPT-5.3 تمامًا.
بالنسبة للمستخدمين الذين يستخدمون بالفعل GPT-5.3، قد تبدو بعض المكاسب أكثر تدريجيًا مما تظهره الرسوم البيانية.
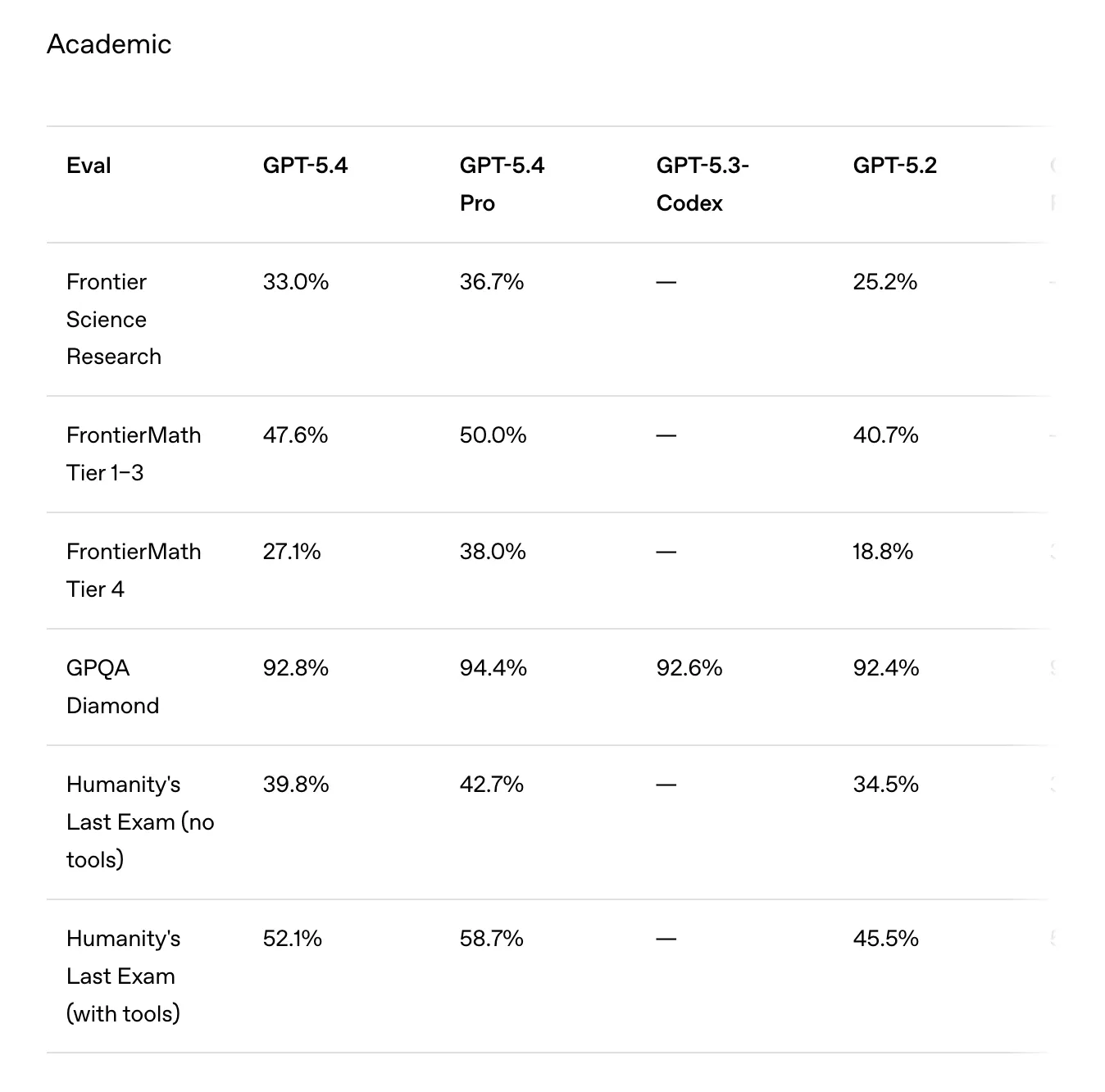
المبرمجون لديهم أكبر سبب لتهدئة التوقعات: على SWE-Bench Pro، التحسن من GPT-5.3-Codex (56.8%) إلى GPT-5.4 (57.7%) يكاد يكون فرقًا في التقريب. كما يدعي النموذج أنه يتطلب رموزًا أقل بشكل كبير لإنجاز المهام مقارنة بـ GPT-5.2.
قالت OpenAI: “GPT‑5.4 هو أكثر نماذجنا كفاءة في استخدام الرموز حتى الآن، حيث يستخدم رموزًا أقل بكثير لحل المشكلات مقارنة بـ GPT‑5.2”.
ومع ذلك، فإن أي تحسين في هذا المجال هو أمر إيجابي للمطورين الذين يستخدمون نماذج OpenAI عبر API ويتقاضون رسومًا مقابل كل رمز يُستخدم. قد يوفر نموذج ذو سلسلة تفكير فعالة نفس النتائج بتكلفة أقل بكثير، مقارنة بنموذج يميل إلى الإفراط في التفكير لضمان الوصول إلى الاستنتاج الصحيح.
هناك مشكلة أخرى لأي شخص يأمل في استخدام النموذج الجديد الآن: تقول OpenAI إن GPT-5.4 سيتم إصداره اليوم، لكنه لم يكن متاحًا بعد عند كتابة هذا، لذلك من المحتمل أنه يتم طرحه تدريجيًا. بالنسبة لمعظم المستخدمين، أفضل نموذج هو GPT 5.3، ويمكن استخدامه فقط للردود الفورية، مما يعني أنه يقدم إجابات لا تتطلب جهدًا كبيرًا.
المستخدمون الذين يعتمدون على التفكير—وهو مصطلح OpenAI للمنطق الممتد على طول سلسلة من الأفكار في المهام المعقدة—لا زالوا على GPT-5.2. بمعنى آخر، المستخدمون الأكثر احتمالًا لدفع حدود النموذج هم آخر من يحصل عليه.
أوضح المستفيدين هم المستخدمون المؤسساتيون الذين يقومون بأعمال تعتمد بشكل كبير على المستندات. على مقياس نمذجة جداول البيانات الداخلية، حقق GPT-5.4 نسبة 87.3% مقابل 68.4% لـ GPT-5.2. قالت شركة الأبحاث القانونية Harvey إنها حققت 91% في تقييم BigLaw Bench. شركة Mainstay، التي تدير وكلاء عبر 30,000 بوابة ضرائب عقارية، أبلغت عن معدل نجاح أول محاولة بنسبة 95% وجلسات تعمل بسرعة ~3 أضعاف مع استخدام ~70% رموز أقل.
هذا النوع من الحجة حول الكفاءة قد يهم فرق الشراء في المؤسسات—لكنها أصعب إقناع للمستخدم الفردي الذي يعيد النظر في حذف حسابه.
إخلاء المسؤولية: قد تكون المعلومات الواردة في هذه الصفحة من مصادر خارجية ولا تمثل آراء أو مواقف Gate. المحتوى المعروض في هذه الصفحة هو لأغراض مرجعية فقط ولا يشكّل أي نصيحة مالية أو استثمارية أو قانونية. لا تضمن Gate دقة أو اكتمال المعلومات، ولا تتحمّل أي مسؤولية عن أي خسائر ناتجة عن استخدام هذه المعلومات. تنطوي الاستثمارات في الأصول الافتراضية على مخاطر عالية وتخضع لتقلبات سعرية كبيرة. قد تخسر كامل رأس المال المستثمر. يرجى فهم المخاطر ذات الصلة فهمًا كاملًا واتخاذ قرارات مدروسة بناءً على وضعك المالي وقدرتك على تحمّل المخاطر. للتفاصيل، يرجى الرجوع إلى
إخلاء المسؤولية.

