Introduction : pourquoi l’IA remet le stockage au cœur de l’infrastructure crypto

Source de l’image : Gate Market Page
À l’horizon 2026, les coûts du stockage et du trafic sortant — qu’ils concernent le cloud ou l’auto-hébergement — poursuivent leur progression. Face à l’explosion des ensembles de données d’entraînement IA, des bases de données vectorielles et des journaux d’inférence, le « prix unitaire par Go » et les « frais de synchronisation interrégionale » redeviennent centraux dans les rapports hebdomadaires des directions financières et des responsables d’infrastructure. Sur cette période, le sentiment du marché se montre particulièrement réactif à l’« offre alternative » : les actifs de stockage décentralisé tels que STORJ enregistrent des hausses marquées à court terme, transformant des problématiques structurelles anciennes en véritables hotspots de trading. Mais la question fondamentale ne porte pas sur la volatilité quotidienne des prix : alors que les entreprises paient plus cher pour conserver durablement modèles et Agents, pourquoi le marché oriente-t-il ses attentes vers des solutions de stockage on-chain, vérifiables ou reposant sur DePIN ?
Il convient de clarifier que le « stockage » dans l’univers crypto ne désigne pas un produit unique. Il peut s’agir d’archivage web permanent et de modèles de sécurité économique, de stockage d’objets quasi temps réel avec gestion hot-cold, ou simplement d’un module au sein d’une stack (aux côtés des marchés de taux de hachage et de la Data Availability, DA). Les sections suivantes classent les projets et feuilles de route selon la typologie des enjeux, évitant d’amalgamer différentes couches technologiques dans un seul récit « token de stockage » et dissociant la volatilité des prix de critères comme la disponibilité, le SLA, la conformité ou le TCO à long terme.
Avant d’aborder les projets, appuyez-vous sur le cadre de réflexion par couches suivant :
-
Gel de version pour les données d’entraînement et d’évaluation
- L’immutabilité longue durée et l’auditabilité publique via une chaîne de temps sont-elles requises ?
- Un coût d’écriture ponctuel plus élevé est-il acceptable pour minimiser le risque de litige ultérieur ?
-
Gestion du cycle de vie des poids de modèles et résultats intermédiaires
- Privilégie-t-on l’archivage/sauvegarde (lectures peu fréquentes) ou le chargement en ligne pour l’inférence (latence critique) ?
- Un contrôle contractuel on-chain pour les renouvellements, listes blanches d’accès et règlements est-il nécessaire ?
-
État des Agents et des sessions
- Un contrôle d’autorisation programmable est-il requis (par appelant, tâche ou fenêtre temporelle) ?
- Pour des mises à jour d’état fréquentes, les couches KV ou mutables sont souvent plus efficaces que les blobs permanents.
-
Approvisionnement et conformité entreprise
- Les acheteurs questionnent souvent le SLA, la région, le chiffrement, la gestion des clés, les formats de preuve vérifiable et la facturation du trafic sortant.
- Les solutions décentralisées qui se limitent au nombre de nœuds sans SLO mesurables peineront à convaincre les entreprises.
Ces quatre dimensions orientent l’analyse vers des couches permanentes type Arweave, des clouds vérifiables à la Filecoin Onchain Cloud, du stockage d’objets programmable tel Walrus/Akave, ou des modules full-stack comme 0G, qui intègrent le stockage à une architecture de chaîne IA-native.
Comparaison des routes techniques : possession vérifiable, stockage permanent, compatibilité objet et DePIN full-stack
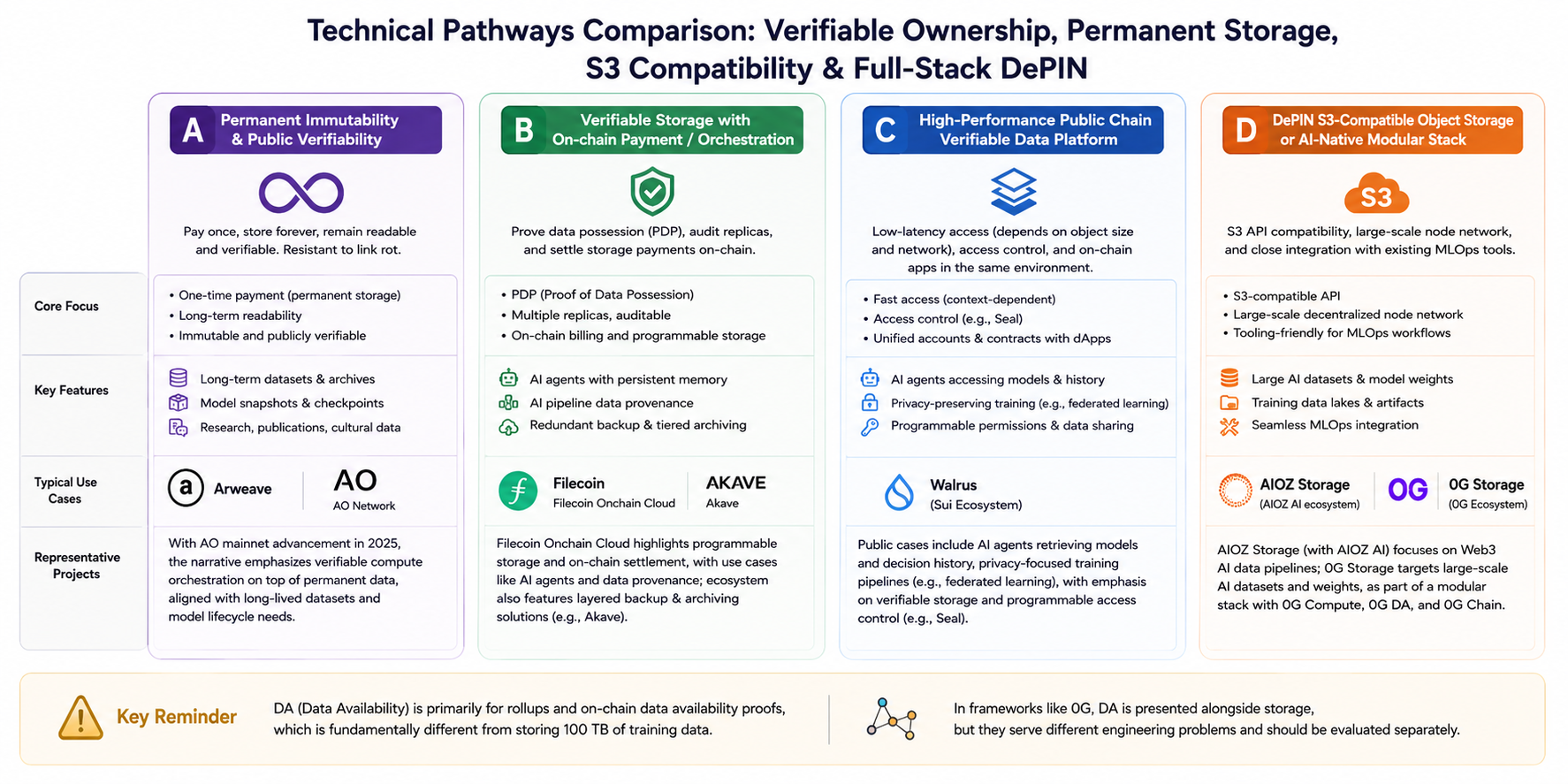
Pour une vision comparative, ces routes se déclinent en quatre catégories principales (avec des recouvrements mais des axes narratifs distincts) :
Route A : immutabilité permanente et reproductibilité publique
- Mots-clés : paiement unique, lisibilité durable, lutte contre la disparition des liens.
- Exemple : Arweave. Après le lancement du mainnet AO en 2025, la feuille de route met l’accent sur l’orchestration de calculs vérifiables sur des données permanentes, répondant aux besoins d’alignement de snapshots de modèles et datasets sur le long terme.
Route B : stockage vérifiable avec orchestration de paiement/contrat on-chain
- Mots-clés : PDP (Proof of Data Possession), audit multi-répliques, facturation on-chain.
- Exemple : Filecoin Onchain Cloud. La documentation officielle met en avant le stockage programmable et le règlement on-chain, avec des scénarios comme le stockage persistant géré par Agent IA et la traçabilité des données dans les pipelines IA. L’écosystème propose aussi des solutions de sauvegarde et d’archivage en couches, telles qu’Akave.
Route C : plateformes de données vérifiables sur chaînes publiques haute performance
- Mots-clés : lecture à faible latence (selon la taille de l’objet et le réseau), contrôle d’accès (ex : Seal), comptes unifiés et contrats avec applications on-chain.
- Exemple : Walrus (écosystème Sui). Les cas d’usage couvrent le stockage de modèles d’Agents IA et d’historiques de décisions, des parcours d’entraînement confidentiels (federated learning), avec une priorité sur les permissions vérifiables et programmables.
Route D : stockage d’objets compatible S3 propulsé par DePIN ou composant modulaire IA-native
- Mots-clés : API S3, échelle du réseau de nœuds, intégration fluide avec les outils MLOps existants.
- Exemples : AIOZ Storage (associé à AIOZ AI dans le pipeline de données Web3 IA) ; 0G Storage dans la documentation 0G, présenté comme la couche de stockage pour grands ensembles de données IA et poids de modèles, formant une stack modulaire avec 0G Compute, 0G DA et 0G Chain.
À noter : la DA (Data Availability) cible principalement les rollups et les preuves de disponibilité on-chain. Stocker « 100 To de données d’entraînement » relève d’un autre défi technique ; cependant, dans un framework full-stack comme 0G, DA et stockage sont présentés ensemble mais doivent être évalués séparément.
Panorama des projets représentatifs (classés par route)
Les projets suivants s’appuient sur des feuilles de route publiques et des blogs officiels, sans classement par capitalisation ou performance de token, et ne constituent pas un conseil en investissement.
Couche permanente : Arweave et écosystème AO
- Positionnement : dédié à la permaweb et à la lisibilité à long terme, idéal pour les snapshots de modèles/datasets, la science ouverte et la publication résistante à la censure.
- Intégration IA : met l’accent sur la traçabilité et la reproductibilité plutôt que sur la garantie de lectures à faible latence.
- Points d’évaluation : économie d’écriture, disponibilité des gateways, dépendance éventuelle à des fournisseurs spécifiques pour la lecture.
Cloud vérifiable : Filecoin Onchain Cloud et solutions de couche supérieure comme Akave
- Positionnement : industrialise la possession vérifiable, les stratégies de réplique et le paiement on-chain pour la sauvegarde, l’archivage conformité et les pipelines auditables en entreprise.
- Intégration IA : la documentation met en avant l’automatisation par Agent pour le stockage et la traçabilité dans les pipelines IA.
- Points d’évaluation : échelle des datasets et cas clients, coût d’intégration des outils de preuve, performance interrégionale.
Plateforme de données vérifiable : Walrus
- Positionnement : conçu pour la vérifiabilité, la programmabilité et le contrôle de la confidentialité (ex : Seal), fortement intégré à l’écosystème Sui.
- Intégration IA : partenariats couvrant le cycle de vie des données Agent et la formation collaborative confidentielle.
- Points d’évaluation : latence selon la taille de l’objet, limites du chiffrement et de la gestion des clés, profondeur d’intégration.
Stockage d’objets DePIN : AIOZ Storage et autres
- Positionnement : compatible S3, met l’accent sur l’échelle du réseau de nœuds et la migration sans friction.
- Intégration IA : en phase avec les pratiques d’ingénierie telles que l’hébergement de datasets et la distribution d’artefacts.
- Points d’évaluation : la comparaison de coûts avec le cloud centralisé exige les mêmes hypothèses de région, de niveau hot/cold et de trafic sortant.
Full-stack modulaire : 0G
- Positionnement : intègre stockage, taux de hachage, DA et chaîne comme modules sous la vision unifiée deAIOS/AI L1.
- Intégration IA : la documentation met en avant la haute performance, une couche de stockage pour poids et logs, et une couche KV pour embeddings et état Agent.
- Points d’évaluation : la maturité de chaque module répond-elle au principal goulet d’étranglement (souvent le taux de hachage ou la gestion des données) ?
Autres projets fréquemment cités mais non axés stockage
- Exemple : Fluence et autres projets GPU/taux de hachage décentralisé : souvent cités dans les discussions « IA + DePIN », mais à ne pas assimiler à une infrastructure de stockage sauf offre explicite de SLA de stockage d’objets à grande échelle.
Même avec des narratifs alignés IA, trois contraintes majeures subsistent pour le déploiement :
-
Contraintes d’ingénierie : latence, cohérence, chaînes d’outils
- Les systèmes distribués requièrent souvent des middlewares additionnels pour la gestion des petits fichiers, le haut QPS, la synchronisation interrégionale et les uploads reprenables.
- La décentralisation n’implique pas automatiquement un coût inférieur : le coût total de possession (TCO) pour l’archivage à froid et les lectures à chaud doit être comparé.
-
Contraintes du modèle économique : incitations token et paiement effectif
- De nombreux réseaux incitent à la fois les mineurs/nœuds et les utilisateurs finaux.
- La volatilité du prix du token affecte la rétention des fournisseurs, impactant disponibilité et qualité de service à long terme.
-
Conformité et gouvernance des données : gestion des clés, transfrontalier, droits d’auteur
- Les datasets IA impliquent souvent droits d’auteur et données personnelles ; la vérifiabilité on-chain ne règle pas à elle seule la légalité de la source.
- Les clients entreprises exigeront la gestion des clés, le droit à l’effacement et la localisation des données : une tension existe entre stockage permanent et « droit à l’oubli », qui impose une coordination produit/juridique.
Conclusion : aligner attentes et cas d’usage, s’appuyer sur des preuves, non des slogans
Le récit « IA + Stockage » s’impose, mais l’utilité réelle dépend de la clarification des workloads : archivage à froid ou lecture à chaud ; SLO de débit et latence ; modalités de gestion des clés et conformité ; et alignement des incitations token sur les paiements effectifs. Les quatre routes (couche permanente, cloud vérifiable, stockage d’objets on-chain, stockage modulaire full-stack) peuvent coexister mais ne sont pas interchangeables : la couche permanente garantit cohérence longue durée et relecture publique ; les clouds vérifiables excellent en orchestration et facturation ; les solutions S3-compatibles facilitent la migration ; les approches full-stack offrent une vision intégrée mais nécessitent de valider la maturité de chaque module.
Le filtre final est simple : vérifier si l’usage vérifiable et les cas clients soutiennent le récit ; comparer TCO et latence sur une base équivalente ; enfin, aborder tokens et valorisation. Cette démarche limite les confusions, comme assimiler la DA à un « entrepôt de corpus » ou les projets de taux de hachage à de l’infrastructure de stockage.
Avertissement : cet article compile des informations techniques et sectorielles et ne constitue en aucun cas un conseil en investissement. Les détails relatifs aux phases de mainnet, partenaires et métriques de performance peuvent évoluer selon les mises à jour officielles. Veuillez toujours consulter les derniers livres blancs, documentations et rapports d’audit publiés par les équipes projets.







