Le 20 janvier après-midi, X a publié en open source son dernier algorithme de recommandation.
Musk a déclaré : « Nous savons que cet algorithme est limité et nécessite encore des améliorations majeures, mais au moins vous pouvez constater nos efforts d’amélioration en temps réel. Les autres plateformes sociales n’oseraient pas s’y risquer. »
Son propos s’articule autour de deux axes : il reconnaît les faiblesses de l’algorithme et met en avant la transparence comme argument principal.
Il s’agit de la deuxième publication open source de l’algorithme par X. La version 2023 n’avait pas été mise à jour depuis trois ans et n’était plus connectée au système de production. Cette fois, la base de code a été entièrement réécrite. Le modèle central est passé de l’apprentissage automatique classique au Grok transformer. D’après la documentation officielle, « l’ingénierie manuelle des caractéristiques a été totalement supprimée ».
Concrètement, l’algorithme précédent reposait sur l’ajustement manuel de paramètres par des ingénieurs. Désormais, l’IA analyse directement l’historique de vos interactions pour déterminer si votre contenu doit être mis en avant.
Pour les créateurs de contenu, cela implique que les stratégies telles que « horaires optimaux de publication » ou « tags qui font grandir la communauté » pourraient perdre de leur efficacité.
Nous avons également consulté le dépôt GitHub open source et, avec l’aide de l’IA, identifié certaines logiques codées en dur qui méritent d’être examinées.
Mutation de la logique algorithmique : des règles manuelles à l’IA décisionnelle
Commençons par clarifier les différences entre l’ancienne et la nouvelle version afin d’éviter toute confusion dans l’analyse.
En 2023, l’algorithme open source de Twitter, Heavy Ranker, reposait sur l’apprentissage automatique traditionnel. Les ingénieurs définissaient manuellement des centaines de caractéristiques : présence d’images, nombre d’abonnés de l’auteur, ancienneté du post, liens, etc.
Chaque caractéristique se voyait attribuer un poids, ajusté en continu pour optimiser la combinaison.
La nouvelle version, Phoenix, propose une architecture radicalement différente : elle s’appuie sur des modèles d’IA de grande taille. Le cœur du système utilise le Grok transformer, technologie similaire à ChatGPT et Claude.
Le README officiel précise : « Toutes les caractéristiques conçues à la main ont été supprimées. »
Le système basé sur des règles et des caractéristiques extraites manuellement a donc disparu.
Sur quels critères l’algorithme évalue-t-il la qualité du contenu ?
La réponse : votre séquence comportementale. Ce que vous aimez, à qui vous répondez, les posts sur lesquels vous restez plus de deux minutes, les types de comptes que vous bloquez. Phoenix transmet ces comportements au transformer, qui apprend et synthétise les schémas.
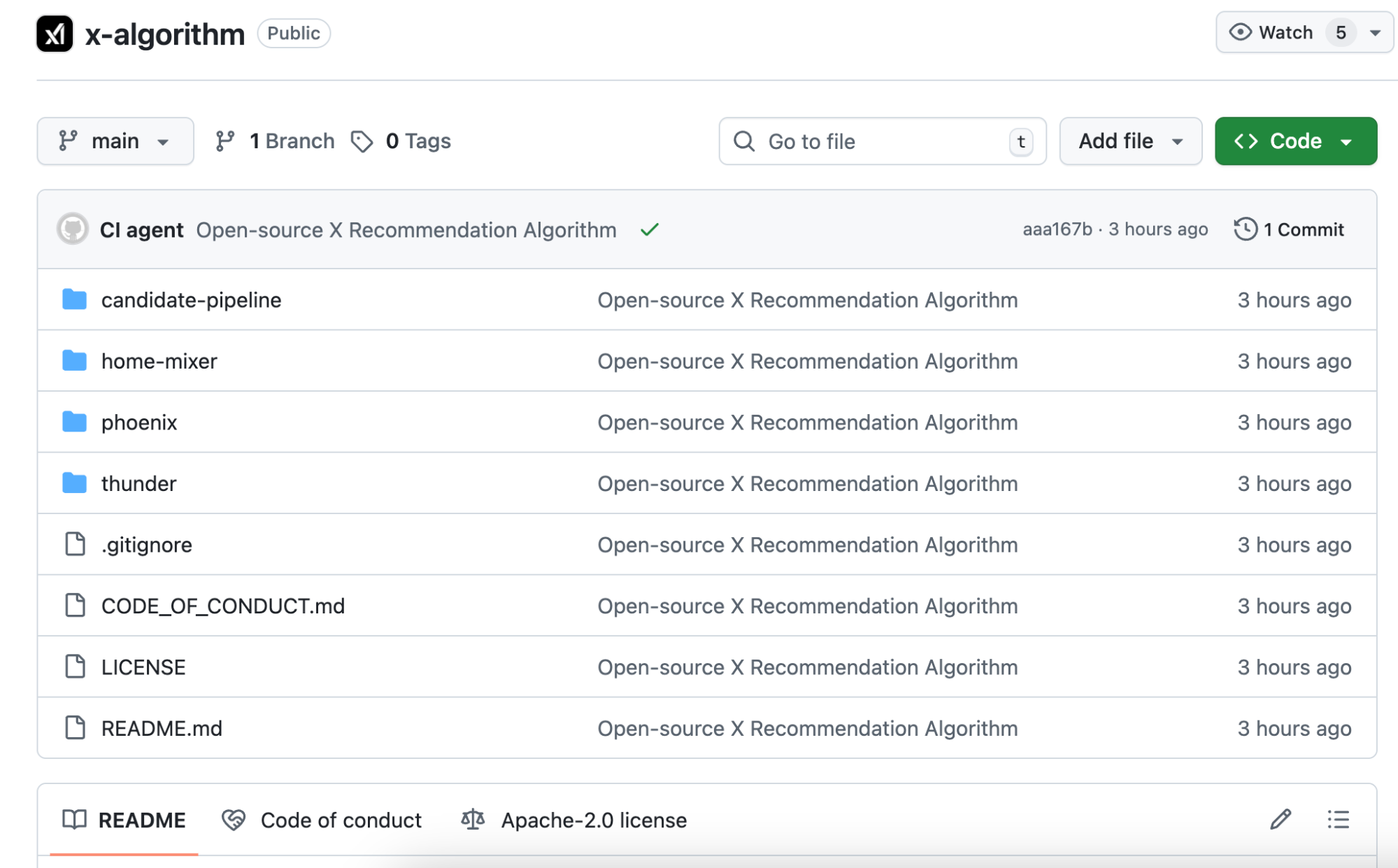
Pour illustrer : l’ancien algorithme fonctionnait comme une grille de notation manuelle, attribuant des points pour chaque critère rempli.
Le nouvel algorithme s’apparente à une IA ayant accès à l’ensemble de votre historique de navigation pour anticiper ce que vous souhaitez voir.
Pour les créateurs, deux conséquences :
Premièrement, les tactiques comme « meilleurs horaires de publication » ou « tags stratégiques » ont désormais moins d’importance. Le modèle ne s’appuie plus sur des caractéristiques fixes, mais sur les préférences individuelles de chaque utilisateur.
Deuxièmement, la promotion de votre contenu dépend principalement de « la façon dont les utilisateurs réagissent à votre contenu ». Ces réactions sont quantifiées en 15 types de prédictions comportementales, détaillées ci-après.
L’algorithme prédit 15 types de réactions utilisateur
Lorsqu’il évalue un post, Phoenix anticipe 15 actions possibles de l’utilisateur :
- Actions positives : aimer, répondre, repartager, repartager avec citation, cliquer sur le post, cliquer sur le profil de l’auteur, regarder plus de la moitié d’une vidéo, agrandir une image, partager, rester un certain temps, suivre l’auteur
- Actions négatives : sélectionner « pas intéressé », bloquer l’auteur, masquer l’auteur, signaler
Chaque action se voit attribuer une probabilité prédite. Par exemple, le modèle estime à 60% la probabilité que vous aimiez un post et à 5% celle que vous bloquiez l’auteur.
L’algorithme multiplie chaque probabilité par son poids et additionne le tout pour obtenir le score final.
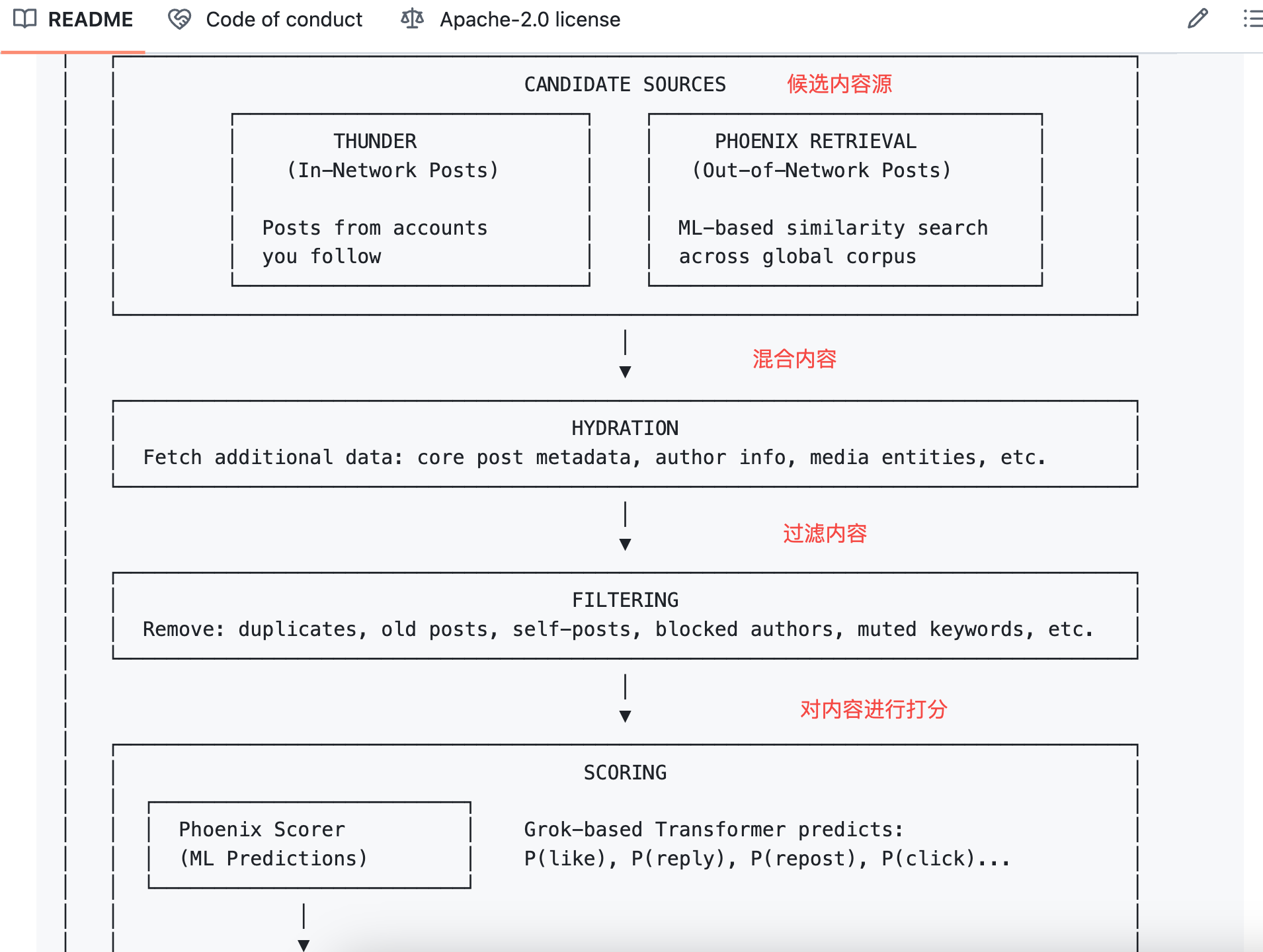
La formule est :
Score final = Σ ( poids × P(action) )
Les actions positives ont des poids positifs ; les négatives, des poids négatifs.
Les posts ayant un score total élevé sont mieux classés ; ceux avec un score faible sont déclassés.
En pratique, la qualité d’un contenu n’est plus déterminée uniquement par ses attributs intrinsèques (même si lisibilité et valeur restent nécessaires pour le partage). Elle dépend surtout « des réactions suscitées ». L’algorithme s’intéresse avant tout au comportement utilisateur.
Selon cette logique, dans certains cas extrêmes, un post de faible qualité qui génère de nombreuses réponses peut obtenir un score supérieur à un post de qualité sans interaction. Cela semble refléter la logique du système.
Cependant, la nouvelle version open source ne révèle pas les poids exacts associés à chaque comportement, contrairement à la version 2023.
Référence ancienne version : un signalement = 738 likes
Examinons les données de 2023. Elles sont datées, mais illustrent la valorisation des différentes actions par l’algorithme.
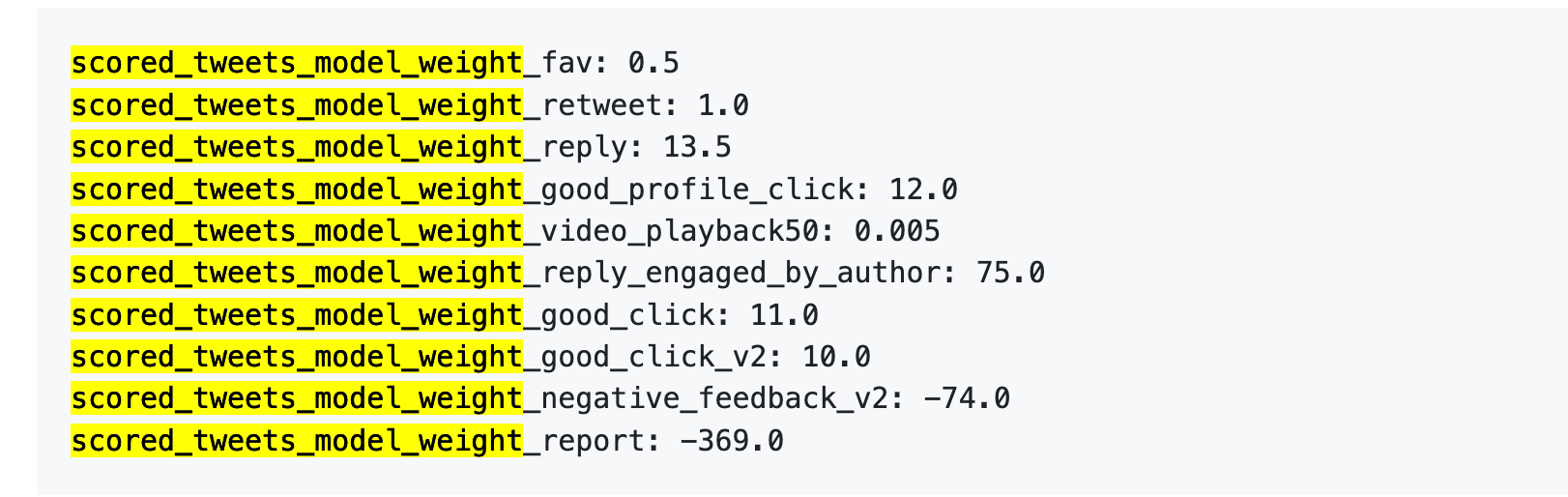
Le 5 avril 2023, X a publié un tableau de poids sur GitHub.
Voici les chiffres :
Pour résumer :
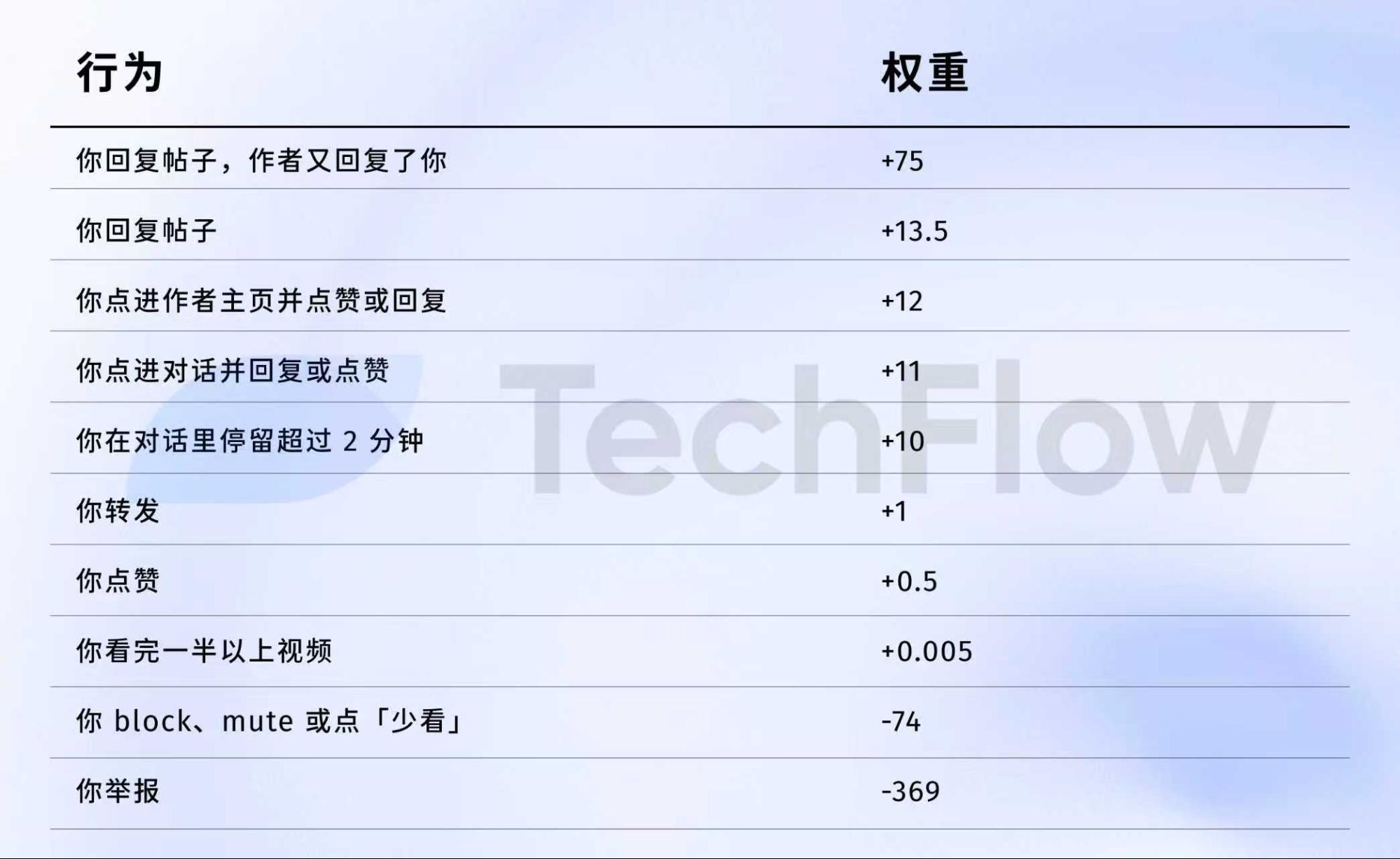
Source des données : ancienne version GitHub twitter/the-algorithm-ml repository. Cliquez pour voir l’algorithme d’origine.
Quelques chiffres clés :
Premièrement, les likes ont une valeur quasi nulle : poids de 0,5, le plus faible parmi les actions positives. L’algorithme considère qu’un like a peu d’impact.
Deuxièmement, la conversation est essentielle. « Vous répondez et l’auteur répond » a un poids de 75 — soit 150 fois plus qu’un like. L’algorithme privilégie nettement les échanges bidirectionnels.
Troisièmement, les retours négatifs sont fortement pénalisés. Un blocage ou masquage (-74) nécessite 148 likes pour compenser. Un signalement (-369) requiert 738 likes. Ces scores négatifs s’accumulent et affectent la réputation du compte ainsi que la diffusion des futurs posts.
Quatrièmement, le taux de complétion des vidéos est très peu pondéré — seulement 0,005, quasiment négligeable. Cela contraste avec des plateformes comme TikTok, où ce taux est un indicateur clé.
La documentation officielle précise : « Les poids exacts du fichier peuvent être ajustés à tout moment… Nous les ajustons périodiquement pour optimiser les métriques de la plateforme. »
Les poids sont donc modifiables à tout moment — et ils l’ont été.
La nouvelle version ne divulgue pas les valeurs précises, mais la logique reste la même : les actions positives ajoutent des points, les négatives en retirent, et le score final est une somme pondérée.
Les chiffres exacts peuvent varier, mais l’ordre de priorité semble inchangé. Répondre à un commentaire vaut plus que 100 likes. Être bloqué est plus préjudiciable que l’absence d’interaction.
Comment les créateurs peuvent-ils exploiter ces informations ?
Après analyse du code des algorithmes Twitter, voici quelques recommandations pratiques :
1. Répondez à vos commentateurs. Dans le tableau des poids, « l’auteur répond au commentateur » est l’action la mieux notée (+75), soit 150 fois plus qu’un like. Il n’est pas nécessaire de solliciter des commentaires, mais il faut toujours répondre à ceux reçus — même un « merci » est pris en compte.
2. Évitez d’inciter les utilisateurs à vous bloquer. Un blocage demande 148 likes pour compenser. Un contenu polémique peut générer de l’engagement, mais si celui-ci consiste à vous bloquer, la réputation de votre compte en sera durablement affectée, impactant la diffusion de vos futurs posts. La controverse est à manier avec précaution.
3. Placez les liens externes dans les commentaires. L’algorithme cherche à retenir les utilisateurs sur la plateforme. Les liens dans le texte principal sont pénalisés — Musk l’a confirmé publiquement. Pour générer du trafic, mettez le contenu principal dans le post et le lien dans le premier commentaire.
4. Ne spammez pas. Le nouveau code intègre un Author Diversity Scorer, qui pénalise les publications consécutives d’un même auteur. L’objectif est de diversifier les fils utilisateurs ; privilégiez la qualité à la quantité.
6. Il n’y a plus de « meilleur moment pour publier ». L’ancien algorithme utilisait l’heure de publication comme critère manuel, mais Phoenix l’a supprimée. Il ne tient compte que du comportement utilisateur, pas du timing. Les stratégies « mardi à 15h » sont donc obsolètes.
Voilà ce qui ressort du code.
Des règles de bonus et de pénalité figurent dans la documentation publique de X mais ne sont pas incluses dans cette publication open source : la vérification par badge bleu augmente la portée, les posts en majuscules sont pénalisés, et le contenu sensible réduit la portée de 80%. Ces règles ne sont pas open source et ne sont donc pas traitées ici.
Globalement, la publication open source est particulièrement riche.
L’architecture complète du système, la logique de rappel des contenus candidats, le processus de scoring et de classement, ainsi que divers filtres sont inclus. Le code, principalement en Rust et Python, est bien structuré et le README plus détaillé que de nombreux projets commerciaux.
Cependant, certains éléments clés sont absents.
1. Les paramètres de poids ne sont pas publics. Le code explique simplement que « les actions positives ajoutent des points, les négatives en retirent », mais sans préciser la valeur d’un like ou d’un blocage. La version 2023 donnait au moins les chiffres ; cette fois, seul le cadre de la formule est disponible.
2. Les poids du modèle ne sont pas publics. Phoenix utilise le Grok transformer, mais les paramètres du modèle ne sont pas inclus. On peut voir comment le modèle est appelé, mais pas son fonctionnement interne.
3. Les données d’entraînement ne sont pas publiques. On ignore quelles données ont servi à entraîner le modèle, comment le comportement utilisateur a été échantillonné ou comment les échantillons positifs et négatifs ont été constitués.
En résumé, cette publication open source indique « nous utilisons des sommes pondérées pour calculer les scores » sans révéler les poids ; elle mentionne « nous utilisons des transformers pour prédire les probabilités comportementales » sans détailler leur structure interne.
À titre de comparaison, TikTok et Instagram n’ont rien publié de comparable. La publication open source de X est effectivement plus complète que celle des autres grandes plateformes, mais elle n’est pas totalement transparente.
Cela ne remet pas en cause l’intérêt de l’open source. Pour les créateurs et chercheurs, accéder au code est préférable à l’absence totale d’information.
Déclaration :
- Ce contenu est repris de [TechFlow], avec droits d’auteur détenus par l’auteur original [David]. Pour toute question concernant cette reprise, veuillez contacter l’équipe Gate Learn, qui traitera votre demande rapidement selon les procédures applicables.
- Avertissement : Les opinions exprimées dans cet article sont celles de l’auteur et ne constituent pas un conseil en investissement.
- Les versions traduites de cet article sont réalisées par l’équipe Gate Learn. Sauf mention explicite de Gate, il est interdit de copier, distribuer ou plagier ce contenu traduit.








