En résumé
- OpenAI a lancé GPT-5.4 au milieu de la controverse croissante QuitGPT concernant son contrat d’IA avec le Pentagone.
- GPT-5.4 ajoute une fenêtre de contexte d’un million de tokens, un raisonnement renforcé et des capacités agentiques.
- Les utilisateurs d’entreprise en tirent le plus profit, car GPT-5.4 offre des agents IA plus rapides avec moins de tokens.
OpenAI a commencé à déployer GPT-5.4 — son modèle le plus performant à ce jour — jeudi, alors que l’entreprise tente de contenir une crise de relations publiques qui a vu environ 2,5 millions d’utilisateurs prendre des mesures contre la société, soit en annulant leur abonnement, soit en partageant le boycott sur les réseaux sociaux.
Le mouvement QuitGPT, appelé ainsi, a explosé après qu’OpenAI a révélé un accord avec le Département de la Défense des États-Unis, quelques heures seulement après qu’Anthropic a publiquement abandonné le même contrat — ce qui a valu au créateur de Claude la méfiance du président Trump et d’autres responsables gouvernementaux.
Le point de friction pour Anthropic : le DoD a refusé d’inclure un langage interdisant explicitement le déploiement d’armes autonomes et la surveillance de masse des citoyens américains.
OpenAI a néanmoins accepté le contrat. Le PDG Sam Altman, qui a été interrogé sur l’écart apparent entre les lignes rouges de sécurité déclarées par sa société et le contenu réel du contrat, doit reconquérir ces utilisateurs.
Voici GPT-5.4… seulement deux jours après l’introduction de GPT-5.3.
Ce nouveau modèle rassemble les capacités de raisonnement, de codage et agentiques en une seule version. Il dispose également d’une capacité de contexte d’un million de tokens, ce qui permet aux utilisateurs de gérer plus facilement de grandes quantités d’informations en une seule session.
Sur le papier, les chiffres semblent prometteurs. Sur GDPval — un benchmark testant les compétences professionnelles dans 44 métiers — GPT-5.4 égalise ou dépasse les professionnels dans 83,0 % des comparaisons, contre 70,9 % pour GPT-5.2. La maîtrise de l’utilisation d’ordinateur est la plus grande avancée : sur OSWorld-Verified, qui mesure la capacité d’un modèle à faire fonctionner un bureau via captures d’écran et actions clavier/souris, GPT-5.4 atteint un taux de réussite de 75,0 % contre 47,3 % pour GPT-5.2 — dépassant ainsi la référence humaine de 72,4 %.
Sur BrowseComp, un test de recherche approfondie sur le web, il progresse de 17 points de pourcentage par rapport à GPT-5.2. La fenêtre de contexte d’un million de tokens et une fonction de redirection en cours de réponse — permettant aux utilisateurs de réorienter le modèle pendant qu’il réfléchit — complètent les fonctionnalités phares.
Cette fonctionnalité permet de gagner du temps et des ressources en évitant de devoir supprimer tous les tokens générés précédemment lorsqu’une erreur est détectée.
Qui bénéficiera de GPT 5.4 ?
Il est important de noter que certains benchmarks comparent principalement GPT-5.4 — et la plupart du temps, le raisonnement est configuré à un effort très élevé, ce que les utilisateurs gratuits et Plus ne peuvent pas profiter — à GPT-5.2, en passant complètement sous silence GPT-5.3.
Pour les utilisateurs déjà sur GPT-5.3, plusieurs améliorations peuvent sembler plus progressives que ce que montrent les graphiques.
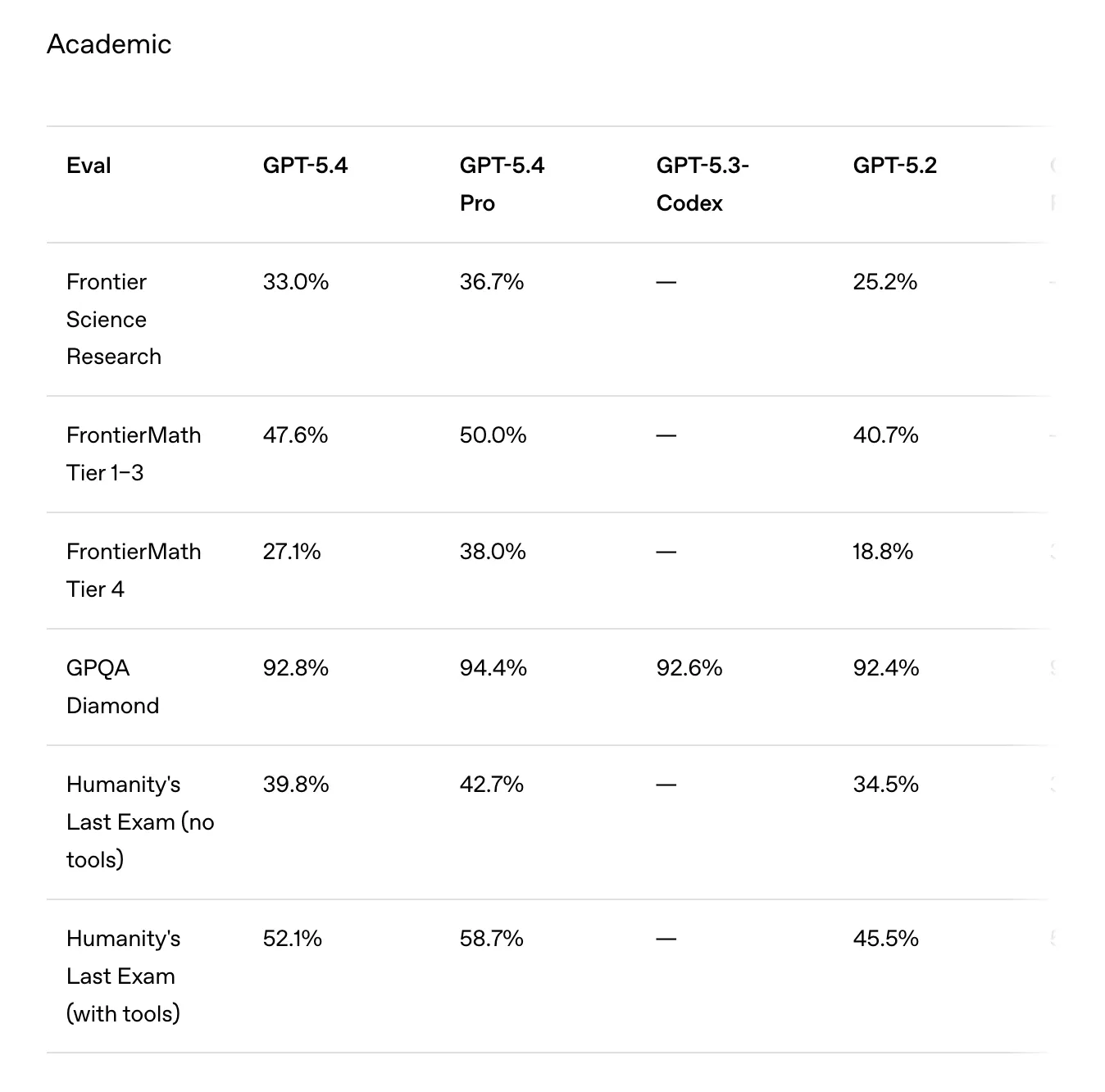
Les programmeurs ont le plus de raisons de modérer leurs attentes : sur SWE-Bench Pro, l’amélioration de GPT-5.3-Codex (56,8 %) à GPT-5.4 (57,7 %) est à peine une erreur d’arrondi. Le modèle affirme également nécessiter beaucoup moins de tokens pour accomplir ses tâches par rapport à GPT-5.2.
« GPT‑5.4 est notre modèle de raisonnement le plus efficace en tokens à ce jour, utilisant beaucoup moins de tokens pour résoudre des problèmes comparé à GPT‑5.2 », a déclaré OpenAI.
Cela dit, toute amélioration dans ce domaine est positive pour les développeurs utilisant les modèles OpenAI via API et facturés par token utilisé. Un modèle avec une chaîne de pensée efficace peut fournir les mêmes résultats à une fraction du coût, contrairement à un modèle qui overthinke pour s’assurer d’arriver à la bonne conclusion.
Il y a une autre complication pour ceux qui espèrent utiliser le nouveau modèle dès maintenant : OpenAI indique que GPT-5.4 sera lancé aujourd’hui, mais il n’était pas encore disponible au moment de la rédaction, il est donc probablement déployé lentement. Pour la plupart des utilisateurs, le meilleur modèle reste GPT 5.3, qui ne peut être utilisé que pour des réponses instantanées, c’est-à-dire qui ne nécessitent pas trop d’efforts.
Les utilisateurs qui comptent sur la réflexion — la terminologie d’OpenAI pour le raisonnement en chaîne prolongé sur des tâches complexes — sont toujours sur GPT-5.2. En d’autres termes, ceux qui sont le plus susceptibles de pousser le modèle à ses limites sont les derniers à l’obtenir.
Les bénéficiaires les plus évidents sont les utilisateurs d’entreprise effectuant un travail lourd en documents. Sur un benchmark interne de modélisation de feuilles de calcul, GPT-5.4 a obtenu 87,3 % contre 68,4 % pour GPT-5.2. La société de recherche juridique Harvey a indiqué un score de 91 % lors de son évaluation BigLaw. Mainstay, qui gère des agents sur 30 000 portails de taxes foncières, a rapporté un taux de réussite au premier essai de 95 % et des sessions environ « 3 fois plus rapides tout en utilisant environ 70 % de tokens en moins ».
Ce genre d’argument d’efficacité pourrait convaincre les équipes d’approvisionnement en entreprise — mais il est plus difficile à vendre à l’utilisateur individuel qui reconsidère la suppression de son compte.
Avertissement : Les informations contenues dans cette page peuvent provenir de tiers et ne représentent pas les points de vue ou les opinions de Gate. Le contenu de cette page est fourni à titre de référence uniquement et ne constitue pas un conseil financier, d'investissement ou juridique. Gate ne garantit pas l'exactitude ou l'exhaustivité des informations et n'est pas responsable des pertes résultant de l'utilisation de ces informations. Les investissements en actifs virtuels comportent des risques élevés et sont soumis à une forte volatilité des prix. Vous pouvez perdre la totalité du capital investi. Veuillez comprendre pleinement les risques pertinents et prendre des décisions prudentes en fonction de votre propre situation financière et de votre tolérance au risque. Pour plus de détails, veuillez consulter l'
avertissement.

