Quant trader gemchange_ltd a publié un long article sur X, listant sa feuille de route complète pour apprendre « si je devais tout recommencer, dans quel ordre je m’y prendrais », allant de la théorie des probabilités au calcul stochastique, en passant par cinq niveaux de mathématiques, en 18 mois seulement, pour passer de zéro à une véritable compréhension de la trading quantitatif. Cet article est tiré de son post populaire sur X, « How I’d Become a Quant If I Had to Start Over Tomorrow », traduit et réorganisé par Flip.
(Précédent contexte : un trader qui ne dépend pas des commissions ni ne publie ses ordres, utilisant uniquement une stratégie gagnante basée sur l’analyse des cycles)
(Complément : note de survie d’une top trader crypto féminine : ne pas se laisser ruiner par la promesse de « devenir riche rapidement »)
Table des matières
Toggle
- Partie I : Probabilités, le langage de l’incertitude
- Partie II : Statistiques — apprendre à écouter les données
- Partie III : Algèbre linéaire — la machine qui fait tout tourner
- Partie IV : Calcul différentiel et optimisation — le langage du changement
- Partie V : Calcul stochastique — le vrai seuil pour devenir Quant
- Polymarket
- Comment LMSR fixe le prix des croyances
- La cartographie de la carrière en trading quantitatif : quatre profils types
- Boîte à outils et bibliographie
- Trois choses que l’auteur aurait aimé savoir plus tôt
Déclaration : cet article ne constitue pas un conseil en investissement. Le marché comporte des risques, faites vos propres recherches.
Commençons par quelques chiffres : en 2025, le salaire annuel brut d’un Quant débutant dans une grande institution se situe entre 300 000 et 500 000 dollars. Le recrutement en IA/ML dans la finance augmente de 88 % par an. Y a-t-il une carte pour cette voie ?
Cet article est ce que l’auteur aurait voulu recevoir lorsqu’il a commencé. La feuille de route est organisée selon « l’ordre dans lequel tu devrais apprendre », chaque concept étant construit sur le précédent, comme dans un jeu vidéo : impossible de sauter des niveaux. Mais si tu t’y mets sérieusement, pas en regardant des vidéos ennuyeuses d’introduction à la finance sur YouTube (ce qui serait une perte de temps), en résolvant des problèmes, en manipulant des données — en environ 18 mois, tu peux passer de ne rien connaître à comprendre réellement quelques notions.
Range toutes tes connaissances en trading dans un tiroir. La majorité pense que la quant trading consiste à choisir des actions, avoir une opinion sur Tesla, prévoir les résultats financiers. Ce n’est pas ça. La quant, c’est les mathématiques. Tu étudies les relations statistiques, la tarification des inefficacités, et ces avantages structurels issus du fait que « le marché est un système complexe où des personnes commettent systématiquement des erreurs ».
Partie I : Probabilités, le langage de l’incertitude
Tout en finance quantitative peut se résumer à une question : Quel est le taux de réussite ? Est-ce que j’ai raison ?
C’est la probabilité. Si tu ne comprends pas profondément la probabilité, tout ce qui suit dans cet article ne te servira à rien.
Probabilité conditionnelle : la façon de penser du Quant
La plupart pensent en termes absolus : cette chose est vraie ou fausse. Le Quant pense en termes conditionnels : selon ce que je sais maintenant, quelle est la probabilité que cette chose soit vraie ?
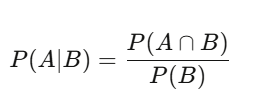
P(A|B) = P(A∩B) / P(B) — La probabilité que A se produise sachant B est la probabilité que A et B se produisent simultanément, divisée par la probabilité que B se produise. Ça paraît simple, mais c’est très puissant. Par exemple : une action a 60 % de chances d’être en hausse en journée — c’est la probabilité de base. Mais si on regarde les jours où le volume est supérieur à la moyenne, la probabilité de hausse monte à 75 %. La probabilité conditionnelle ici est l’information pertinente ; le chiffre initial de 60 % n’est qu’un bruit.
Le théorème de Bayes : mettre à jour ses croyances en temps réel
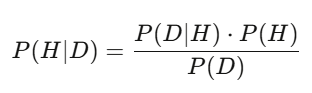
La postérieure = (la probabilité d’observer cette donnée si l’hypothèse est vraie) × la croyance initiale ÷ (la probabilité d’observer cette donnée sous n’importe quelle hypothèse). En pratique, on utilise l’échantillonnage Monte Carlo pour calculer cela. La logique est la même : Bayes permet d’ajuster ses jugements en temps réel face à de nouvelles informations. Si un modèle estime qu’une action vaut 50 dollars, mais que le rapport de revenus dépasse les attentes de 3 %, la postérieure monte. Ceux qui mettent à jour le plus vite et le plus précisément gagnent.
Espérance et variance : vos deux meilleurs amis
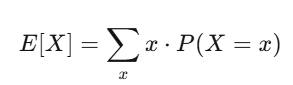
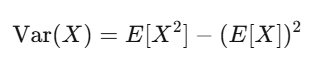
L’espérance, c’est la force de votre conviction ; la variance, c’est le risque. Si votre stratégie a une espérance positive et que vous pouvez supporter la volatilité, vous avez de bonnes chances de faire du profit.
Exercice niveau 1 (2 heures par jour, 3-4 semaines)
- Lire : Blitzstein & Hwang, « Introduction to Probability » (PDF gratuit à Harvard), faire tous les exercices des chapitres 1 à 6
- Programmer : simuler 10 000 lancers de pièce, visualiser la loi des grands nombres
- Programmer : réaliser un filtre de Bayes, en entrant une croyance initiale et une vraisemblance, obtenir la croyance mise à jour
import numpy as np
import matplotlib.pyplot as plt
# Loi des grands nombres : la moyenne empirique converge vers la vraie probabilité
np.random.seed(42)
lancers = np.random.choice([0, 1], size=10000, p=[0.5, 0.5])
moyenne_courante = np.cumsum(lancers) / np.arange(1, 10001)
plt.figure(figsize=(10, 4))
plt.plot(moyenne_courante, linewidth=0.7)
plt.axhline(y=0.5, color='r', linestyle='--', label='Vraie probabilité')
plt.xlabel('Nombre de lancers')
plt.ylabel('Moyenne empirique')
plt.title('Démonstration de la loi des grands nombres')
plt.legend()
plt.savefig('lln.png', dpi=150)
print(f"Après 10 000 lancers : {moyenne_courante[-1]:.4f} (Vraie : 0.5000)")
Partie II : Statistiques — apprendre à écouter les données
Une fois que tu maîtrises le langage des probabilités, il faut apprendre à en tirer quelque chose. La première leçon en statistique : la plupart des découvertes qui semblent significatives ne sont en réalité que du bruit.

Test d’hypothèse : ton détecteur de bruit
Tu as construit un modèle, backtesté avec un rendement annualisé de 15 %. Est-ce vrai ? Tu poses l’hypothèse nulle H₀ : « cette stratégie n’a pas d’avantage, son espérance est zéro », tu calcules la statistique de test, le p-value. Mais attention : si tu testes 1000 stratégies aléatoires, par hasard, 50 auront un p-value inférieur à 0,05. C’est le problème de la multiplicité. La solution : correction de Bonferroni (diviser le seuil par le nombre de tests), ou contrôle du taux de fausses découvertes avec la méthode de Benjamini-Hochberg. Beaucoup de débutants surestiment leur capacité à trouver quelque chose de significatif. Les 10 premières stratégies sont toutes du bruit. Accepte-le, ça t’économisera beaucoup d’argent.
Régression : décomposer la performance
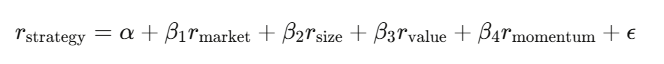
La régression linéaire y = Xβ + ε est l’outil principal en finance. Tu fais une régression des rendements de ta stratégie sur les facteurs de risque connus, et l’intercept α représente ton alpha — la partie de la performance qui ne s’explique pas par ces facteurs.
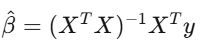
Si après contrôle des facteurs, α est nul, ton « avantage » n’est qu’une exposition factice au marché. Utilise l’erreur standard de Newey-West, car les données financières présentent autocorrélation et hétéroscédasticité. L’erreur standard classique, c’est comme conduire avec un pare-brise cassé à grande vitesse.
Estimation par maximum de vraisemblance (MLE)
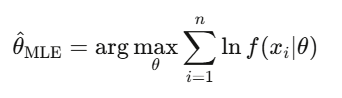
C’est la méthode de calibration de tous les modèles en finance : ajuster la volatilité GARCH, estimer les paramètres de saut, calibrer le prix des options à partir du marché. Quand on parle de « calibration », on parle presque toujours de MLE.
Exercice niveau 2 (4-5 semaines)
- Lire : Wasserman, « All of Statistics », chapitres 1 à 13
- Télécharger des rendements réels (yfinance), tester la normalité (échec assuré), ajuster une loi t via MLE, comparer
- Effectuer une régression Fama-French à l’aide de statsmodels
- Implémenter un test de permutation : mélanger 10 000 fois les dates, comparer la performance permutée à la performance réelle
Partie III : Algèbre linéaire — la machine qui fait tout tourner
L’algèbre linéaire peut sembler ennuyeuse, mais c’est la machine qui fait tout : construction de portefeuilles, analyse en composantes principales, réseaux neuronaux, estimation de la covariance, modèles factoriels. Sans matrices, pas de Quant.

Pensée matricielle
La matrice de covariance Σ capture la façon dont chaque actif se déplace par rapport aux autres. Pour 500 actions, Σ est une matrice 500×500, avec 125 250 valeurs uniques. La variance d’un portefeuille s’écrit simplement w’Σw — une forme quadratique au cœur de la théorie de Markowitz, de la gestion du risque, de tout.
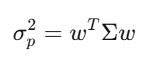
Valeurs propres : ce qui compte vraiment
Regarde l’univers de 500 actions : les 5 premiers vecteurs propres expliquent 70 % de la variance totale. Le reste, c’est du bruit. La première décomposition en valeurs propres change tout : c’est la réduction de dimension, la base de l’investissement factoriel.
Exercice niveau 3 (4-6 semaines)
- Regarder : le cours de Gilbert Strang sur l’algèbre linéaire du MIT (18.06), en entier, sans sauter de sections
- Lire : Strang, « Introduction to Linear Algebra », faire tous les exercices
- Appliquer PCA sur le S&P 500, tracer le spectre des valeurs propres, identifier les trois premiers composants principaux
- Réaliser une optimisation de portefeuille de Markowitz à partir de zéro
import numpy as np
import cvxpy as cp
np.random.seed(42)
n_assets = 10
mu = np.random.uniform(0.04, 0.15, n_assets)
A = np.random.randn(n_assets, n_assets) * 0.1
cov = A @ A.T + np.eye(n_assets) * 0.01
w = cp.Variable(n_assets)
objective = cp.Minimize(cp.quad_form(w, cov))
constraints = [
mu @ w >= 0.08, # rendement minimal
cp.sum(w) == 1, # portefeuille entièrement investi
w >= -0.1, # limite de vente à découvert
w <= 0.3 # limite d’achat
]
prob = cp.Problem(objective, constraints)
prob.solve()
ret = mu @ w.value
vol = np.sqrt(w.value @ cov @ w.value)
sharpe = (ret - 0.03) / vol
print(f"Rendement du portefeuille : {ret:.4f}")
print(f"Volatilité du portefeuille : {vol:.4f}")
print(f"Ratio de Sharpe : {sharpe:.4f}")
Partie IV : Calcul différentiel et optimisation — le langage du changement
Le calcul différentiel est le langage qui décrit le changement. En finance, tout évolue : prix, volatilité, corrélations, distributions de probabilité. Le calcul différentiel permet de décrire et d’exploiter ces variations. La dérivée apparaît dans la rétropropagation des réseaux neuronaux et dans le calcul des grecs des options.
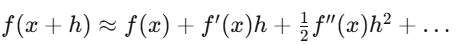
Le développement de Taylor est l’approximation du delta : la première ordre pour couvrir le risque, la gamma ajoute la correction de deuxième ordre. L’intégrale d’Itô diffère du calcul classique car le terme quadratique (dW_t)² ne s’annule pas.
Exercice niveau 4 (4-5 semaines)
- Lire : Boyd & Vandenberghe, « Convex Optimization » (PDF gratuit à Stanford), chapitres 1-5
- Implémenter la descente de gradient pour minimiser la fonction de Rosenbrock
- Résoudre avec cvxpy un problème d’optimisation de portefeuille avec coûts de transaction
Partie V : Calcul stochastique — le vrai seuil pour devenir Quant
Avant d’étudier le calcul stochastique, tu es un data scientist passionné de finance. Après, tu es un Quant. C’est là que tu apprends à modéliser le hasard en temps continu, à dériver l’équation de Black-Scholes à partir des principes fondamentaux, et à comprendre pourquoi le marché dérivé, avec ses trillions de dollars, fonctionne ainsi.

Mouvement brownien : formaliser le hasard
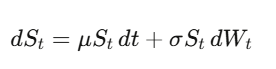
Le mouvement brownien (processus de Wiener) W_t est une marche aléatoire continue dans le temps. La clé — sur laquelle tout repose — est que dW_t a une « taille » de √dt, ce qui implique que (dW_t)² = dt. Ça peut sembler technique, mais c’est la vérité la plus fondamentale en finance quantitative.
Loi d’Itô
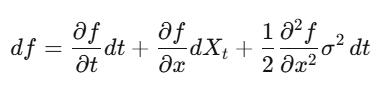
En calcul classique, on fait un développement de Taylor : (dx)² est négligeable. Mais si x est un processus stochastique, (dW_t)² = dt est un terme de premier ordre, on ne peut pas l’ignorer. La formule d’Itô : df = (∂f/∂t + μ∂f/∂x + ½σ²∂²f/∂x²)dt + σ∂f/∂x dW_t. En appliquant cela au prix d’une option, on obtient l’équation de Black-Scholes.
Dérivation complète de Black-Scholes
Étape 1 : Soit V(S,t) le prix de l’option, on applique le calcul d’Itô.
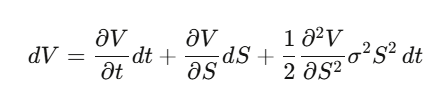
Étape 2 : Construire un portefeuille Delta-neutre Π = V − (∂V/∂S)·S, et calculer dΠ — la partie en dW_t s’annule parfaitement, ce portefeuille est localement sans risque.
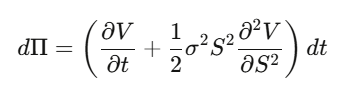
Étape 3 : Ce portefeuille sans risque doit croître au taux sans risque.
Étape 4 : En remplaçant et en simplifiant, on obtient l’équation de Black-Scholes.
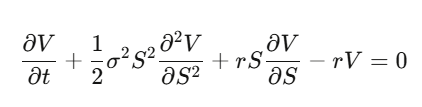
Ce qui est crucial : la dérive μ disparaît. Le prix de l’option ne dépend pas du rendement attendu de l’action, ni de la préférence au risque. On peut tout valoriser sous un « risque neutre » — c’est la clé. La première fois qu’on comprend ça, ça peut faire mal à la tête.
Pour une option européenne avec prix d’exercice K et maturité T, la solution du PDE donne :
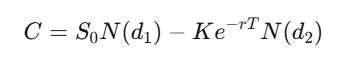
où
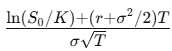
et
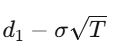
Les grecs
- Delta Δ : pour chaque dollar de variation du prix de l’action, combien varie le prix de l’option — votre ratio de couverture
- Gamma Γ : la vitesse de variation de Delta, votre convexité
- Theta Θ : la dépréciation temporelle, souvent négative pour les positions longues
- Vega V : la sensibilité à la volatilité, la principale source de profit pour la majorité des dérivés
- Rho ρ : la sensibilité aux taux d’intérêt
import numpy as np
from scipy.stats import norm
def black_scholes(S, K, T, r, sigma, option_type='call'):
d1 = (np.log(S/K) + (r + sigma**2/2)*T) / (sigma*np.sqrt(T))
d2 = d1 - sigma*np.sqrt(T)
if option_type == 'call':
return S*norm.cdf(d1) - K*np.exp(-r*T)*norm.cdf(d2)
else:
return K*np.exp(-r*T)*norm.cdf(-d2) - S*norm.cdf(-d1)
def monte_carlo_option(S0, K, T, r, sigma, n_sims=500000):
Z = np.random.standard_normal(n_sims)
ST = S0 * np.exp((r - sigma**2/2)*T + sigma*np.sqrt(T)*Z)
payoffs = np.maximum(ST - K, 0)
price = np.exp(-r*T) * np.mean(payoffs)
stderr = np.exp(-r*T) * np.std(payoffs) / np.sqrt(n_sims)
return price, stderr
S, K, T, r, sigma = 100, 105, 1.0, 0.05, 0.2
bs_price = black_scholes(S, K, T, r, sigma)
mc_price, mc_err = monte_carlo_option(S, K, T, r, sigma)
print(f"Black-Scholes : ${bs_price:.4f}")
print(f"Monte Carlo : ${mc_price:.4f} ± {mc_err:.4f}")
Exercice niveau 5 (6-8 semaines, le plus difficile)
- Lire : Shreve, « Stochastic Calculus for Finance II » (standard de référence)
- Alternative : Arguin, « A First Course in Stochastic Calculus », plus récent, plus accessible
- Re-derive : pour f(S) = ln(S), utiliser Itô pour obtenir le terme −σ²/2
- Re-derive : l’équation de Black-Scholes complète, en partant de la construction du portefeuille Delta-neutre
- Programmer : implémenter de zéro la formule de Black-Scholes, puis la comparer à Monte Carlo pour vérifier la convergence
Polymarket
C’est actuellement le marché le plus intéressant au monde, et derrière, une mathématique qui relie tous les sujets abordés :
Probabilités, théorie de l’information, optimisation convexe, programmation entière.
Comment LMSR fixe le prix des croyances
Logarithmic Market Scoring Rule (LMSR), inventé par Robin Hanson, pour alimenter des marchés prédictifs automatisés.
Pour n résultats, la fonction de coût est :
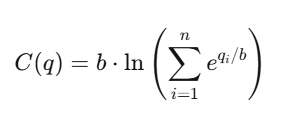
où
- q_i : le nombre de parts non liquidées pour le résultat i
- b : le paramètre de liquidité (liquidity parameter)
Le prix du résultat i est :
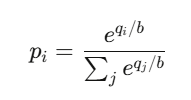
Ce qui correspond à la fonction softmax — la même que celle utilisée dans la classification par réseaux neuronaux.
Ses propriétés :
- La somme des prix est toujours égale à 1
- Chaque prix est dans (0,1)
- Le marché offre une liquidité infinie, avec des prix toujours présents
Le maximum de perte pour le market maker est limité à : b × ln(n)
La cartographie de la carrière en trading quantitatif : quatre profils types
Quant Researcher (QR) : cherche des patterns dans des pétaoctets de données, construit des modèles prédictifs, conçoit des stratégies. Nécessite un doctorat en mathématiques, statistiques ou ML, ou une excellence exceptionnelle à l’université. Chez Jane Street, le QR dispose de dizaines de milliers de GPU.
Quant Developer/Engineer (QD) : construit la plateforme de trading, le moteur d’exécution, le pipeline de données en temps réel, pour que les modèles du QR puissent trader. Nécessite du C++, Rust ou Python en production, avec une faible latence.
Quant Trader (QT) : décideur, gère le capital, contrôle le risque, fait des jugements instantanés. La rémunération varie énormément, certains gagnent des dizaines de millions par an.
Risk Quant : garant de la robustesse, vérification des modèles, VaR, stress testing, conformité réglementaire. Parcours plus stable, plafond plus bas. Les nouveaux rôles en IA/ML (utilisant le deep learning pour générer des signaux) sont en forte croissance : +88 % par an en 2025.
Voici une fourchette de salaires dans les grandes institutions américaines (Jane Street, Citadel, HRT) :
- Diplômé débutant : 300 000 à 500 000 dollars + bonus
- Intermédiaire (3-7 ans) : 550 000 à 950 000 dollars
- Senior (8 ans et plus) : 1 000 000 à 3 000 000 dollars
- Star trader / PM : 3 000 000 à 30 000 000 dollars
Dans des structures moyennes (Two Sigma, DE Shaw), un débutant touche environ 250 000 à 350 000 dollars. La rémunération moyenne chez Jane Street en 2025 dépasse 1,4 million de dollars par an — c’est la moyenne.
Processus d’entretien : tri du CV → test en ligne (Zetamac pour calcul mental, objectif >50 points, questions logiques) → entretien téléphonique (questions probabilistes, jeux de hasard) → Superday (3-5 tours, trading simulé, coding, whiteboard). Jane Street pose volontairement des questions difficiles, pour voir comment tu utilises les indices et collabores. La majorité des stagiaires récents ont un background en informatique (plus de deux tiers), un tiers en mathématiques, peu de connaissances financières requises.
Pour préparer, on recommande d’étudier « Green Book » de Zhou (guide pratique pour les entretiens quantitatifs, plus de 200 questions réelles), associé à QuantGuide.io (LeetCode pour la finance) et Brainstellar.
La boîte à outils et la bibliographie
Stack Python : pandas/polars (Polars est 10-50 fois plus rapide sur gros volumes), numpy/scipy, xgboost/lightgbm, pytorch, cvxpy, QuantLib, statsmodels, NautilusTrader ou vectorbt pour backtesting.
Sources de données gratuites : yfinance, Finnhub (60 requêtes par minute), Alpha Vantage. Niveau intermédiaire : Polygon.io (199$/mois, latence <20ms). Niveau entreprise : Bloomberg Terminal (~32 000$/an).
Bibliographie (par ordre)
- Mathématiques : Blitzstein & Hwang « Probabilités » → Strang « Algèbre linéaire » → Wasserman « All of Statistics » → Boyd & Vandenberghe « Optimisation convexe » → Shreve « Calcul stochastique I & II »
- Finance quantitative : Hull « Options, futures et autres dérivés » → Natenberg « Volatilité et tarification des options » → López de Prado « Machine learning avancé en finance » → Ernest Chan « Quantitative Trading » → Zuckerman « L’homme qui a résolu le mystère du marché »
- Entretiens : Zhou « Green Book » → Crack « Heard on the Street » → Joshi « Questions d’entretien quantitatif »
- Compétitions : Kaggle Jane Street (10 millions de dollars de prix), BRAIN de WorldQuant (plus de 100 000 utilisateurs, achat d’alphas), Citadel Datathon (accès rapide à un poste)
Trois choses que l’auteur aurait aimé savoir plus tôt
L’erreur d’estimation est l’ennemi principal. Le Full Kelly, Markowitz sans contrainte, les modèles ML avec trop de caractéristiques — tous échouent pour la même raison : surajustement au bruit dans l’estimation des paramètres. La mathématique fonctionne parfaitement avec des paramètres vrais. Mais tu n’as jamais de paramètres vrais. La différence entre théorie et pratique, c’est toujours l’erreur d’estimation. Les meilleurs Quant sont ceux qui respectent cette réalité.
Les outils se sont démocratisés, le jugement pas encore. Tout le monde peut accéder à QuantLib, Polygon.io, PyTorch. La technique est nécessaire, mais pas suffisante. La vraie différence, c’est la qualité des données, des modèles, ou de l’exécution — pas le pip install le plus récent.
Les mathématiques sont une barrière protectrice. L’IA peut coder, proposer des stratégies. Mais savoir pourquoi l’intégrale d’Itô comporte ce terme supplémentaire, prouver que la valeur actualisée sous la mesure neutre au risque est une martingale, ou connaître la convexité dans l’arbitrage de portefeuille — cette fluidité mathématique, c’est ce qui distingue le Quant qui construit un avantage de celui qui se contente d’emprunter celui des autres. L’avantage emprunté a une date d’expiration.
