DeepSeek V4リリース直前の重厚な論文公開大規模モデルは、単一の対話ロボットから、自律的に計画しツールを呼び出し実問題を解決できるエージェントへと急速に進化している。しかし、この変革は基盤となる計算力アーキテクチャに大きな衝撃をもたらしている。長期のコンテキスト内で環境と数十、あるいは百回以上のインタラクションを行う際、計算のボトルネックはGPUの演算能力から**ストレージI/O帯域幅**へと移行している。Tokenを少量ずつ追加するため、KV-キャッシュのヒット率は非常に高く(通常95%以上)、GPUの大部分の時間は外部ストレージから膨大な過去のKV-キャッシュデータを読み出す待ち時間に費やされている。この行き詰まりを打破するため、DeepSeekは北京大学、清華大学の研究チームと共同で、新たな大規模モデル推論システム——**DualPath**を提案した。このシステムは、「二重パスのKV-キャッシュ読み込み」メカニズムを導入し、クラスタ内の未使用のネットワーク帯域を巧みに活用することで、エージェント型大規模モデルのオフライン推論スループットを最大1.87倍向上させ、オンラインサービスのスループットも平均1.96倍改善した。現在、この研究は1152GPUを含む大規模クラスタ上で検証されており、DeepSeek-V3.2 660Bなどのトップクラスの大規模モデルをサポートしている。なぜ深刻なI/Oボトルネックが発生するのか?---------------DualPathの革新点を理解するには、まず既存のアーキテクチャの課題を把握する必要がある。典型的なエージェントのトラジェクトリでは、モデルは過去のコンテキストと新たに追加されたTokenを含むプロンプトを受け取り、次の動作を生成する。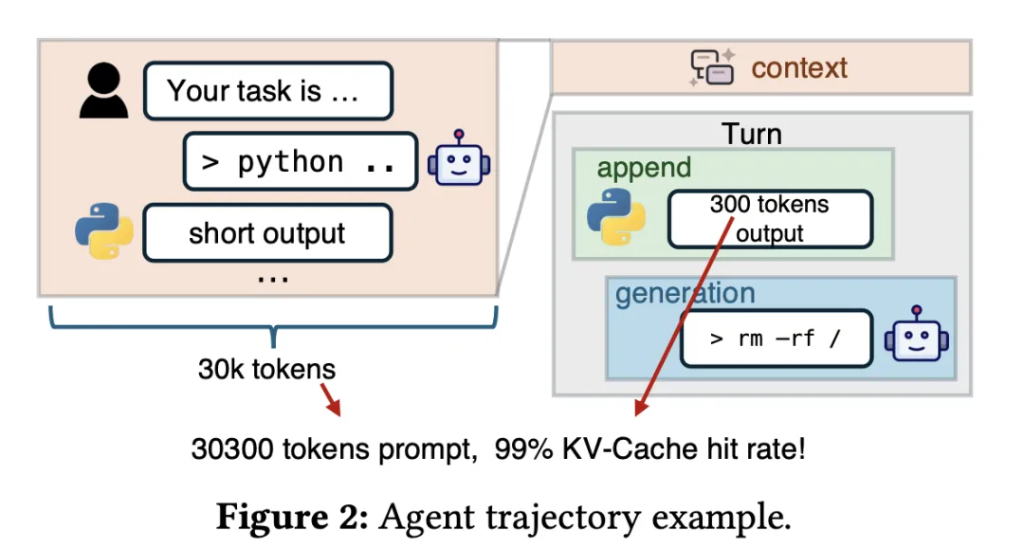この多回次・短追加のパターンは、コンテキスト長を急激に膨らませ、百万単位に達することさえある。GPUのメモリ(HBM)やメインメモリ(DRAM)の容量には限界があり、膨大なKV-キャッシュはより安価で遅いSSD外部ストレージに保存せざるを得ない。現代の大規模モデル推論システムは一般的に、Prefill-Decode(事前充填-デコード)分離アーキテクチャを採用している。事前充填ノードはプロンプトの処理とヒットしたKV-キャッシュの読み込みを担当し、デコードノードはTokenを一つずつ生成する。問題はここにある。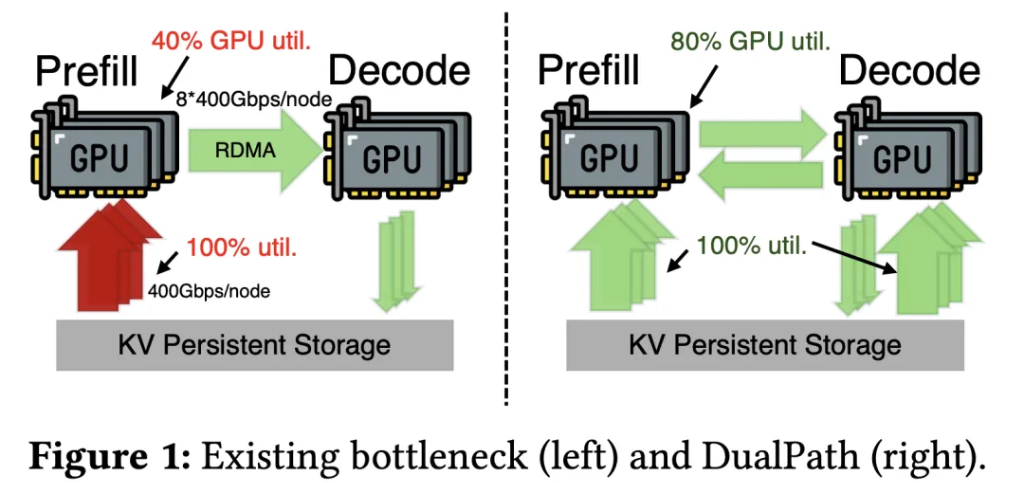図1左側に示すように、既存システムでは、すべてのKV-キャッシュが外部ストレージから直接事前充填ノードにロードされる。このため、極端な不均衡が生じている。事前充填ノードのストレージネットワークカード(SNIC)の帯域幅は完全に飽和し、システム全体のボトルネックとなる一方、デコードノードのストレージネットワークカードは大規模にアイドリング状態にある。さらに、ハードウェアの進化もこの矛盾を加速させている。図3左のNVIDIAハードウェアの進化経路を見ると、GPUの演算能力(FLOPS)の伸びはネットワーク帯域やメモリ容量の伸びを大きく上回っており、計算とI/Oの比率が深刻に偏っている。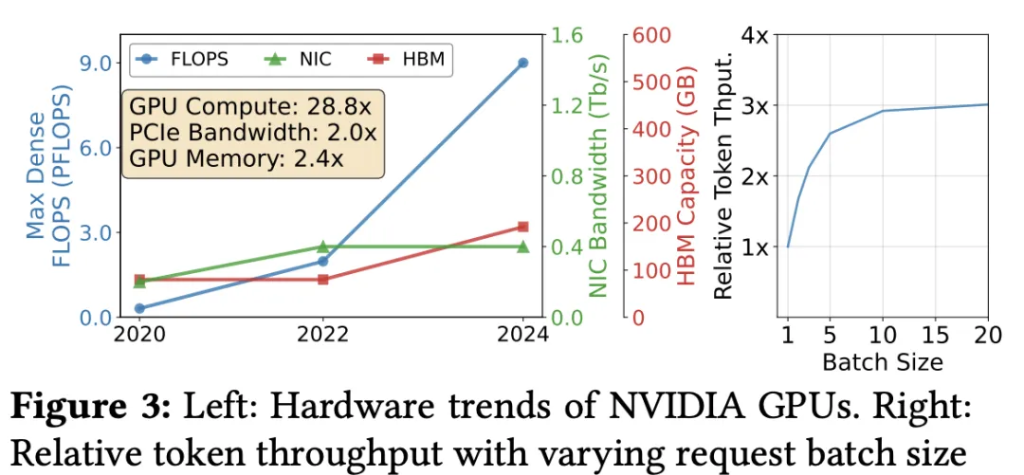DualPath:帯域幅の天井を打破する二重パス-------------------解码ノードのストレージ帯域が余っているなら、それを活用しない手はない。これがDualPathの核心思想だ。研究チームは、KV-キャッシュの読み込みアーキテクチャを再構築し、従来の「ストレージ→事前充填」経路に加え、新たに「ストレージ→デコード→事前充填」の二重パス読み込みチャネルを開設した。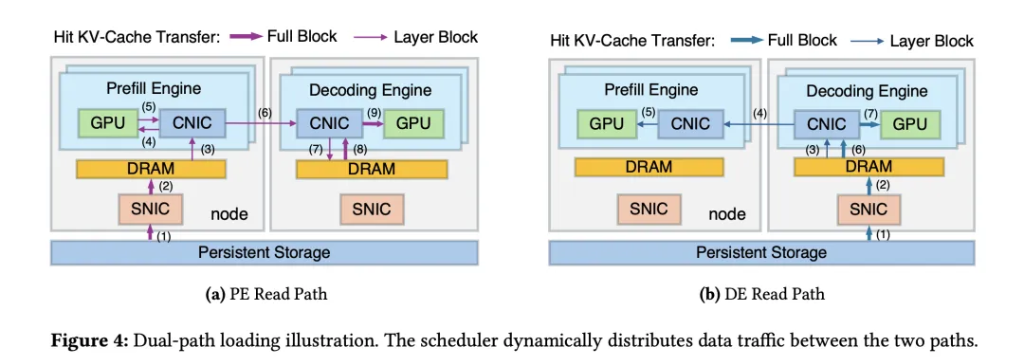1. 事前充填読み込みパス:KV-キャッシュは永続ストレージから読み出され、事前充填ノードのメモリバッファに格納される。その後GPUのメモリに転送され、最終的に完全なKV-キャッシュがデコードノードに渡される。2. デコード読み込みパス:KV-キャッシュはまず永続ストレージからデコードノードのメモリバッファに読み込まれる。このデータは、事前充填段階で、ノード間の高速計算ネットワーク(RDMA技術を採用)を用いて、階層的なストリーミング方式で送信され、事前充填ノードの計算に参加する。この二つのパスのデータフローを動的に割り当てることで、DualPathは従来の単一ノードのI/O負荷を、全体のリソースプールに分散させ、すべてのノードのストレージ帯域を効果的に集約した。実現のための課題克服:フロー隔離と動的スケジューリング----------------アイデアは直感的だが、ミリ秒未満の遅延に敏感な大規模モデル推論システムに実装するには、非常に難しい工学的課題を解決する必要がある。**第一の課題はネットワークフローの干渉だ。**追加のKV-キャッシュ伝送は、モデル推論中の重要な集団通信(例:MoEアーキテクチャのAllToAll操作)と衝突しやすく、推論全体の速度低下を招く。これに対し、DualPathは計算用ネットワークカード(CNIC)を中心としたフロー管理機構を設計した。システムはGPUへのすべての流れ(ホストからデバイスへのコピーも含む)を強制的に計算用ネットワークカードを経由させ、底層のネットワーク(InfiniBandの仮想チャネルなど)を用いてQoS(サービス品質)を厳格に制御する。モデル推論の通信は高優先度チャネルに割り当てられ、KV-キャッシュの伝送は低優先度チャネルに割り当てられ、計算ネットワークの空き時間にのみ伝送されることで、フローの隔離を実現している。**第二の課題は動的負荷分散だ。**複雑で変動するリクエストに対し、システムはリアルタイムで各リクエストに最適な読み込みパスを選択し、かつネットワークカードのキュー長やGPUの計算負荷も考慮しなければならない。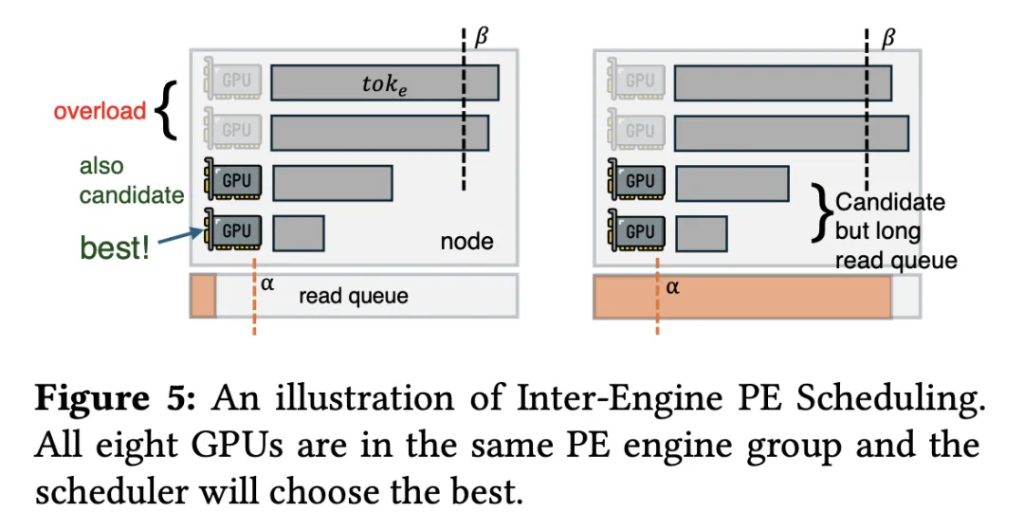DualPathは適応型リクエストスケジューラを導入している(図5参照)。このスケジューラは、各ノードのディスク読み込みキュー長を監視し、Token数を負荷の指標とする。システムは、過負荷、低読み込みキュー、高読み込みキューの三つにノードを分類し、短いキューを持つ未過負荷のノードに新規タスクを優先的に割り当てる。また、ノード内部では、所要時間の予測に基づき、実行時間が近いリクエストをまとめてバッチ化し、GPUの待ち時間による計算のバブルを最小化している。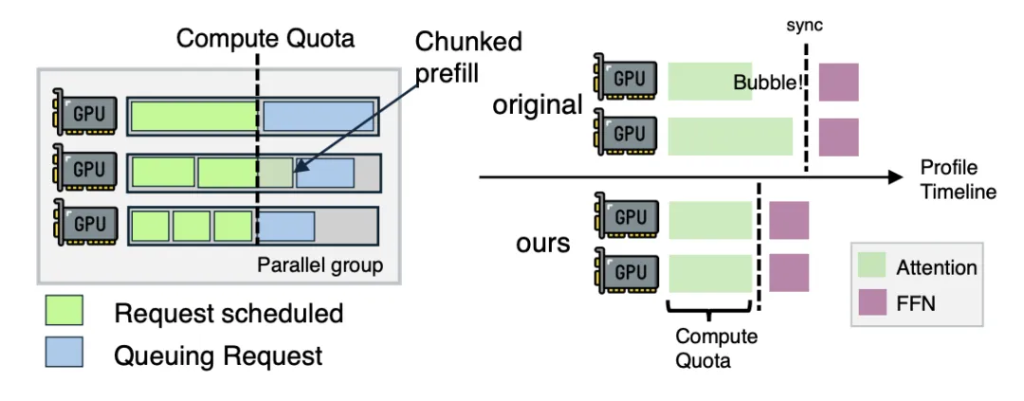スループットほぼ倍増、千規模の拡張も可能----------------研究チームは、InfiniBandネットワークと3FS分散ストレージを備えたNVIDIA Hopper GPUクラスタ上で、DualPathの全面評価を行った。テストモデルはDeepSeek-V3.2 660B、DS 27B、Qwen2.5-32Bを含み、実際のエージェント強化学習環境のトラジェクトリデータセットを使用した。**オフラインバッチ推論の性能**(例:強化学習のRollout段階):異なるエージェントの同時実行数や最大コンテキスト長の設定下で、DualPathは従来システムを圧倒した。DeepSeek 660Bモデルの処理時間短縮とスループット最大1.87倍の向上を実現。Token追加長や生成長に変動があっても、安定した性能向上を維持し、ストレージネットワークのボトルネックを解消したことを証明している。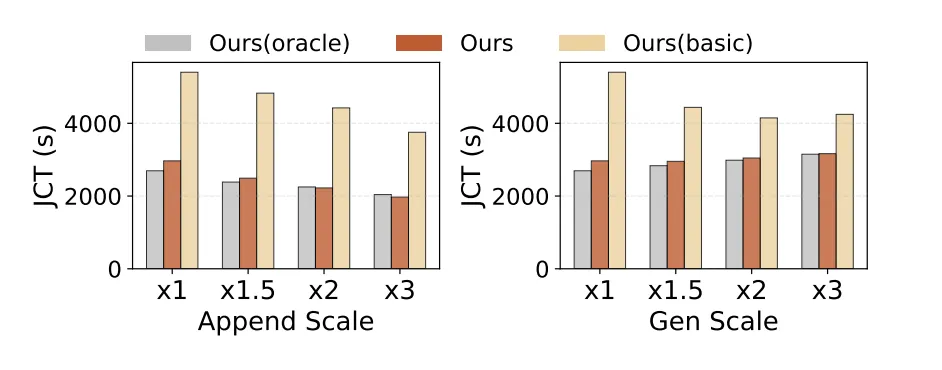**オンラインサービスのパフォーマンス**:遅延サービスレベル(最初の遅延4秒未満)を厳守しつつ、突発リクエストへの対応能力も大きく向上。DualPathは、基準システムと比べて最大2.25倍のリクエスト到達率(APS)を実現し、エンドツーエンドの生成遅延も極めて低く抑えた。アブレーション実験により、二重パスの読み込みと適応スケジューリングが性能向上の最重要因子であることも確認された。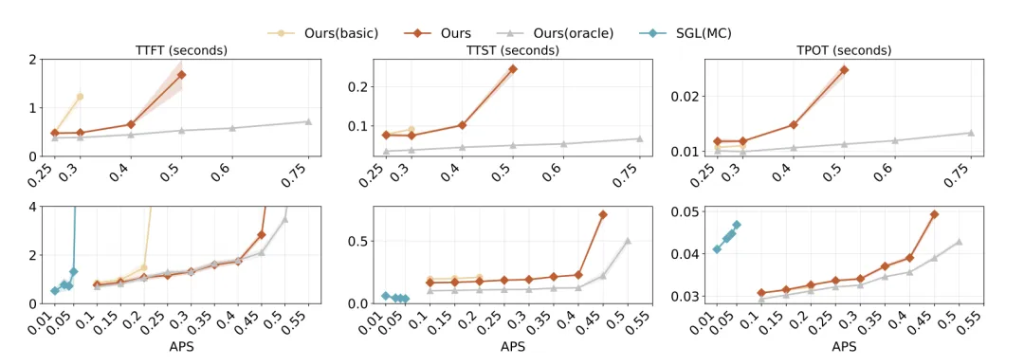**大規模拡張性**:このシステムは、小規模クラスタだけでなく、膨大な計算資源を持つ環境でも高い拡張性を示す。1152GPU(48の事前充填ノード、96のデコードノード)を含む大規模クラスタ上でも、ほぼ線形の性能拡張を実現している。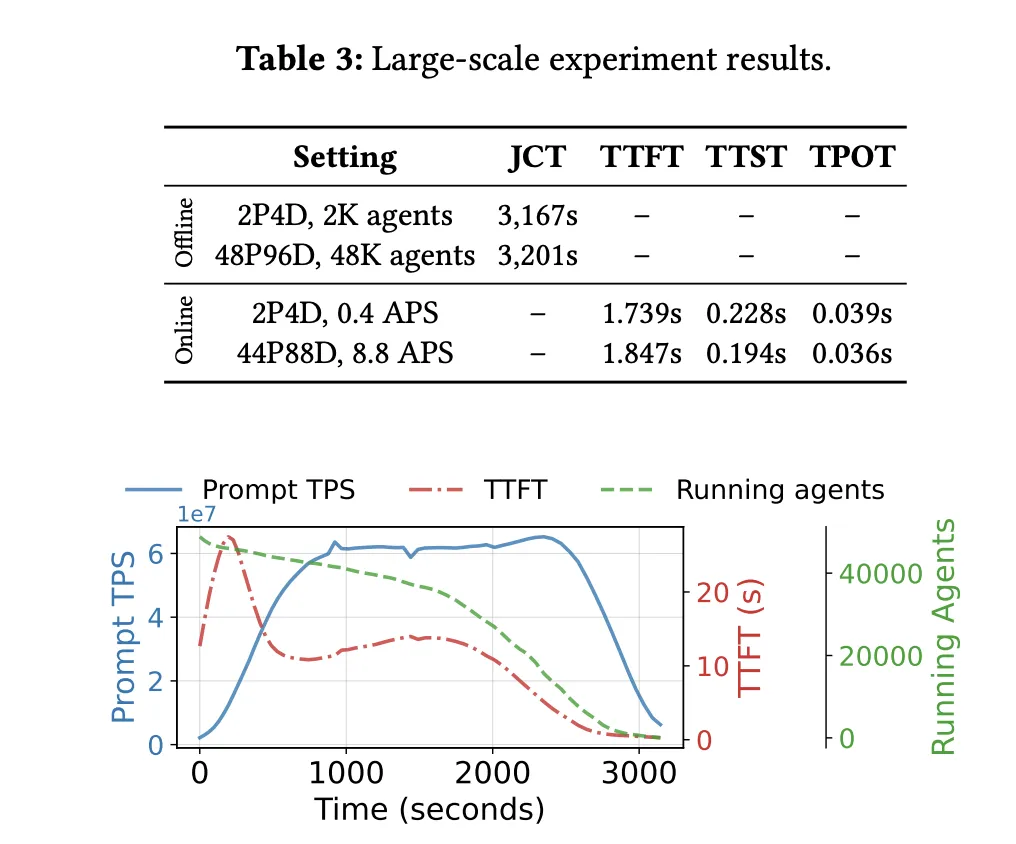底層のデータフローを再構築することで、DualPathは次世代エージェント型大規模モデルの高速推論に向けたインフラ基盤を整備した。本文出典:AI寒武紀リスク提示および免責条項市場にはリスクが伴い、投資は慎重に行うべきです。本記事は個別の投資助言を意図したものではなく、特定の投資目的や財務状況、ニーズを考慮したものではありません。読者は本記事の意見や見解、結論が自身の状況に適合するかどうかを判断し、投資の責任は自己負担です。

DeepSeekと清華大学・北京大学の共同重要論文:エージェントの基盤インフラに力を入れ、推論I/Oのボトルネックを突破!
DeepSeek V4リリース直前の重厚な論文公開
大規模モデルは、単一の対話ロボットから、自律的に計画しツールを呼び出し実問題を解決できるエージェントへと急速に進化している。しかし、この変革は基盤となる計算力アーキテクチャに大きな衝撃をもたらしている。
長期のコンテキスト内で環境と数十、あるいは百回以上のインタラクションを行う際、計算のボトルネックはGPUの演算能力からストレージI/O帯域幅へと移行している。Tokenを少量ずつ追加するため、KV-キャッシュのヒット率は非常に高く(通常95%以上)、GPUの大部分の時間は外部ストレージから膨大な過去のKV-キャッシュデータを読み出す待ち時間に費やされている。
この行き詰まりを打破するため、DeepSeekは北京大学、清華大学の研究チームと共同で、新たな大規模モデル推論システム——DualPathを提案した。
このシステムは、「二重パスのKV-キャッシュ読み込み」メカニズムを導入し、クラスタ内の未使用のネットワーク帯域を巧みに活用することで、エージェント型大規模モデルのオフライン推論スループットを最大1.87倍向上させ、オンラインサービスのスループットも平均1.96倍改善した。
現在、この研究は1152GPUを含む大規模クラスタ上で検証されており、DeepSeek-V3.2 660Bなどのトップクラスの大規模モデルをサポートしている。
なぜ深刻なI/Oボトルネックが発生するのか?
DualPathの革新点を理解するには、まず既存のアーキテクチャの課題を把握する必要がある。
典型的なエージェントのトラジェクトリでは、モデルは過去のコンテキストと新たに追加されたTokenを含むプロンプトを受け取り、次の動作を生成する。
この多回次・短追加のパターンは、コンテキスト長を急激に膨らませ、百万単位に達することさえある。GPUのメモリ(HBM)やメインメモリ(DRAM)の容量には限界があり、膨大なKV-キャッシュはより安価で遅いSSD外部ストレージに保存せざるを得ない。
現代の大規模モデル推論システムは一般的に、Prefill-Decode(事前充填-デコード)分離アーキテクチャを採用している。事前充填ノードはプロンプトの処理とヒットしたKV-キャッシュの読み込みを担当し、デコードノードはTokenを一つずつ生成する。
問題はここにある。
図1左側に示すように、既存システムでは、すべてのKV-キャッシュが外部ストレージから直接事前充填ノードにロードされる。このため、極端な不均衡が生じている。事前充填ノードのストレージネットワークカード(SNIC)の帯域幅は完全に飽和し、システム全体のボトルネックとなる一方、デコードノードのストレージネットワークカードは大規模にアイドリング状態にある。
さらに、ハードウェアの進化もこの矛盾を加速させている。図3左のNVIDIAハードウェアの進化経路を見ると、GPUの演算能力(FLOPS)の伸びはネットワーク帯域やメモリ容量の伸びを大きく上回っており、計算とI/Oの比率が深刻に偏っている。
DualPath:帯域幅の天井を打破する二重パス
解码ノードのストレージ帯域が余っているなら、それを活用しない手はない。これがDualPathの核心思想だ。
研究チームは、KV-キャッシュの読み込みアーキテクチャを再構築し、従来の「ストレージ→事前充填」経路に加え、新たに「ストレージ→デコード→事前充填」の二重パス読み込みチャネルを開設した。
事前充填読み込みパス:KV-キャッシュは永続ストレージから読み出され、事前充填ノードのメモリバッファに格納される。その後GPUのメモリに転送され、最終的に完全なKV-キャッシュがデコードノードに渡される。
デコード読み込みパス:KV-キャッシュはまず永続ストレージからデコードノードのメモリバッファに読み込まれる。このデータは、事前充填段階で、ノード間の高速計算ネットワーク(RDMA技術を採用)を用いて、階層的なストリーミング方式で送信され、事前充填ノードの計算に参加する。
この二つのパスのデータフローを動的に割り当てることで、DualPathは従来の単一ノードのI/O負荷を、全体のリソースプールに分散させ、すべてのノードのストレージ帯域を効果的に集約した。
実現のための課題克服:フロー隔離と動的スケジューリング
アイデアは直感的だが、ミリ秒未満の遅延に敏感な大規模モデル推論システムに実装するには、非常に難しい工学的課題を解決する必要がある。
第一の課題はネットワークフローの干渉だ。
追加のKV-キャッシュ伝送は、モデル推論中の重要な集団通信(例:MoEアーキテクチャのAllToAll操作)と衝突しやすく、推論全体の速度低下を招く。
これに対し、DualPathは計算用ネットワークカード(CNIC)を中心としたフロー管理機構を設計した。システムはGPUへのすべての流れ(ホストからデバイスへのコピーも含む)を強制的に計算用ネットワークカードを経由させ、底層のネットワーク(InfiniBandの仮想チャネルなど)を用いてQoS(サービス品質)を厳格に制御する。モデル推論の通信は高優先度チャネルに割り当てられ、KV-キャッシュの伝送は低優先度チャネルに割り当てられ、計算ネットワークの空き時間にのみ伝送されることで、フローの隔離を実現している。
第二の課題は動的負荷分散だ。
複雑で変動するリクエストに対し、システムはリアルタイムで各リクエストに最適な読み込みパスを選択し、かつネットワークカードのキュー長やGPUの計算負荷も考慮しなければならない。
DualPathは適応型リクエストスケジューラを導入している(図5参照)。このスケジューラは、各ノードのディスク読み込みキュー長を監視し、Token数を負荷の指標とする。システムは、過負荷、低読み込みキュー、高読み込みキューの三つにノードを分類し、短いキューを持つ未過負荷のノードに新規タスクを優先的に割り当てる。
また、ノード内部では、所要時間の予測に基づき、実行時間が近いリクエストをまとめてバッチ化し、GPUの待ち時間による計算のバブルを最小化している。
スループットほぼ倍増、千規模の拡張も可能
研究チームは、InfiniBandネットワークと3FS分散ストレージを備えたNVIDIA Hopper GPUクラスタ上で、DualPathの全面評価を行った。テストモデルはDeepSeek-V3.2 660B、DS 27B、Qwen2.5-32Bを含み、実際のエージェント強化学習環境のトラジェクトリデータセットを使用した。
オフラインバッチ推論の性能(例:強化学習のRollout段階):
異なるエージェントの同時実行数や最大コンテキスト長の設定下で、DualPathは従来システムを圧倒した。DeepSeek 660Bモデルの処理時間短縮とスループット最大1.87倍の向上を実現。
Token追加長や生成長に変動があっても、安定した性能向上を維持し、ストレージネットワークのボトルネックを解消したことを証明している。
オンラインサービスのパフォーマンス:
遅延サービスレベル(最初の遅延4秒未満)を厳守しつつ、突発リクエストへの対応能力も大きく向上。DualPathは、基準システムと比べて最大2.25倍のリクエスト到達率(APS)を実現し、エンドツーエンドの生成遅延も極めて低く抑えた。アブレーション実験により、二重パスの読み込みと適応スケジューリングが性能向上の最重要因子であることも確認された。
大規模拡張性:
このシステムは、小規模クラスタだけでなく、膨大な計算資源を持つ環境でも高い拡張性を示す。1152GPU(48の事前充填ノード、96のデコードノード)を含む大規模クラスタ上でも、ほぼ線形の性能拡張を実現している。
底層のデータフローを再構築することで、DualPathは次世代エージェント型大規模モデルの高速推論に向けたインフラ基盤を整備した。
本文出典:AI寒武紀
リスク提示および免責条項
市場にはリスクが伴い、投資は慎重に行うべきです。本記事は個別の投資助言を意図したものではなく、特定の投資目的や財務状況、ニーズを考慮したものではありません。読者は本記事の意見や見解、結論が自身の状況に適合するかどうかを判断し、投資の責任は自己負担です。