深度解析Nesa:あなたの日常で使うAIにプライバシー保護が必要な理由は何ですか?
このレポートはTiger Researchによって作成されており、多くの人が毎日AIを使用している一方で、そのデータの流れについて深く考えたことはないだろう。Nesaが提起した問いは:この問題に真正面から向き合ったとき、何が起こるのかということだ。
核心ポイント
- AIは日常生活に浸透しているが、ユーザーはデータが中央サーバーを通じてどのように伝送されているかを意識していない
- 米国CISAの代理局長さえ、知らぬ間に機密文書をChatGPTに漏らしてしまった
- Nesaは送信前のデータ変換(EE)とノード間分割(HSS-EE)を用いてこの流れを再構築し、いかなる単一の当事者も原始データを閲覧できないようにしている
- 学術認証(COLM 2025)や企業実運用(花王)によって、Nesaは先行優位性を築いている
- より広範な市場が従来の中央集権APIではなく、分散型プライバシーAIを選択するかどうかは依然として重要な課題である
1. あなたのデータは安全か?

出典:CISA
2026年1月、米国のサイバーセキュリティリーダー機関CISAの代理局長マドゥ・ゴットムッカラは、機密性の高い政府文書をChatGPTにアップロードした。目的は契約関連資料の要約と整理だった。
この漏洩はChatGPTによる検知もされず、OpenAIも政府に報告しなかった。代わりに、同機関の内部セキュリティシステムにより検知され、安全保障規約違反として調査が開始された。
米国の最高サイバーセキュリティ責任者ですら、日常的にAIを使用し、うっかり機密資料をアップロードしてしまう事例がある。
我々は知っている。ほとんどのAIサービスは、ユーザー入力を暗号化して中央サーバーに保存している。しかし、この暗号化は設計上、逆変換可能である。合法的な権限や緊急時には、データは解読・開示される可能性があり、ユーザーはその背後で何が起きているかを知らされていない。
2. 日常利用向けプライバシーAI:Nesa
AIはすでに日常の一部となっている—記事の要約、コードの作成、メールの下書きなど。最も懸念すべきは、前述のケースのように、機密文書や個人データさえも、ほとんどリスク意識なくAIに預けられている点だ。
根本的な問題は:これらすべてのデータがサービス提供者の中央サーバーを経由していることだ。たとえ暗号化されていても、復号鍵はサービス提供者が握っている。ユーザーはなぜこの仕組みを信頼できるのか?
ユーザーが入力したデータは、多様な経路を通じて第三者に露出する可能性がある:モデルの訓練、安全性の審査、法的要請などだ。企業版では、組織管理者がチャット履歴にアクセスできるし、個人版でも合法的な権限の下、データが移送されることもあり得る。

AIが日常生活に深く浸透した今、プライバシーの問題を真剣に見直す時期だ。
Nesaは、この構造を根本から変えるために生まれたプロジェクトだ。中央サーバーにデータを預けることなくAI推論を実現する分散型インフラを構築し、ユーザーの入力は暗号化された状態で処理される。どの単一ノードも原始データを見ることはできない。
3. Nesaはどう問題を解決するか
例として、ある病院がNesaを使うケースを想定しよう。医師はAIに患者のMRI画像を解析させて腫瘍を検出したいと考えている。従来のAIサービスでは、画像は直接OpenAIやGoogleのサーバーに送信される。
一方、Nesaを使えば、画像は医師のPCを離れる前にすでに数学的変換が完了している。
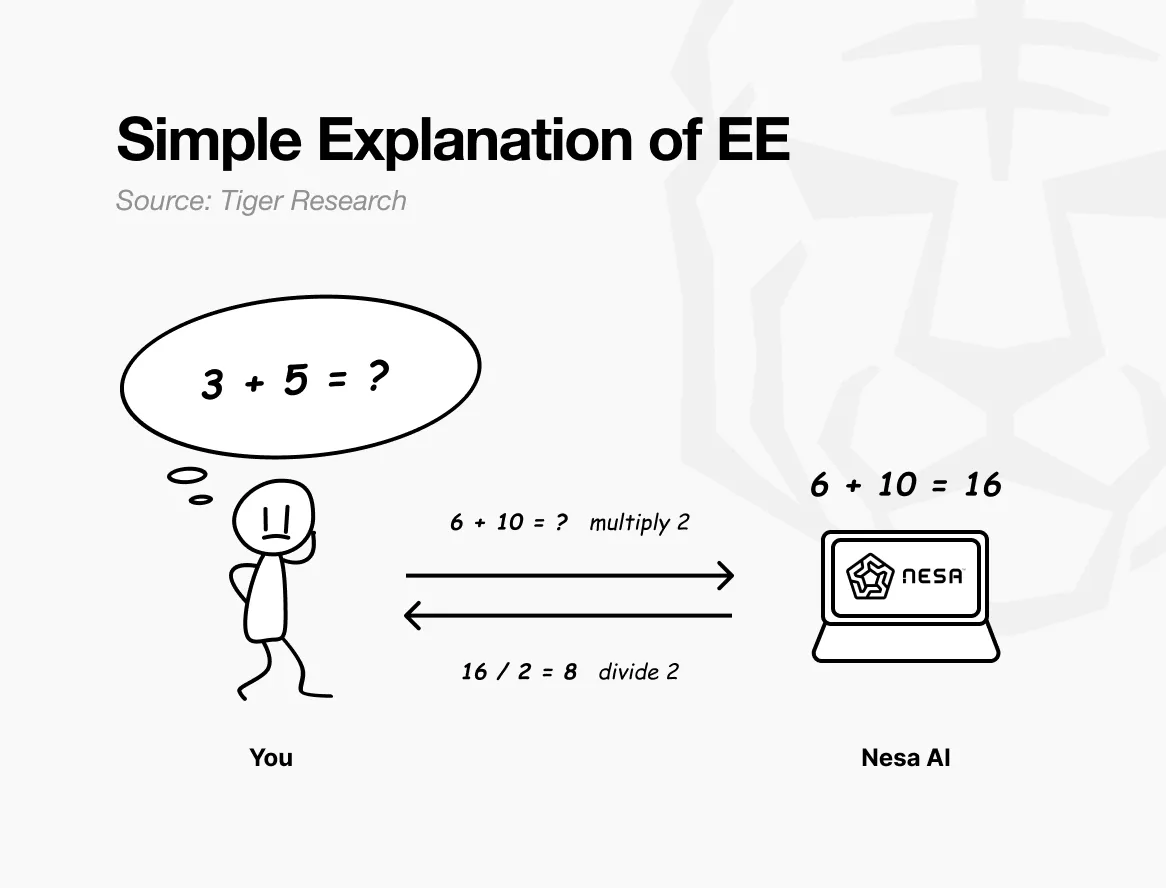
簡単な例え話をしよう。「3 + 5 = ?」という問題を送るとき、直接送信すれば、受信側は何を計算しているのか丸わかりだ。
しかし、送信前に各数字を2倍に変換すれば、受信側は「6 + 10 = ?」と見て、結果の16を返す。これを受けて、もとの数字に半分に戻せば8となり、元の問題の答えと一致する。計算は完了しているが、受信側は元の数字が3と5だったことを知らない。
これがNesaの等変加密(EE)の仕組みだ。データは送信前に数学的変換を受け、AIモデルは変換後のデータを計算する。
ユーザーは逆変換を適用して結果を得る。これにより、最終的な答えは元のデータと全く同じになる。この性質は数学的に「等変性」と呼ばれ、変換と計算の順序に関わらず結果が一致することを意味する。
実際の運用では、変換は単純な掛け算よりもはるかに複雑であり、AIモデルの内部計算構造に合わせて特別に設計されている。変換とモデルの処理が完璧に整合しているため、精度は損なわれない。
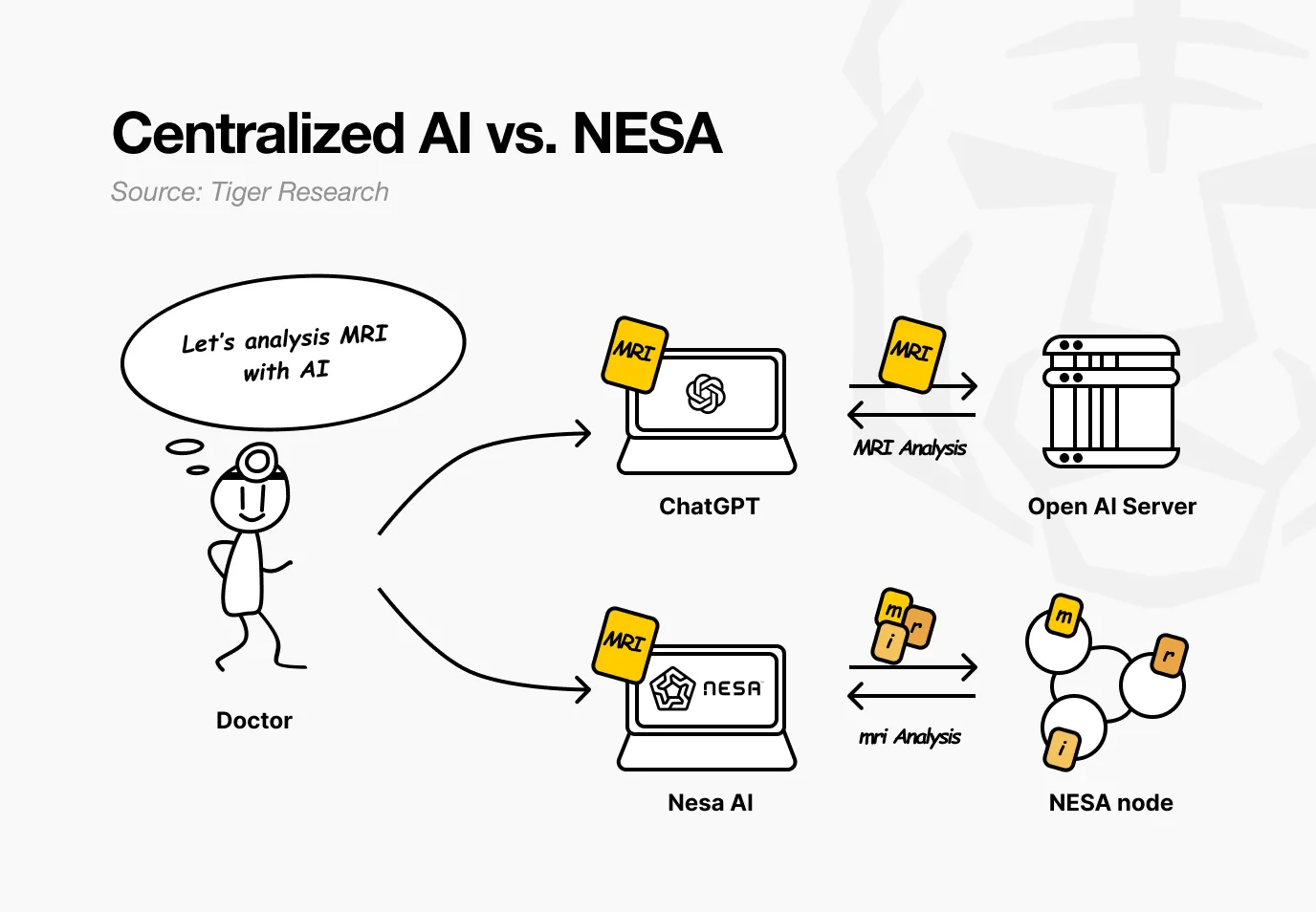
病院の例に戻ると、医師にとっては、画像をアップロードし結果を受け取るという一連の流れに変化はない。変わるのは、途中のどのノードも患者の原始MRIを見ることができなくなる点だ。
Nesaはさらに進化している。EEだけでもノードが原始データを見るのを防げるが、変換後のデータは依然として単一のサーバーに完全に存在している。
HSS-EE(暗号化埋め込み上の同型秘密分散)は、変換後のデータをさらに分割し、プライバシーを強化する。
先の例に戻ると、EEは送信前に掛け算ルールを適用することに相当し、HSS-EEは変換後の試験問題を二つに分割し、それぞれをノードAとノードBに送ることだ。
各ノードは自分の部分だけを解答し、全体の問題を見ることはできない。両方の部分の答えを合成したときにだけ、完全な結果が得られる。しかも、その合成操作は、元の送信者だけが行える。
要するに、EEはデータを変換し、原始内容が見えなくなるようにし、HSS-EEは変換後のデータをさらに分割して、どこにも完全な形で存在しない状態を作り出す。これにより、プライバシー保護は二重に強化される。
4. プライバシー保護はパフォーマンスを遅らせるか?
より強力なプライバシーは、一般的にパフォーマンスの低下を伴う—これは暗号学の長年の鉄則だ。最も有名な全同態暗号(FHE)は、標準的な計算に比べて10,000倍から1,000,000倍遅く、リアルタイムAIサービスには適用できない。
Nesaの等変加密(EE)は、異なるアプローチを採用している。数学的な例えを使えば、送信前に2倍にし、受信後に半分に戻すコストは微々たるものだ。
FHEが全問題をまったく異なる数学体系に変換するのに対し、EEは既存の計算基盤に軽量な変換層を追加するだけだ。
性能のベンチマークデータ:
- EE:LLaMA-8Bで遅延は約9%増加、精度は元モデルとほぼ同等、99.99%以上
- HSS-EE:LLaMA-2 7Bで推論1回あたり700〜850ミリ秒
さらに、MetaInfというメタ学習スケジューラが、全ネットワークの効率を最適化している。モデルサイズ、GPU仕様、入力特徴を評価し、最速の推論方法を自動選択する。
MetaInfは89.8%の選択精度を持ち、従来のMLセレクターより1.55倍高速だ。この成果はCOLM 2025のメイン会議で発表され、学術界からも高く評価された。
これらのデータは制御されたテスト環境での結果だが、実際の企業環境においてもNesaの推論インフラは稼働しており、実用レベルの性能を証明している。
5. どのように使われているか?

Nesaへのアクセスは三つの方法がある。
第一はPlayground。ウェブ上でモデルを選択・試用でき、開発経験は不要だ。入力から出力までの一連の流れを実体験できる。
これが、分散型AI推論の実態を最も早く理解できる方法だ。
第二はProサブスクリプション。月額8ドルで、無制限アクセス、月1,000回の高速推論ポイント、カスタムモデルの価格設定、モデル紹介ページの閲覧が可能。
個人開発者や小規模チームが自分のモデルを展開・収益化したい場合に最適だ。
第三はEnterprise企業版。公開価格はなく、カスタム契約となる。SSO/SAML対応、データ保存エリアの選択、監査ログ、細粒度アクセス制御、年間契約の請求などを含む。
最低料金は1ユーザーあたり月20ドルだが、規模に応じて交渉が必要。Nesaを社内AIワークフローに組み込みたい組織向けに、APIアクセスや組織管理機能を提供する。
要約すると、Playgroundは体験用、Proは個人・小規模チーム向け、Enterpriseは組織規模の導入向けだ。
6. なぜトークンが必要なのか?
分散型ネットワークには中央管理者がいない。サーバー運用や結果検証を行う主体は世界中に分散している。そうなると、なぜ誰かが自分のGPUを稼働させて他者のAI推論を処理し続けるのか、疑問が生じる。
答えは経済的インセンティブだ。Nesaネットワークでは、そのインセンティブとして$NESトークンが機能する。
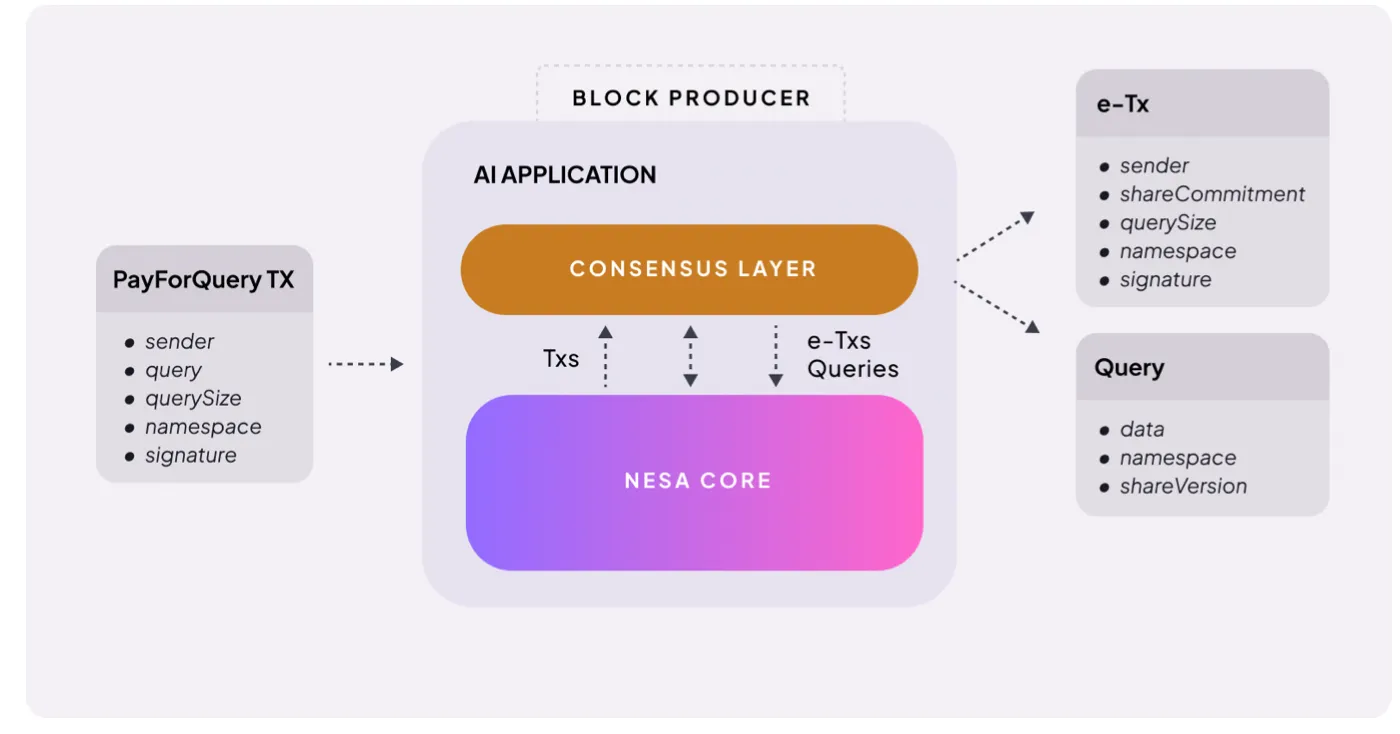
出典:Nesa
仕組みは非常にシンプルだ。ユーザーがAI推論リクエストを行うと、料金を支払う必要がある。NesaはこれをPayForQueryと呼び、取引ごとの固定料金と、データ量に比例した可変料金から構成される。
料金が高いほど優先的に処理される—これはブロックチェーンのガス代と同じ仕組みだ。
これらの料金はマイナーに渡される。ネットワークに参加するには、マイナーは一定量の$NESを担保(ステーク)し、リスクを取る必要がある。
誤った結果を返したり応答できなかった場合は、担保から罰金が差し引かれる。正確かつ迅速に処理すれば、より高い報酬を得られる。
$NESはまた、ガバナンスツールとしても機能する。トークン所有者は提案を提出し、料金構造や報酬比率などのネットワークの重要パラメータに投票できる。
要するに、$NESは三つの役割を果たす。推論リクエストの支払い手段、マイナーの担保と報酬、ネットワークガバナンスへの参加証明だ。トークンがなければノードは動かず、プライバシーAIは成り立たない。
ただし、トークン経済の運用には前提条件がある。
推論需要が十分に高まり、マイナーの報酬が成立し、マイナーが十分に残ることで、ネットワークの質が維持される。
これは需要駆動の供給と、供給が需要を支える好循環だが、そのスタート段階が最も難しい。
花王などの企業顧客が既に実運用環境でこのネットワークを使っていることは、良い兆候だ。しかし、ネットワーク拡大に伴い、トークン価値とマイニング報酬のバランスが維持できるかどうかは今後の課題だ。
7. プライバシーAIの必要性
Nesaが解決しようとする課題は明確だ:ユーザーがAIを使う際に、データが第三者に露出する構造的な問題を根本から変えること。
技術的基盤は堅牢で信頼できる。コアの暗号技術—等変加密(EE)とHSS-EE—は学術研究に由来し、推論最適化スケジューラMetaInfもCOLM 2025のメイン会議で発表済みだ。
これは単なる論文の引用ではなく、研究チームが直接プロトコルを設計し、ネットワークに実装したものだ。
分散型AIプロジェクトの中で、学術レベルで暗号原語の検証と、それを実運用インフラに展開した例はごく少数だ。花王など大手企業がこのインフラ上で推論を稼働させていることは、初期段階のプロジェクトにとって重要なシグナルだ。
ただし、制約も明確だ。
- 市場範囲:まずは企業顧客優先。一般ユーザーがプライバシーのために料金を払う可能性は低い
- 製品体験:PlaygroundはWeb3/投資ツールのようなUIであり、日常的なAIアプリケーションには向かない
- 規模検証:制御されたベンチマークと実運用の大規模並列環境は異なる
- 市場タイミング:プライバシーAIの需要は確かに存在するが、分散型プライバシーAIの需要は未だ検証段階。企業は依然として中央APIに慣れている
多くの企業は従来の中央APIを使い続けており、ブロックチェーン基盤のインフラ導入には高いハードルがある。
我々は今の時代に生きている。米国のサイバーセキュリティ責任者ですら、機密文書をAIにアップロードしている。プライバシーAIの需要はすでに存在し、今後も増え続けるだろう。
Nesaは学術的に裏付けられた技術と、実運用のインフラを持ち、そのニーズに応えられる。制約はあるものの、他のプロジェクトよりも一歩先を行っている。
真のプライバシーAI市場が開かれるとき、Nesaは最も早く名前が挙がる一つになるだろう。