Introdução: por que a IA está revalorizando o papel do armazenamento na infraestrutura cripto

Fonte da imagem: Página do mercado Gate
Até 2026, os preços de armazenamento e tráfego de saída — tanto em nuvem quanto em soluções autogerenciadas — seguem em alta. Com o crescimento exponencial de datasets de IA, bancos de dados vetoriais e logs de inferência, “preço unitário por GB” e “taxas de sincronização entre regiões” voltam a ser prioridade nos relatórios semanais de CFOs e líderes de infraestrutura. Nesse cenário, o sentimento do mercado é altamente sensível à “oferta alternativa”: ativos de armazenamento descentralizado como STORJ registraram picos expressivos no curto prazo, transformando antigas questões estruturais em hotspots de negociação. A questão central não são as oscilações diárias de preço, mas sim: à medida que empresas arcam com custos elevados para retenção de longo prazo de modelos e Agentes, por que o mercado passa a esperar soluções de armazenamento on-chain, verificáveis ou baseadas em DePIN?
É fundamental esclarecer: “armazenamento” na criptoeconomia não é um produto único. Pode significar arquivamento web permanente e modelos de segurança econômica, armazenamento de objetos quase em tempo real com hierarquização hot-cold, ou apenas um módulo dentro de um stack (ao lado de mercados de Taxa de hash e Data Availability, DA). As seções seguintes categorizam projetos e roadmaps por tipo de problema, evitando confundir camadas tecnológicas distintas em uma única narrativa de “token de armazenamento” e separando volatilidade de preço de fatores como disponibilidade, SLA, compliance e TCO de longo prazo.
Demandas em camadas: dados de treinamento, ativos de modelo, estado de Agente e auditoria de compliance
Antes de analisar projetos específicos, utilize a estrutura em camadas abaixo para direcionar o foco:
-
Congelamento de versões para dados de treinamento e avaliação
- É preciso garantir imutabilidade de longo prazo e auditabilidade pública via cadeia de timestamp?
- Um custo único de gravação mais alto é aceitável para reduzir riscos futuros de disputa?
-
Gestão do ciclo de vida de pesos de modelos e saídas intermediárias
- O objetivo é arquivamento e backup (leituras esporádicas) ou carregamento online para inferência (sensível à latência)?
- É necessário controle por contrato on-chain para renovações, listas de acesso e liquidação?
-
Estado de Agente e sessão
- É preciso autorização programável (por exemplo, por chamador, tarefa ou janela de tempo)?
- Para atualizações de estado frequentes, camadas KV ou mutáveis são mais práticas do que blobs permanentes puros.
-
Aquisição empresarial e compliance
- Compradores consultam sobre SLA, região, criptografia e Gestão de Chave, formatos de prova verificáveis e cobrança de tráfego de saída.
- Soluções descentralizadas que priorizam apenas quantidade de nós, mas sem SLOs mensuráveis, terão baixa adesão empresarial.
Esses quatro aspectos determinam se a avaliação deve priorizar camadas permanentes como Arweave, nuvens verificáveis como Filecoin Onchain Cloud, armazenamento de objetos programável como Walrus/Akave ou módulos full-stack como 0G, que integra armazenamento em uma arquitetura de chain nativa de IA.
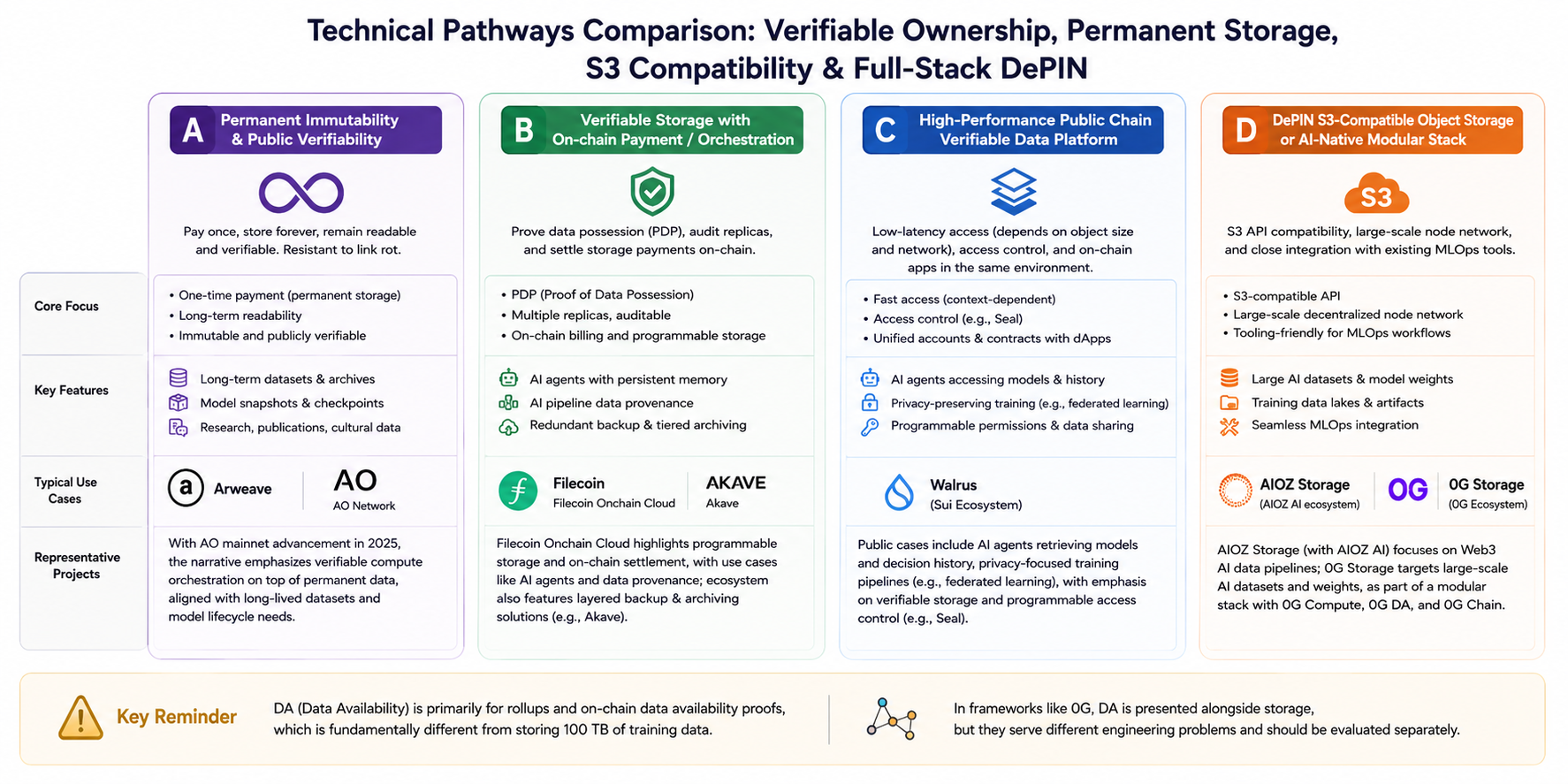
Para comparação direta, essas rotas podem ser agrupadas em quatro categorias (com eventuais sobreposições, mas focos narrativos distintos):
Rota A: Imutabilidade permanente e reprodutibilidade pública
- Palavras-chave: pagamento único, leitura de longo prazo, combate ao link rot.
- Exemplo: Arweave. Após o lançamento do mainnet AO em 2025, a narrativa do ecossistema foca na orquestração de computação verificável sobre dados permanentes, atendendo à necessidade de alinhamento de datasets e snapshots de modelos de longo prazo.
Rota B: Armazenamento verificável com pagamento/contrato on-chain
- Palavras-chave: PDP (Proof of Data Possession), auditabilidade multi-réplica, cobrança on-chain.
- Exemplo: Filecoin Onchain Cloud. A documentação destaca armazenamento programável e liquidação on-chain, com cenários como armazenamento persistente gerenciado por AI Agent e proveniência de dados em pipelines de IA. O ecossistema também inclui backup e arquivamento em camadas, com produtos como Akave.
Rota C: Plataformas de dados verificáveis em blockchains públicas de alta performance
- Palavras-chave: leituras de baixa latência (dependendo do tamanho do objeto e da rede), controle de acesso (ex: Seal), contas e contratos unificados com apps on-chain.
- Exemplo: Walrus (ecossistema Sui). Casos oficiais e de parceiros incluem armazenamento de histórico de modelo e decisões de AI Agent, trilhas de treinamento com foco em privacidade (como aprendizado federado), com ênfase em permissões verificáveis e programáveis.
Rota D: Armazenamento de objetos compatível com S3 habilitado por DePIN ou componente modular nativo de IA
- Palavras-chave: API S3, escala de rede de nós, integração fluida com ferramentas MLOps existentes.
- Exemplos: AIOZ Storage (ao lado de AIOZ AI no pipeline de dados Web3 AI); 0G Storage na documentação 0G, que atua como camada de armazenamento para grandes datasets de IA e pesos de modelos, compondo um stack modular com 0G Compute, 0G DA e 0G Chain.
Distinção importante: DA (Data Availability) atende principalmente rollups e provas de disponibilidade de dados on-chain. Armazenar “100 TB de dados de treinamento” é outro desafio de engenharia; porém, em frameworks full-stack como 0G, DA e armazenamento são apresentados juntos e devem ser avaliados separadamente.
Visão geral de projetos representativos (classificados por rota)
As entradas a seguir são baseadas em roteiros públicos e blogs oficiais, não estão ordenadas por valor de mercado ou desempenho de token e não constituem recomendação de investimento.
Camada permanente: Arweave e ecossistema AO
- Posicionamento: Foco em permaweb e leitura de longo prazo, ideal para snapshots de modelos e datasets, ciência aberta e publicação resistente à censura.
- Integração com IA: Mais voltada para cadeias de evidências e reprodutibilidade do que para leituras de baixa latência garantidas.
- Pontos de avaliação: Economia de gravação, disponibilidade de gateways e dependência de caminhos de leitura em provedores de gateway específicos.
Nuvem verificável: Filecoin Onchain Cloud e produtos de camada superior como Akave
- Posicionamento: Produto de posse verificável, estratégias de réplica e pagamento on-chain para backup empresarial, arquivamento de compliance e pipelines auditáveis.
- Integração com IA: Materiais públicos destacam automação por Agentes para armazenamento e proveniência de pipelines de treinamento/inferência.
- Pontos de avaliação: Escala de datasets e casos de clientes, custo de integração de ferramentas de prova, desempenho entre regiões.
Plataforma de dados verificável: Walrus
- Posicionamento: Focada em verificabilidade, programabilidade e controle de privacidade (ex: Seal), integrada ao ecossistema de apps Sui.
- Integração com IA: Parcerias do ecossistema abrangem ciclo de vida de dados de Agentes e colaborações em treinamento de privacidade.
- Pontos de avaliação: Latência por tamanho de objeto, limites de criptografia e Gestão de Chave, profundidade de integração.
Armazenamento de objetos DePIN: AIOZ Storage e outros
- Posicionamento: Compatível com S3, ênfase em escala de nós e migração sem atrito.
- Integração com IA: Alinhamento direto com práticas de engenharia como hospedagem de datasets e distribuição de artefatos.
- Pontos de avaliação: Comparação justa de custos com nuvem centralizada exige mesmas premissas de região, tier hot/cold e egress.
Full-stack modular: 0G
- Posicionamento: Integra armazenamento, Taxa de hash, DA e chain como módulos sob uma visão unificada de deAIOS/AI L1.
- Integração com IA: Documentação destaca alto throughput, camada de armazenamento para pesos e logs, e camada KV para embeddings e estado de Agentes.
- Pontos de avaliação: Se a maturidade de cada módulo acompanha o gargalo mais crítico (frequentemente Taxa de hash ou pipeline de dados).
Outros projetos frequentemente citados, mas não focados em armazenamento
- Fluence e outros projetos de GPU/Taxa de hash descentralizada: Muitas vezes citados em discussões “IA + DePIN”, mas não devem ser classificados como infraestrutura de armazenamento, salvo se oferecerem explicitamente SLA de armazenamento de objetos em larga escala.
Realidades de adoção e principais riscos: engenharia, modelos econômicos e compliance regulatório
Mesmo com narrativas alinhadas à IA, três restrições principais permanecem para implementação:
-
Restrições de engenharia: latência, consistência e toolchains
- Sistemas distribuídos frequentemente exigem middleware extra para arquivos pequenos, alta QPS, sincronização entre regiões e uploads resumíveis.
- “Descentralização” não significa automaticamente menor custo; o TCO para arquivamento cold e leituras hot precisa ser comparado.
-
Restrições de modelo econômico: incentivos de token e pagamento real
- Muitas redes incentivam tanto mineradores/nós quanto usuários finais.
- A volatilidade do preço do token afeta retenção de provedores, impactando disponibilidade e qualidade do serviço no longo prazo.
-
Compliance e governança de dados: chaves, fronteiras e direitos autorais
- Datasets de IA frequentemente envolvem direitos autorais e informações pessoais; verificabilidade on-chain não resolve sozinha questões legais de origem.
- Clientes empresariais questionam custódia de chaves, direito de exclusão e residência dos dados: há tensão inerente entre armazenamento permanente e “direito ao esquecimento”, exigindo alinhamento entre produto e jurídico.
A narrativa “IA + Armazenamento” está em alta, mas a usabilidade real depende da clareza sobre workloads: se os objetos são para arquivamento cold ou leitura hot; SLOs para throughput e latência; como responsabilidades de chave e compliance são implementadas contratualmente; e se incentivos de token estão alinhados ao pagamento real. As quatro rotas em camadas (camada permanente, nuvem verificável, armazenamento de objetos on-chain e armazenamento modular full-stack) podem coexistir, mas não são intercambiáveis: camada permanente é forte em consistência de longo prazo e replay público; nuvens verificáveis se destacam em cobrança e orquestração; soluções compatíveis com S3 reduzem custos de migração; e abordagens modulares full-stack oferecem narrativa all-in-one, mas exigem validação de maturidade de cada módulo.
O filtro final é direto: primeiro, verifique se uso verificável e casos de clientes sustentam a narrativa; depois compare TCO e latência em bases iguais; e só então discuta tokens e valuation. Assim, minimiza-se equívocos comuns como tratar DA como “armazém de corpus” ou projetos de Taxa de hash como “infraestrutura de armazenamento”.
Isenção de responsabilidade: Este artigo compila informações técnicas e do setor e não constitui qualquer forma de aconselhamento de investimento. Detalhes sobre fases de mainnet, parceiros e métricas de desempenho podem ser atualizados oficialmente. Consulte sempre os whitepapers, documentações e divulgações de auditoria mais recentes das equipes de cada projeto.








