在区块链系统中,智能合约无法直接访问链下金融市场数据,因此需要依赖“预言机(Oracle)”作为数据桥梁。Pyth Network 正是在这一需求下构建的金融数据网络,其目标是提供高频、低延迟且来源可靠的市场价格信息。
与一般预言机不同,Pyth 的数据并非来自二次市场抓取,而是直接来自交易所、做市商与金融机构等第一方数据提供者。这种结构使其更接近真实市场形成机制,因此在衍生品定价与高频交易场景中具有更强适配性。
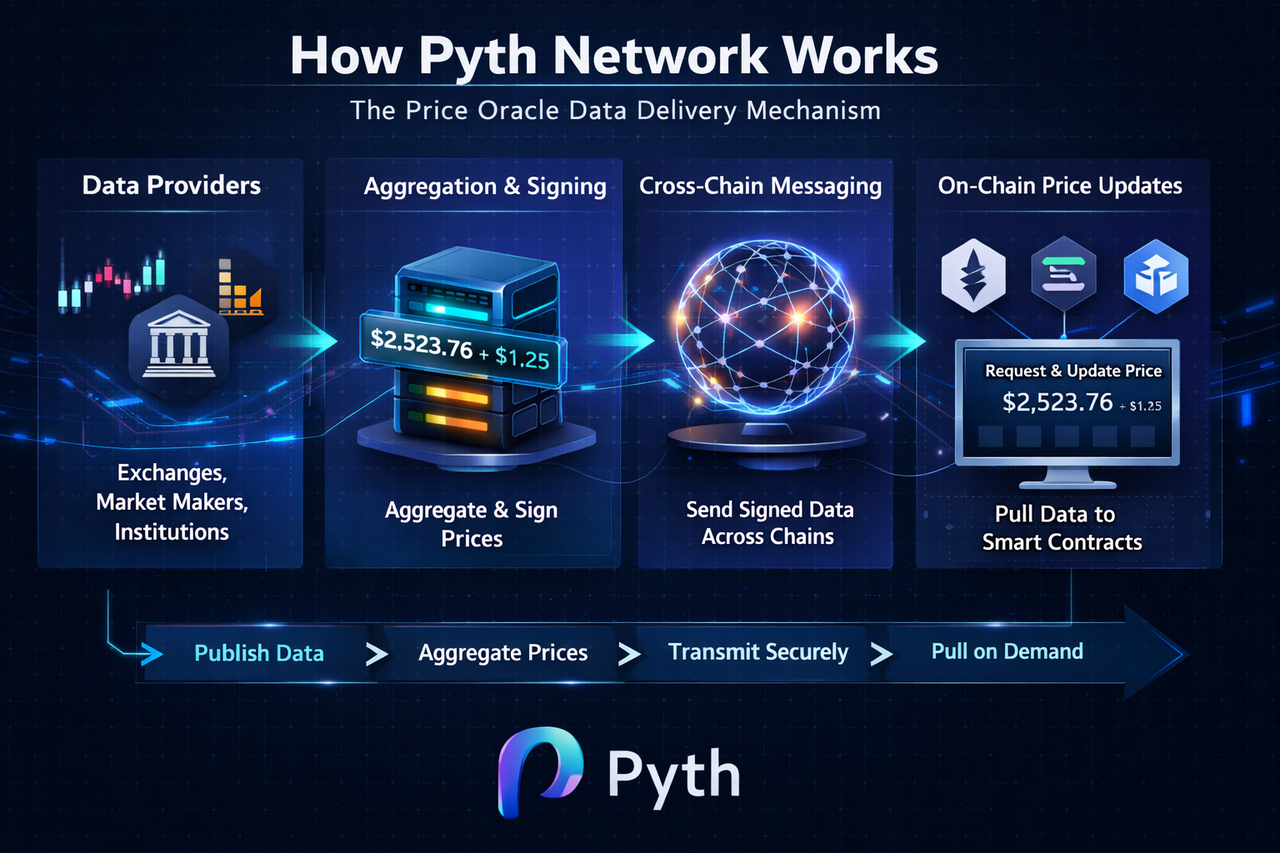
Pyth Network 的整体运作框架
Pyth 的系统可以理解为一个从“数据产生 → 数据处理 → 数据分发”的三层结构,但这一过程并非单一链上完成,而是链下与链上协同运行。
数据首先由多个独立机构提供,这些机构直接提交资产价格及其波动区间。随后,这些数据进入网络的聚合层进行处理,最终生成统一的标准价格,并在需要时被传输到不同区块链上供智能合约使用。
这种设计的关键特点在于:价格生成与价格使用是解耦的。
Pyth Network 的数据来源:第一方市场数据输入
Pyth Network 的基础是多源数据输入机制。参与者包括交易所、做市商以及金融机构,它们直接向网络提交实时市场价格。
每条数据不仅包含价格本身,还会附带一个“置信区间”,用于表达该价格的波动范围。这一设计使系统能够在数据质量不一致时仍然保持一定的稳健性。
由于数据来自交易行为的直接参与者,因此 Pyth 在数据延迟与真实性方面相较传统聚合型预言机更接近原始市场状态。
Pyth Network 的数据聚合:从分散报价到统一价格
当多个数据提供者提交价格后,系统会在链下对这些信息进行标准化处理。该过程通常包括异常值过滤、加权计算以及置信区间整合。
最终输出的是一个统一的市场价格,以及对应的波动范围。这一结果会被写入 Pyth 网络的运行状态中,并作为后续链上调用的标准数据源。
这一阶段的核心意义在于,将“多个市场视角”转化为“单一可信价格”。
Pyth Network 的核心机制:Pull Oracle 的运行方式
Pyth Network 最关键的设计是 Pull Oracle(拉取式预言机)机制。
与传统预言机持续向链上推送数据不同,Pyth 不会主动将所有更新写入区块链,而是将高频价格保留在链下系统中。当智能合约需要最新价格时,才会发起请求并触发数据上链。
这种方式使得链上更新从“持续成本”变为“按需成本”,显著降低了 Gas 消耗,同时允许更高频率的数据更新在链下进行。
在实际运行中,一笔交易通常会同时完成两个动作:获取最新价格,并使用该价格执行逻辑。
Pyth Network 的数据传输路径:从链下到多链系统
Pyth 的数据传输并不是单一链的过程,而是跨链分发结构。
首先,价格在链下持续更新并完成聚合,然后生成经过签名的标准化数据包。该数据包随后通过跨链通信机制分发到不同区块链网络,例如以太坊或 Solana。
当智能合约调用价格时,系统验证数据签名的有效性,并读取最新价格信息,从而完成一次完整的数据使用过程。
这一机制使 Pyth 能够作为“多链共享数据层”存在,而非单一链服务组件。
Pyth Network 的Push 与 Pull 模型的关键差异
传统预言机通常采用 Push 模型,即定期向链上广播价格更新。这种方式虽然简单,但在高频场景下会带来较高的链上成本。
Pyth 采用的 Pull 模型则将更新逻辑转移到用户侧,由使用者在需要时触发数据读取。链下更新频率可以非常高,但链上仅在必要时发生交互。
从系统结构来看,这种方式在扩展性和成本控制上具有明显优势。
Pyth Network 在 DeFi 生态中的作用
Pyth 提供的高频价格数据广泛应用于去中心化金融系统,例如衍生品定价、借贷抵押物估值以及自动清算机制。
在这些场景中,价格延迟可能直接影响风险控制逻辑,因此对数据实时性要求较高。Pyth 的设计通过减少链上延迟,使智能合约能够更接近真实市场价格进行决策。
总结
Pyth Network 的核心创新在于将预言机从“持续推送数据”的结构转变为“链下高频更新 + 链上按需读取”的模式。这一设计不仅降低了链上成本,还提高了数据更新频率与跨链扩展能力。
通过数据采集、链下聚合、签名验证与跨链分发的组合流程,Pyth 构建了一个面向多链生态的高性能金融数据基础设施,并在 DeFi 应用中承担关键的价格信息层角色。
FAQ
Pyth Network 的价格是如何形成的?
价格由多个独立金融机构提交的数据经过链下聚合计算生成,并附带置信区间以衡量数据波动范围。
为什么 Pyth 使用 Pull 机制?
Pull 机制可以避免持续链上更新带来的高成本,同时允许更高频率的链下数据更新,提高系统整体效率。
Pyth 的数据是实时的吗?
链下数据更新频率接近实时,但链上读取取决于用户触发交易的时机,因此表现为“按需实时”。
Pyth 如何确保数据可靠性?
通过多源数据交叉验证、异常值过滤以及签名验证机制,提升数据一致性与安全性。
Pyth 与传统预言机的主要区别是什么?
主要区别在于数据分发模式(Push vs Pull)、成本结构以及跨链扩展能力。
Pyth 是否支持多链使用?
支持,其数据可通过跨链机制在多个区块链网络中验证与使用。
分享
目录


相关文章

Master Protocol:激活 BTC 生息潜力

CKB:闪电网络促新局,落地场景需发力

链上数据分析:六个分析工具介绍及使用案例

