Analyse approfondie de Nesa : pourquoi l'IA que vous utilisez quotidiennement a-t-elle besoin de protection de la vie privée ?
Ce rapport a été rédigé par Tiger Research. La majorité des gens utilisent l’IA quotidiennement sans jamais se demander où vont leurs données. La question posée par Nesa est : que se passe-t-il lorsque vous commencez à prendre cette problématique au sérieux ?
Points clés
- L’IA est intégrée dans la vie quotidienne, mais les utilisateurs ignorent souvent comment leurs données transitent via des serveurs centraux
- Même un agent de CISA, agence de cybersécurité américaine, a accidentellement divulgué des documents confidentiels à ChatGPT sans le savoir
- Nesa a reconstruit ce processus en utilisant la transformation de données avant transmission (EE) et la division inter-nœuds (HSS-EE), garantissant qu’aucune partie unique ne peut voir les données brutes
- La certification académique (COLM 2025) et le déploiement industriel (Procter & Gamble) donnent à Nesa un avantage pionnier
- La question cruciale reste : le marché adoptera-t-il une IA décentralisée axée sur la confidentialité plutôt que l’API centralisée habituelle ?
1. Vos données sont-elles en sécurité ?

Source : CISA
En janvier 2026, Madhu Gottumukkala, directeur par intérim de l’agence de cybersécurité américaine CISA, a téléchargé des documents sensibles du gouvernement sur ChatGPT, simplement pour résumer et organiser des documents contractuels.
Cette fuite n’a pas été détectée par ChatGPT, et OpenAI n’en a pas informé le gouvernement. Elle a été repérée par le système de sécurité interne de l’agence, ce qui a déclenché une enquête pour violation des protocoles de sécurité.
Même le plus haut responsable américain en cybersécurité utilise l’IA au quotidien, et a accidentellement téléchargé des documents confidentiels.
Nous savons tous que la majorité des services d’IA stockent les entrées utilisateur de façon cryptée sur des serveurs centraux. Mais cette cryptographie est conçue pour être réversible. En cas d’autorisation légale ou d’urgence, les données peuvent être décryptées et divulguées, sans que l’utilisateur en ait conscience.
2. IA privée pour un usage quotidien : Nesa
L’IA est devenue une partie intégrante de la vie quotidienne — résumer des articles, coder, rédiger des emails. Ce qui est réellement préoccupant, c’est que, comme dans le cas précédent, même des documents confidentiels et des données personnelles sont confiés à l’IA sans que les utilisateurs en aient conscience ou mesurent le risque.
Le problème central : toutes ces données transitent par des serveurs centraux des fournisseurs de services. Même si elles sont cryptées, la clé de déchiffrement appartient au fournisseur. Pourquoi les utilisateurs devraient-ils faire confiance à ce système ?
Les données entrées par l’utilisateur peuvent être exposées à des tiers par divers moyens : entraînement de modèles, vérifications de sécurité, demandes légales. En version entreprise, l’administrateur peut accéder aux logs de chat ; en version personnelle, les données peuvent également être transférées sous autorisation légale.

Étant donné que l’IA est désormais profondément intégrée dans la vie quotidienne, il est temps d’examiner sérieusement la question de la confidentialité.
Nesa a été conçu précisément pour changer radicalement cette architecture. Il construit une infrastructure décentralisée permettant l’inférence IA sans confier les données à un serveur central. Les entrées utilisateur sont traitées en cryptage, et aucun nœud unique ne peut voir les données brutes.
3. Comment Nesa résout-il ces problèmes ?
Imaginez un hôpital utilisant Nesa. Le médecin souhaite que l’IA analyse une IRM pour détecter une tumeur. Dans le service actuel, l’image est envoyée directement aux serveurs d’OpenAI ou de Google.
Avec Nesa, l’image est mathématiquement transformée avant de quitter l’ordinateur du médecin.
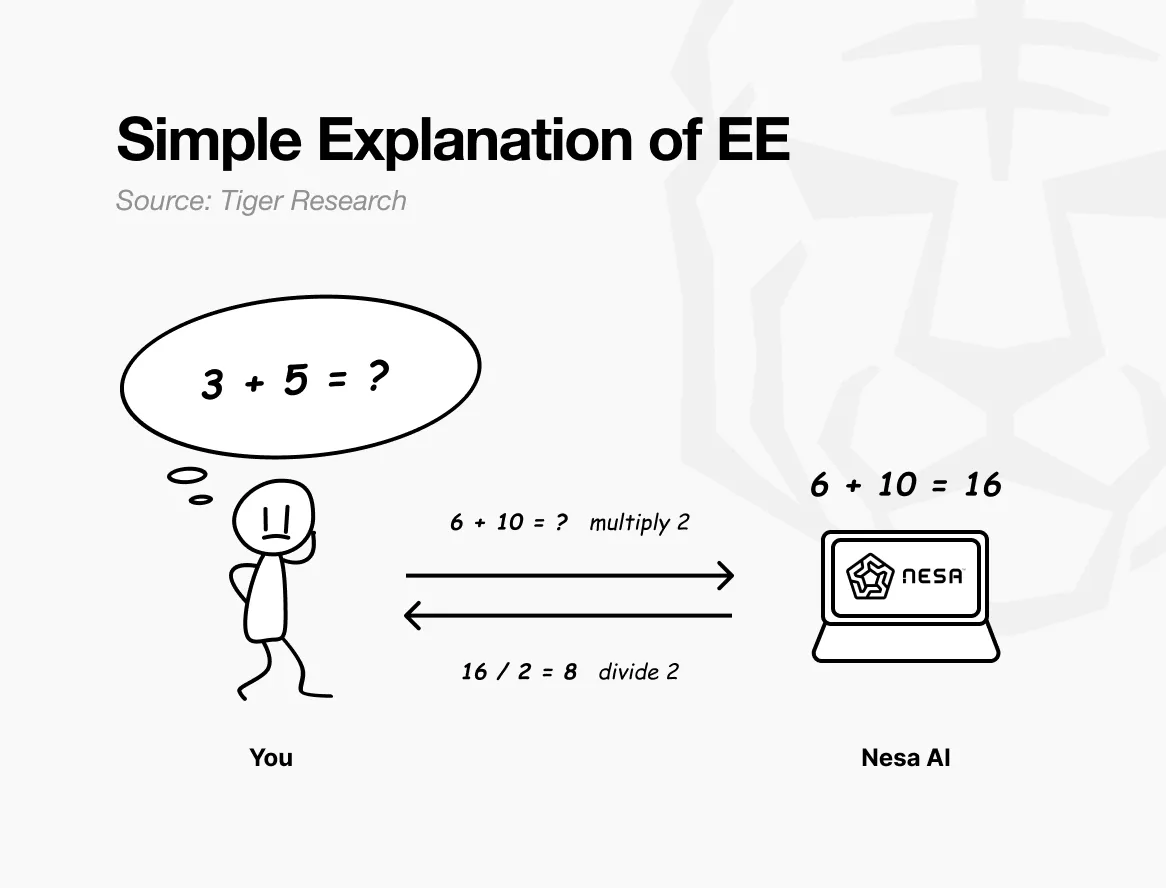
Pour faire simple : si le problème initial est “3 + 5 = ?”, l’envoyer tel quel permettrait au récepteur de connaître la question.
Mais si, avant l’envoi, chaque chiffre est multiplié par 2, le récepteur voit “6 + 10 = ?” et renvoie 16. En divisant par 2, le médecin retrouve 8 — résultat identique à celui de la question initiale. Le calcul est effectué sans que le récepteur ne sache que les chiffres initiaux étaient 3 et 5.
C’est précisément ce que permet la cryptographie équivariante (EE) de Nesa. Les données sont transformées mathématiquement avant transmission, et le modèle IA opère sur ces données transformées.
L’utilisateur peut appliquer une transformation inverse pour obtenir le résultat, identique à celui obtenu avec les données originales. En mathématiques, cette propriété s’appelle l’équivariance : que l’on transforme puis calcule, ou calcule puis transforme, le résultat final reste le même.
En pratique, la transformation est bien plus complexe qu’une simple multiplication — elle est spécialement conçue pour s’aligner parfaitement avec la structure interne du modèle IA. Grâce à cette correspondance, la précision n’est pas affectée.
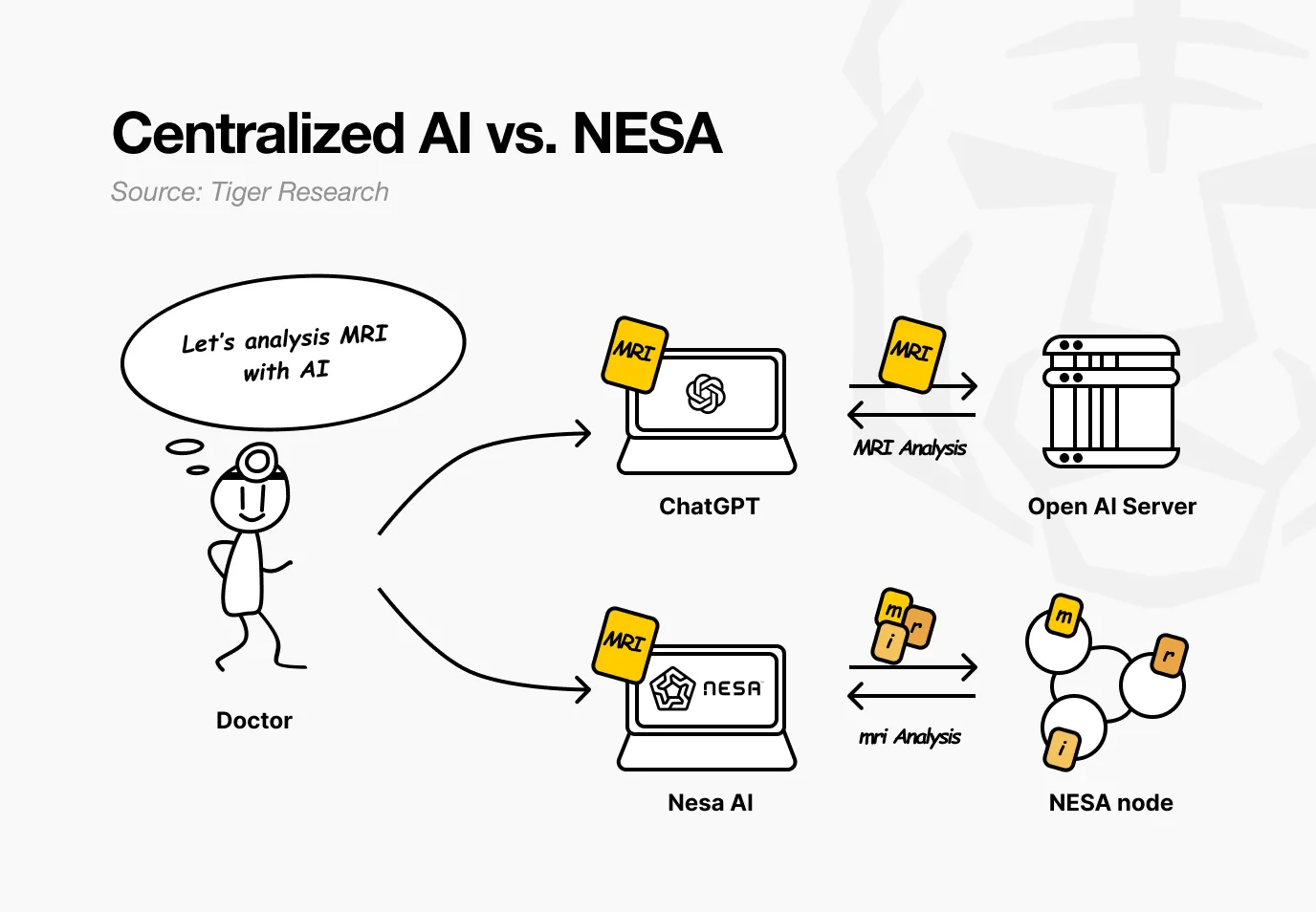
Reprenons le scénario hospitalier. Pour le médecin, tout reste identique : il upload l’image, reçoit le résultat, tout comme avant. La différence : aucun nœud intermédiaire ne peut voir l’IRM brute du patient.
Nesa va encore plus loin. La cryptographie EE empêche déjà chaque nœud de voir les données brutes, mais la donnée transformée reste stockée intégralement sur un seul serveur.
HSS-EE (partage secret homomorphe sur l’intégration cryptée) va encore plus loin en divisant la donnée transformée en plusieurs parts.
Reprenons l’analogie précédente : la cryptographie EE, c’est comme si on pliait une copie d’examen avant de l’envoyer ; HSS-EE, c’est comme si on déchirait cette copie en deux, en envoyant une moitié à un nœud A, l’autre moitié à un nœud B.
Chaque nœud ne peut répondre qu’à sa propre partie, sans voir l’ensemble. Ce n’est qu’en combinant les deux réponses qu’on peut obtenir le résultat complet — et seul l’expéditeur initial peut faire cette fusion.
En résumé : EE transforme les données pour rendre leur contenu incompréhensible ; HSS-EE divise encore cette donnée transformée pour qu’elle ne soit jamais visible dans sa totalité nulle part. La protection de la vie privée est ainsi renforcée par une double couche.
4. La protection de la vie privée ralentira-t-elle la performance ?
Plus la confidentialité est forte, plus le traitement sera lent — c’est une règle bien connue en cryptographie. La cryptographie homomorphe entièrement (FHE) est 10 000 à 1 000 000 de fois plus lente que le calcul classique, ce qui la rend inapplicable pour des services IA en temps réel.
Nesa utilise une approche différente avec la cryptographie équivariante (EE). En termes simples : multiplier par 2 avant l’envoi, diviser par 2 après réception, cela coûte presque rien.
Contrairement à FHE, qui convertit tout le problème dans un système mathématique radicalement différent, EE ajoute une couche de transformation légère sur la base de calculs existants.
Données de référence :
- EE : sur LLaMA-8B, le délai augmente de moins de 9 %, la précision reste identique, avec un taux de réussite supérieur à 99,99 %
- HSS-EE : sur LLaMA-2 7B, chaque inférence prend entre 700 et 850 ms
De plus, le MetaInf, un ordonnanceur d’apprentissage automatique, optimise encore l’efficacité globale. Il évalue la taille du modèle, la configuration GPU, et les caractéristiques d’entrée pour choisir automatiquement la méthode d’inférence la plus rapide.
MetaInf atteint une précision de sélection de 89,8 %, et accélère la vitesse par rapport à un sélecteur ML traditionnel de 1,55 fois. Ces résultats ont été présentés lors du COLM 2025, et ont été salués par la communauté académique.
Ces chiffres proviennent d’un environnement de test contrôlé. Mais l’essentiel est que l’infrastructure d’inférence de Nesa est déjà déployée dans des environnements industriels, validant ses performances en conditions réelles.
5. Qui l’utilise ? Comment ?

Il existe trois façons d’accéder à Nesa.
Première option : Playground. L’utilisateur peut tester directement via une interface web, sans besoin de compétences en développement. Vous pouvez expérimenter la saisie de données, voir les résultats de différents modèles, tout en découvrant le fonctionnement de l’inférence décentralisée.
C’est la façon la plus rapide de comprendre concrètement comment fonctionne une IA décentralisée.
Deuxième option : abonnement Pro. 8 dollars par mois, avec accès illimité, 1 000 crédits d’inférence rapide par mois, contrôle des prix pour la personnalisation de modèles, et une page dédiée aux modèles.
Ce forfait s’adresse aux développeurs individuels ou petites équipes souhaitant déployer et monétiser leurs propres modèles.
Troisième option : version Entreprise. Ce n’est pas une tarification standard, mais un contrat sur mesure. Inclut SSO/SAML, options de stockage, logs d’audit, contrôle d’accès granulaire, facturation annuelle.
Le prix de départ est de 20 dollars par utilisateur par mois, mais les modalités exactes sont négociables selon la taille de l’organisation. Conçue pour intégrer Nesa dans des flux internes, cette version offre une API et une gestion organisationnelle via un accord dédié.
Résumé : Playground pour découvrir, Pro pour développer, Enterprise pour déployer à l’échelle.
6. Pourquoi un token ?
Le réseau décentralisé n’a pas de gestionnaire central. Les serveurs et la validation des résultats sont répartis dans le monde entier. La question qui en découle : pourquoi quelqu’un accepterait-il de faire tourner son GPU en permanence pour traiter l’IA des autres ?
La réponse : la motivation économique. Sur le réseau Nesa, cette motivation, c’est le jeton $NES.
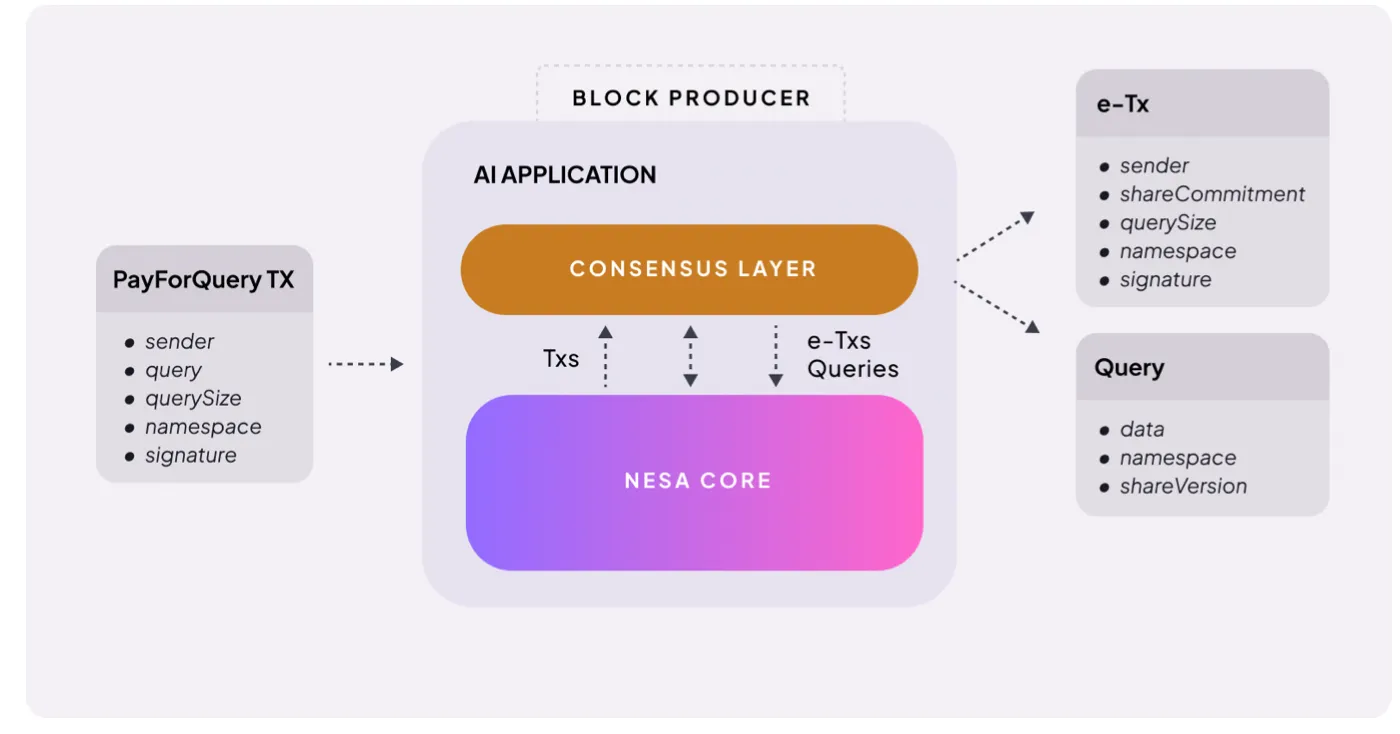
Source : Nesa
Le mécanisme est simple. Lorsqu’un utilisateur demande une inférence IA, il doit payer. Nesa appelle cela PayForQuery, une combinaison d’un coût fixe par transaction et d’un coût variable proportionnel à la quantité de données.
Plus le coût est élevé, plus la priorité de traitement l’est aussi — comme la gas dans la blockchain.
Ces frais sont versés aux mineurs. Pour participer, ils doivent staker une certaine quantité de $NES — en risquant leurs tokens avant d’être assignés à une tâche.
Si un mineur fournit une réponse erronée ou ne répond pas, sa mise est pénalisée. S’il répond vite et juste, il reçoit une récompense plus importante.
Le $NES sert aussi à la gouvernance. Les détenteurs peuvent soumettre des propositions pour faire évoluer la structure des frais, les récompenses, ou d’autres paramètres du réseau.
En résumé, le $NES a trois rôles : paiement pour l’inférence, garantie de participation via staking, et gouvernance du réseau. Sans token, pas de nœuds ; sans nœuds, pas d’IA privée.
Il faut aussi noter que la viabilité économique repose sur certains prérequis :
- La demande d’inférence doit être suffisante pour motiver les mineurs ;
- Les récompenses doivent être attractives pour retenir les participants ;
- Un nombre suffisant de mineurs est nécessaire pour assurer la qualité du réseau.
C’est un cercle vertueux : la demande stimule l’offre, et l’offre maintient la demande — mais le démarrage reste le défi majeur.
Les clients industriels comme P&G ont déjà déployé cette infrastructure en production, ce qui est un signe positif. Mais la question de l’équilibre entre la valeur du token et la récompense des mineurs reste ouverte, surtout à grande échelle.
7. La nécessité d’une IA privée
Nesa cherche à répondre à une problématique claire : changer la structure qui expose les données des utilisateurs à des tiers lors de l’utilisation de l’IA.
Les bases technologiques sont solides. La cryptographie utilisée — EE et HSS-EE — provient de recherches académiques. Le scheduler d’optimisation d’inférence MetaInf a été présenté lors du COLM 2025.
Ce n’est pas une simple citation d’articles. L’équipe a conçu et implémenté ces protocoles dans le réseau.
Très peu de projets décentralisés d’IA ont pu à la fois valider leurs primitives cryptographiques en académique et déployer une infrastructure opérationnelle. Des grands comme P&G ont déjà lancé des inférences sur cette infrastructure — un signal fort pour un projet en phase initiale.
Mais il faut aussi reconnaître ses limites :
- Marché : principalement pour les clients institutionnels ; les utilisateurs individuels ne sont pas encore prêts à payer pour la confidentialité
- Expérience utilisateur : Playground ressemble davantage à une interface Web3 ou d’investissement qu’à une application IA quotidienne
- Validation à grande échelle : les tests contrôlés ne remplacent pas un déploiement avec plusieurs milliers de nœuds en production
- Timing du marché : la demande pour une IA privée existe, mais celle pour une IA décentralisée reste à prouver ; les entreprises sont encore habituées aux API centralisées
La majorité des entreprises privilégient encore l’API centralisée, et l’adoption d’une infrastructure blockchain pour cela reste un obstacle.
Nous vivons une époque où même un responsable américain de la cybersécurité peut confier des documents confidentiels à une IA. La demande pour une IA privée est là, et elle ne fera que croître.
Nesa, avec ses bases académiques et ses infrastructures opérationnelles, est déjà en position pour répondre à cette demande. Malgré ses limites, elle a une longueur d’avance sur d’autres projets.
Quand le marché de l’IA privée s’ouvrira réellement, Nesa sera sans doute l’un des noms les plus cités.