En bref
- La Cour suprême de Colombie a rejeté un pourvoi en cassation après que des détecteurs d’IA l’ont identifié comme généré par machine.
- Des avocats ont analysé la décision avec les mêmes outils et ont constaté qu’elle semblait également écrite par une IA.
- Des experts et des études ont montré que les logiciels de détection d’IA produisent des résultats peu fiables et incohérents.
La Cour suprême de Colombie a rejeté un pourvoi en cassation, arguant qu’il avait été généré par une IA. Mais le même outil utilisé par la cour pour déterminer l’origine supposée IA de la décision a lui aussi indiqué que sa propre décision avait été aidée par une génération automatique.
S’agit-il d’une double norme de la part de la cour, ou d’outils défectueux ?
« Face à une suspicion fondée que le mémoire présenté par l’avocat n’avait pas été rédigé par le professionnel lui-même, la cour a soumis le texte à l’outil Winston IA », a argumenté la cour. « Son analyse a indiqué que le document ne contenait que 7 % de contenu humain, témoignant d’une influence marquée de l’écriture automatisée et conduisant à la conclusion qu’il avait été produit à l’aide de l’intelligence artificielle. »
Après avoir effectué l’analyse avec d’autres outils donnant des résultats similaires, la cour a statué que « puisque le dossier ne peut être considéré comme une plaidoirie dûment déposée, son rejet comme irrecevable est requis. »
Mais lorsque la décision de la cour a été soumise à un examen par des experts juridiques, les résultats ont été similaires.
« J’ai soumis le texte de l’Auto AP760/2026 de la Cour suprême au même logiciel Winston IA cité dans la décision », a écrit l’avocat Emmanuel Alessio Velasquez sur X mardi. « Résultat : le document contient 93 % de texte généré par IA. »
J’ai soumis le texte de l’auto AP760/2026 de la @CorteSupremaJ au même logiciel Winston IA cité dans la décision. Le résultat : le document présente 93 % de « texte généré par IA ». https://t.co/xTm2jI4d70 pic.twitter.com/lpSHuRjEZ4
— Emmanuel Alessio Velásquez (@EmmanuVeZe) 3 mars 2026
« Si la décision elle-même qui condamne l’utilisation de l’intelligence artificielle affiche ce pourcentage, la fragilité méthodologique de l’utilisation de ces détecteurs comme support argumentatif devient évidente », a-t-il argumenté dans un tweet ultérieur.
Quelques heures après que la cour a publié un fil de discussion à ce sujet sur X, des avocats ont commencé à faire leurs propres tests. Le post de Velasquez est devenu viral dans les cercles juridiques, accumulant des dizaines de milliers de vues.
Nous avons également testé la verdict de la cour, et les résultats initiaux n’étaient pas très encourageants. Lorsque GPTZero n’a analysé que les mots d’ouverture du texte de la cour, il a renvoyé un résultat à 100 % IA.
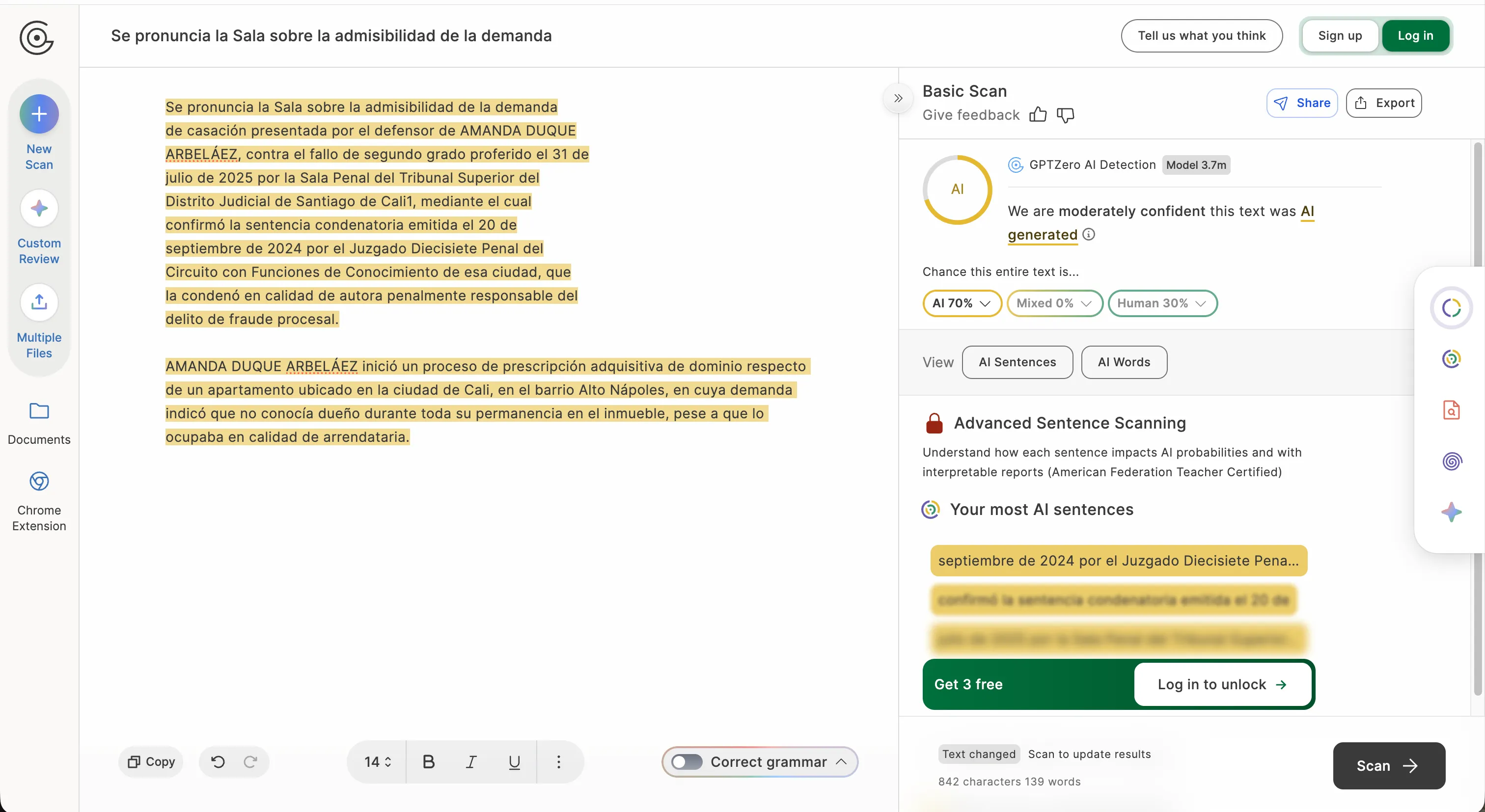
Lorsque le même outil a traité une version plus longue incluant la section contexte factuel, il a complètement inversé la tendance : 100 % humain.
L’outil n’est tout simplement pas assez fiable pour être utilisé en cour ou dans des situations nécessitant un haut degré de certitude.
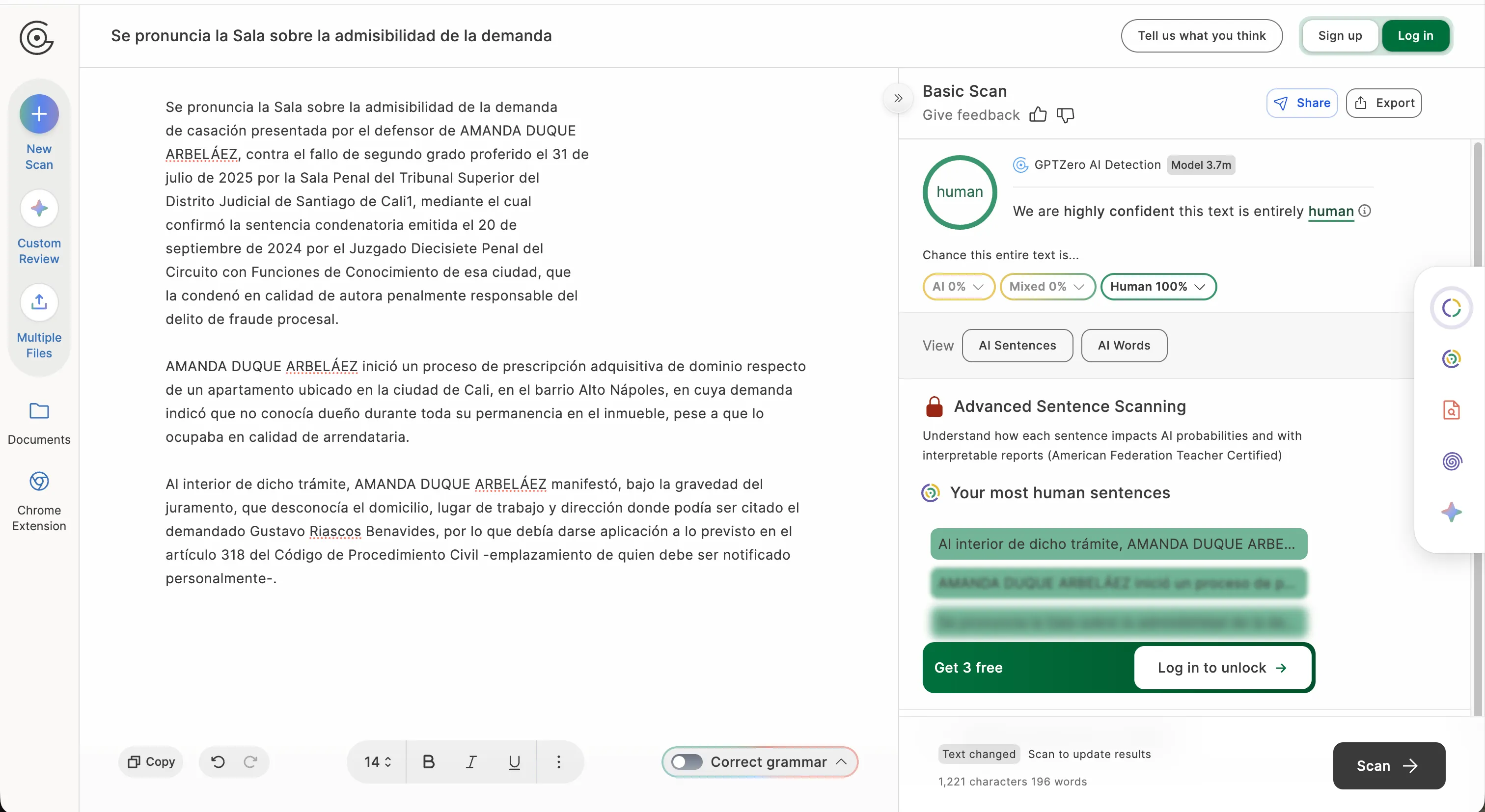
Des avocats colombiens ont réagi rapidement avec leurs propres expérimentations. L’avocat de la défense pénale et conférencier Andres F. Arango G a soumis un dossier judiciaire de 2019, bien avant l’existence des grands modèles linguistiques que ces outils sont censés détecter, et il a été déclaré à 95 % généré par IA.
« Ces outils vous invitent ensuite à ‘humaniser’ l’article via leurs services payants », a-t-il écrit sur X, soulignant une incitation commerciale évidente intégrée dans le modèle économique de la détection.
Nicolas Buelvas a testé sa thèse de licence de 2020 sur le principe de confiance en droit pénal. Résultat ? 100 % IA.
Dario Cabrera Montealegre, un autre avocat colombien, a souligné l’hypocrisie de se fier à la technologie pour lutter contre elle.
« La cour utilise l’IA pour déterminer s’il y a eu de l’IA », a-t-il dit. « Quelque chose de contradictoire de mon point de vue pratique. »
La Corte usa IA para determinar si hubo IA…!? Algo contradictorio desde mi punto de vista práctico…Si se rechaza debe ser porque como humanos lo detectamos
— Darío Cabrera Montealegre (@dalcamont_daro) 2 mars 2026
Au-delà des cercles juridiques, d’autres personnes technophiles ont souligné les dangers d’une dépendance excessive aux outils de détection d’IA.
« À ce jour, il n’existe aucun outil accessible au public capable de définir avec précision le pourcentage d’utilisation de l’IA lors de la rédaction d’un texte », a argumenté Carlos Alejandro Torres Pinedo. « Pire encore : personne ne peut vérifier publiquement le code source derrière ces plateformes de détection. Comment peuvent-elles être utilisées pour délégitimer le droit de quelqu’un à accéder à la justice ? »
Les raisons techniques de ces échecs sont bien documentées. Les détecteurs d’IA mesurent des motifs statistiques : longueur des phrases, prévisibilité du vocabulaire, et une caractéristique que les chercheurs appellent « burstiness », qui fait référence à la variation du rythme naturel que les humains introduisent dans leur écriture.
Le problème est que la prose juridique formelle, l’écriture académique, et les textes produits par des personnes écrivant en seconde langue partagent beaucoup de ces signatures statistiques.
Études sur la détection d’IA
Une étude de 2023 publiée dans Patterns a révélé que plus de 61 % des essais TOEFL écrits par des non-anglophones étaient incorrectement signalés comme générés par IA.
Une revue systématique de Weber-Wulff cette même année a conclu qu’aucun outil disponible n’est précis ni fiable. Turnitin a reconnu en juin 2023 que son propre détecteur produisait un taux plus élevé de faux positifs lorsque le niveau de contenu IA dans un document était inférieur à 20 %.
Même OpenAI a dû retirer son propre outil de détection d’IA après des inexactitudes constantes et une incapacité à remplir sa mission.
Les universités luttent contre ce problème depuis des années. Vanderbilt a désactivé le détecteur d’IA de Turnitin en 2023 après avoir estimé qu’il générerait environ 3 000 faux positifs par an.
L’Université d’Arizona a supprimé les fonctionnalités de détection d’IA de son logiciel anti-plagiat après qu’un étudiant ait perdu 20 % de sa note à cause d’un faux positif. En 2024, une affaire à UC Davis a concerné 17 étudiants en linguistique, dont 15 non-anglophones.
Le schéma est constant. Les outils pénalisent ceux qui écrivent de manière la plus formelle, la plus répétitive ou la plus soignée, précisément le profil que correspondent les avocats, les universitaires et les locuteurs de seconde langue.
Les retombées culturelles frôlent l’absurde. Dans les cercles d’écrivains et de journalistes, les gens ont commencé à éviter les tirets cadratins dans leur travail, non pas à cause d’un guide de style, mais parce que les modèles linguistiques d’IA les utilisent fréquemment et que les outils de détection (et les gens) y ont prêté attention.
Les écrivains s’auto-corrigent en supprimant la ponctuation naturelle par crainte d’être suspectés par un algorithme. Au-delà du monde écrit, des artistes ont souffert de la colère des modérateurs et collègues pour avoir créé des œuvres qui ressemblent à de l’IA.
Nous vivons dans un monde où de vrais artistes sont punis parce qu’ils sont victimes de ces voleurs appelés artistes IA ? #SauvezArtisteHumain #pasdartAI #NoAI #SauvezFuturArt pic.twitter.com/yTQAeyc8SR
— Benmoran artiste (@benmoran_artist) 27 décembre 2022
Les deux décisions de la justice colombienne—AC739-2026, dans laquelle la chambre civile a condamné un avocat pour avoir cité 10 précédents fictifs générés par IA en février, et AP760-2026—émergent comme parmi les premières décisions judiciaires de la région à confronter directement l’usage abusif de l’IA générative dans les dossiers juridiques.
Le pouvoir judiciaire colombien a adopté en décembre 2024 des lignes directrices officielles régulant l’utilisation de l’intelligence artificielle par les juges et le personnel judiciaire.
Ces règles autorisent l’utilisation libre de l’IA pour des tâches administratives et de soutien, comme rédiger des courriels, organiser des agendas, traduire des documents ou résumer des textes, tout en limitant les usages plus sensibles, comme la recherche juridique ou la rédaction de documents procéduraux, à une révision humaine attentive.
Les lignes directrices interdisent explicitement de se fier à l’IA pour évaluer des preuves, interpréter la loi ou prendre des décisions judiciaires, en insistant sur le fait que les juges humains restent entièrement responsables de toutes les décisions et doivent divulguer l’utilisation d’outils d’IA dans la préparation des documents judiciaires.
Ces directives, regroupées dans l’accord « PCSJA24-12243 », pourraient être utilisées pour contester une telle décision.
La Cour suprême n’a pas encore publié de déclaration supplémentaire en réponse au mécontentement concernant le choix des outils de détection. La décision n’utilisait pas non plus de tirets cadratins.
Avertissement : Les informations contenues dans cette page peuvent provenir de tiers et ne représentent pas les points de vue ou les opinions de Gate. Le contenu de cette page est fourni à titre de référence uniquement et ne constitue pas un conseil financier, d'investissement ou juridique. Gate ne garantit pas l'exactitude ou l'exhaustivité des informations et n'est pas responsable des pertes résultant de l'utilisation de ces informations. Les investissements en actifs virtuels comportent des risques élevés et sont soumis à une forte volatilité des prix. Vous pouvez perdre la totalité du capital investi. Veuillez comprendre pleinement les risques pertinents et prendre des décisions prudentes en fonction de votre propre situation financière et de votre tolérance au risque. Pour plus de détails, veuillez consulter l'
avertissement.

