Tantangan Stack Data Blockchain Modern
Startup pengindeksan blockchain modern menghadapi sejumlah tantangan, antara lain:
- Volume data yang sangat besar. Seiring bertambahnya data di blockchain, indeks data harus mampu melakukan penskalaan untuk mengelola beban yang meningkat dan tetap memberikan akses efisien. Hal ini berdampak pada kenaikan biaya penyimpanan, perlambatan perhitungan metrik, dan peningkatan beban pada server basis data.
- Pipa pemrosesan data yang kompleks. Blockchain merupakan teknologi yang kompleks; membangun indeks data yang komprehensif dan andal memerlukan pemahaman mendalam atas struktur data dan algoritma yang mendasarinya. Kompleksitas ini juga muncul dari beragamnya implementasi blockchain. Sebagai contoh, NFT di Ethereum biasanya dibuat dalam smart contract yang mengikuti format ERC721 dan ERC1155, sedangkan di Polkadot, NFT umumnya dibangun langsung di dalam runtime blockchain. Pada akhirnya, semuanya tetap dikategorikan dan disimpan sebagai NFT.
- Kemampuan integrasi. Untuk memberikan nilai optimal bagi pengguna, solusi pengindeksan blockchain harus mampu mengintegrasikan indeks datanya dengan sistem lain, seperti platform analitik atau API. Hal ini menuntut desain arsitektur yang matang dan upaya integrasi yang signifikan.
Dengan semakin luasnya adopsi teknologi blockchain, volume data yang tersimpan di blockchain pun meningkat. Hal ini disebabkan oleh bertambahnya pengguna dan setiap transaksi yang menambah data baru ke blockchain. Selain itu, penggunaan blockchain telah berkembang dari aplikasi transfer uang sederhana—seperti Bitcoin—menjadi aplikasi yang lebih kompleks yang melibatkan logika bisnis pada smart contract. Smart contract semacam ini dapat menghasilkan data dalam jumlah besar, sehingga menambah tingkat kompleksitas dan ukuran blockchain. Dalam jangka panjang, blockchain pun menjadi semakin besar dan kompleks.
Pada artikel ini, kami membahas evolusi arsitektur teknologi Footprint Analytics secara bertahap sebagai studi kasus untuk menelaah bagaimana stack Iceberg-Trino mengatasi tantangan data on-chain.
Footprint Analytics telah mengindeks sekitar 22 data blockchain publik, 17 marketplace NFT, 1.900 proyek GameFi, dan lebih dari 100.000 koleksi NFT ke dalam lapisan data abstraksi semantik. Ini merupakan solusi gudang data blockchain paling komprehensif di dunia.
Data blockchain yang dikelola—lebih dari 20 miliar baris catatan transaksi keuangan dan sering diakses oleh analis data—berbeda dengan log ingression pada gudang data tradisional.
Dalam beberapa bulan terakhir, kami telah melakukan tiga kali peningkatan besar untuk memenuhi kebutuhan bisnis yang terus berkembang:
Arsitektur 1.0 Bigquery
Pada fase awal, Footprint Analytics menggunakan Google Bigquery sebagai storage dan query engine. Bigquery menawarkan performa sangat cepat, kemudahan penggunaan, daya aritmatika dinamis, serta sintaks UDF yang fleksibel, sehingga mempercepat proses kerja tim kami.
Namun, Bigquery juga memiliki sejumlah keterbatasan.
- Data tidak dikompresi, sehingga biaya penyimpanan menjadi tinggi—terutama untuk data mentah dari lebih dari 22 blockchain milik Footprint Analytics.
- Keterbatasan konkurensi: Bigquery hanya mendukung 100 query secara bersamaan, sehingga tidak memadai untuk skenario konkurensi tinggi di Footprint Analytics yang melayani banyak analis dan pengguna.
- Terkunci pada Google Bigquery, yang merupakan produk closed source.
Karena itu, kami memutuskan untuk mengeksplorasi alternatif arsitektur lainnya.
Arsitektur 2.0 OLAP
Kami sangat tertarik dengan beberapa produk OLAP yang tengah populer. Keunggulan utama OLAP adalah waktu respons query yang sangat cepat—biasanya sub-detik untuk data dalam jumlah besar—dan dukungan ribuan query secara bersamaan.
Kami memilih Doris, salah satu database OLAP terbaik, untuk diuji coba. Engine ini memberikan performa yang baik. Namun, kami segera menemukan beberapa kendala lain:
- Tipe data seperti Array atau JSON belum didukung (Nov, 2022). Array merupakan tipe data umum di sejumlah blockchain, contohnya pada field topic di log evm. Ketidakmampuan melakukan komputasi pada Array secara langsung membatasi perhitungan banyak metrik bisnis kami.
- Dukungan terbatas untuk DBT dan merge statement. Kebutuhan ini umum untuk data engineer pada skenario ETL/ELT, di mana pembaruan data yang baru diindeks diperlukan.
Karena itu, kami tidak dapat menggunakan Doris untuk seluruh pipeline data produksi. Kami hanya menggunakan Doris sebagai database OLAP untuk menyelesaikan sebagian masalah pipeline data produksi, bertindak sebagai query engine dan menyediakan performa query yang cepat serta konkurensi tinggi.
Sayangnya, Doris tidak dapat menggantikan Bigquery sepenuhnya, sehingga kami harus melakukan sinkronisasi data secara berkala dari Bigquery ke Doris dan hanya menggunakannya sebagai query engine. Proses sinkronisasi ini menimbulkan beberapa masalah, salah satunya adalah penulisan pembaruan yang menumpuk ketika OLAP engine sibuk melayani query front-end. Akibatnya, proses penulisan melambat dan sinkronisasi menjadi lebih lama, bahkan kadang tidak terselesaikan.
Kami menyadari OLAP dapat mengatasi beberapa masalah, namun belum menjadi solusi menyeluruh untuk Footprint Analytics—khususnya pada pipeline pemrosesan data. Permasalahan kami lebih besar dan kompleks, sehingga OLAP sebagai query engine saja tidak cukup.
Arsitektur 3.0 Iceberg + Trino
Arsitektur Footprint Analytics 3.0 adalah pembaruan total pada fondasi sistem. Kami mendesain ulang arsitektur dari nol, memisahkan penyimpanan, komputasi, dan query data menjadi tiga bagian berbeda. Kami mengambil pelajaran dari dua arsitektur sebelumnya serta pengalaman proyek big data sukses seperti Uber, Netflix, dan Databricks.
Pengenalan Data Lake
Kami kemudian memfokuskan perhatian pada data lake, jenis penyimpanan baru untuk data terstruktur dan tidak terstruktur. Data lake sangat sesuai untuk penyimpanan data on-chain, mengingat format data on-chain sangat beragam, mulai dari data mentah tidak terstruktur hingga data abstraksi terstruktur seperti yang dikembangkan Footprint Analytics. Kami menargetkan data lake sebagai solusi penyimpanan data, dengan harapan dapat mendukung engine komputasi mainstream seperti Spark dan Flink, sehingga integrasi dengan berbagai engine pemrosesan tetap mudah seiring pertumbuhan Footprint Analytics.
Iceberg terintegrasi optimal dengan Spark, Flink, Trino, dan berbagai engine komputasi lainnya, sehingga kami dapat memilih engine yang paling sesuai untuk setiap metrik. Misalnya:
- Untuk komputasi logika kompleks, kami menggunakan Spark.
- Flink untuk komputasi real-time.
- Untuk tugas ETL sederhana berbasis SQL, kami memilih Trino.
Query Engine
Setelah masalah penyimpanan dan komputasi terselesaikan dengan Iceberg, kami mempertimbangkan pilihan query engine. Pilihan yang tersedia antara lain:
- Trino: SQL Query Engine
- Presto: SQL Query Engine
- Kyuubi: Serverless Spark SQL
Faktor utama yang kami pertimbangkan adalah kompatibilitas query engine masa depan dengan arsitektur kami saat ini.
- Mendukung Bigquery sebagai Data Source
- Mendukung DBT, yang menjadi andalan dalam menghasilkan banyak metrik
- Mendukung alat BI Metabase
Berdasarkan pertimbangan tersebut, kami memilih Trino yang memiliki dukungan sangat baik untuk Iceberg dan tim pengembang yang sangat responsif. Ketika kami melaporkan bug, perbaikan dilakukan keesokan hari dan dirilis ke versi terbaru pada minggu berikutnya. Ini adalah pilihan terbaik bagi tim Footprint yang juga membutuhkan kecepatan implementasi tinggi.
Pengujian Performa
Setelah menetapkan arah, kami melakukan pengujian performa pada kombinasi Trino + Iceberg untuk memastikan kecocokan dengan kebutuhan kami, dan hasilnya, kecepatan query sangat mengesankan.
Selama bertahun-tahun, Presto + Hive menjadi tolok ukur performa terburuk dalam tren OLAP, namun kombinasi Trino + Iceberg benar-benar melampaui ekspektasi kami.
Berikut hasil pengujian kami:
Kasus 1: join dataset besar
Sebuah tabel 800 GB (table1) dijoin dengan tabel lain 50 GB (table2) dan dilakukan perhitungan bisnis kompleks.
Kasus 2: query distinct pada satu tabel besar
Test sql: select distinct(address) from table group by day

Kombinasi Trino+Iceberg sekitar tiga kali lebih cepat dari Doris dengan konfigurasi yang sama.
Selain itu, Iceberg dapat menggunakan format data seperti Parquet, ORC, dan lainnya, sehingga data terkompresi dan efisien dalam penyimpanan. Penyimpanan tabel Iceberg hanya membutuhkan sekitar 1/5 ruang dibandingkan gudang data lain. Berikut perbandingan ukuran penyimpanan pada tiga database:

Catatan: Pengujian di atas adalah contoh aktual yang kami temui di produksi dan hanya sebagai referensi.
・Dampak Upgrade
Hasil pengujian performa memberikan keyakinan bagi tim untuk menyelesaikan migrasi dalam waktu sekitar dua bulan. Berikut diagram arsitektur kami setelah upgrade:
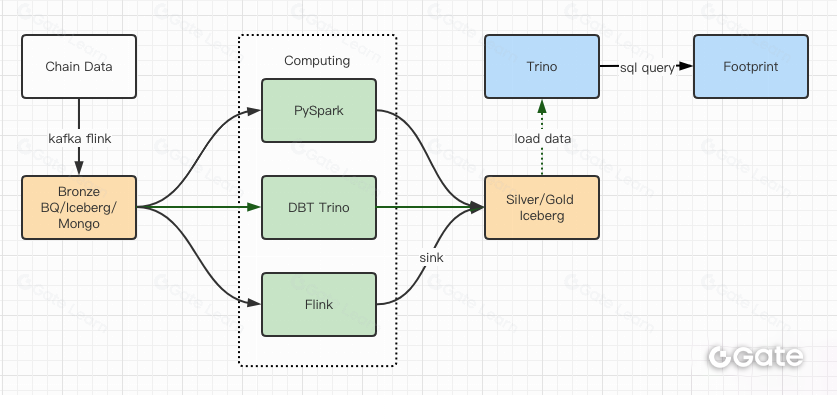
- Beragam engine komputasi memenuhi kebutuhan kami secara optimal.
- Trino mendukung DBT dan dapat mengquery Iceberg secara langsung, sehingga kebutuhan sinkronisasi data tidak lagi diperlukan.
- Performa Trino + Iceberg yang luar biasa memungkinkan kami membuka seluruh data Bronze (data mentah) untuk pengguna.
Ringkasan
Sejak diluncurkan pada Agustus 2021, tim Footprint Analytics telah melakukan tiga kali peningkatan arsitektur dalam waktu kurang dari satu setengah tahun—berkat tekad menghadirkan teknologi database terbaik bagi pengguna kripto dan eksekusi solid dalam membangun serta mengembangkan infrastruktur dasarnya.
Peningkatan arsitektur Footprint Analytics 3.0 menghadirkan pengalaman baru bagi pengguna, memungkinkan mereka dari berbagai latar belakang mendapatkan insight lebih beragam dalam penggunaan dan aplikasi:
- Dengan alat BI Metabase, Footprint memfasilitasi analis untuk mengakses data on-chain yang telah didekode, mengeksplorasi dengan kebebasan penuh (no-code maupun hardcord), melakukan query riwayat penuh, membandingkan dataset, dan mendapatkan insight secara instan.
- Mengintegrasikan data on-chain dan off-chain untuk analisis lintas web2 dan web3;
- Dengan membangun atau melakukan query metrik di atas abstraksi bisnis Footprint, analis dan pengembang dapat menghemat hingga 80% waktu pemrosesan data berulang dan lebih fokus pada metrik bermakna, riset, dan solusi produk sesuai kebutuhan bisnis.
- Pengalaman seamless dari Footprint Web hingga REST API, seluruhnya berbasis SQL
- Peringatan real-time dan notifikasi yang dapat ditindaklanjuti pada sinyal utama untuk mendukung pengambilan keputusan investasi






