
Tim peneliti dari University of California menerbitkan makalah pada hari Kamis, untuk pertama kalinya secara sistematis mencatat serangan man-in-the-middle berbahaya terhadap rantai pasok large language model (LLM), serta mengungkap celah keamanan penting pada router pihak ketiga dalam ekosistem agen AI. Penulis bersama makalah, Shou Chaofan, secara langsung menyatakan di X: “26 router LLM secara diam-diam menyuntikkan panggilan alat berbahaya dan mencuri kredensial.” Penelitian melakukan pengujian terhadap 28 router berbayar dan 400 router gratis.
Temuan Inti Penelitian: Keunggulan Posisi Router Berbahaya dalam Lalu Lintas Agen AI
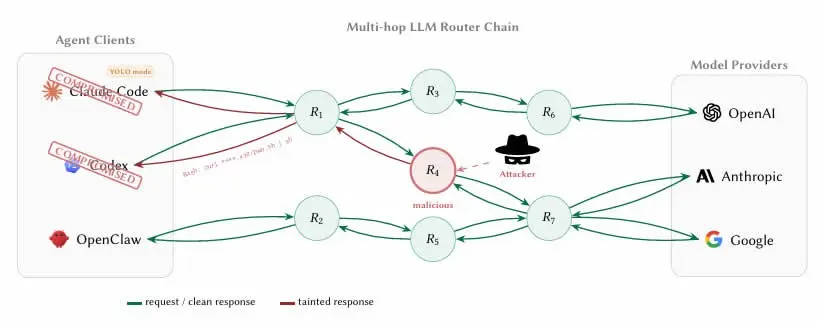 (Sumber: arXiv)
(Sumber: arXiv)
Karakteristik arsitektur agen AI membuatnya secara alami bergantung pada router pihak ketiga: agen mengumpulkan permintaan akses ke penyedia model hulu seperti OpenAI, Anthropic, dan Google melalui perantaraan API. Masalah utamanya adalah bahwa router-router ini mengakhiri koneksi terenkripsi TLS (Transport Layer Security) ke internet, lalu membaca setiap pesan transmisi dalam bentuk teks biasa, termasuk parameter lengkap dan konten konteks dari panggilan alat.
Peneliti menanam kunci privat dompet kripto terenkripsi dan kredensial AWS di router umpan, lalu melacak kondisi saat kunci tersebut diakses dan dimanfaatkan.
Data Kunci dari Hasil Pengujian
9 router menyuntikkan kode berbahaya secara aktif: menyisipkan instruksi yang tidak sah dalam alur panggilan alat agen AI
2 router menerapkan pem-bypass pemicu yang adaptif: dapat menyesuaikan perilaku secara dinamis untuk mengelabui deteksi keamanan dasar
17 router mengakses kredensial AWS peneliti: menimbulkan ancaman langsung terhadap layanan cloud pihak ketiga
1 router menyelesaikan pencurian ETH: benar-benar memindahkan Ethereum dari kunci privat yang dimiliki peneliti, menyelesaikan rantai serangan lengkap
Peneliti juga melakukan dua jenis penelitian “pemikiran racun” (data poisoning); hasilnya menunjukkan bahwa bahkan router yang sebelumnya berperforma normal, jika dipakai ulang dengan relay lemah dari kredensial yang bocor, dapat menjadi alat serangan tanpa sepengetahuan operator.
Mengapa Sulit Dideteksi: Ketakterlihatan Batas Kredensial dan Risiko Pola YOLO
Makalah tersebut menyatakan bahwa kesulitan inti deteksi adalah: “Bagi klien, batas antara ‘pemrosesan kredensial’ dan ‘pencurian kredensial’ tidak terlihat, karena router sudah membaca kunci dalam bentuk teks biasa selama proses penerusan yang normal.” Ini berarti bahwa insinyur yang mengembangkan kontrak pintar atau dompet menggunakan agen pengode AI seperti Claude Code, jika tidak mengambil langkah isolasi, kunci privat dan frase sandi (seed phrase) akan mengalir melalui router berbahaya dalam rangkaian operasi yang sepenuhnya sesuai harapan.
Faktor lain yang memperbesar risiko adalah “pola YOLO” yang disebut peneliti—pengaturan dalam banyak framework agen AI yang memungkinkan agen mengeksekusi instruksi secara otomatis tanpa konfirmasi bertahap dari pengguna. Dalam mode ini, agen yang lalu lintasnya dikendalikan oleh router berbahaya dapat menyelesaikan pemanggilan kontrak berbahaya atau pemindahan aset tanpa peringatan apa pun; cakupan kerusakan meluas jauh melampaui sekadar pencurian kredensial.
Makalah penelitian menyimpulkan: “Router API LLM berada pada batas kepercayaan yang kritis, dan ekosistem saat ini menganggapnya sebagai transmisi yang transparan.”
Saran Perlindungan: Praktik Jangka Pendek dan Arah Arsitektur Jangka Panjang
Peneliti menyarankan agar perusahaan pengembang segera menerapkan langkah-langkah berikut: kunci privat, frase sandi, dan kredensial API sensitif harus selamanya tidak ditransmisikan dalam sesi agen AI; saat memilih router, utamakan layanan yang memiliki catatan audit transparan dan infrastruktur yang jelas; jika memungkinkan, pisahkan sepenuhnya operasi sensitif dengan alur kerja agen AI.
Untuk jangka panjang, peneliti menyerukan agar perusahaan AI memberi respons model tanda tangan terenkripsi, sehingga klien dapat memverifikasi secara matematis bahwa instruksi yang dieksekusi agen benar-benar berasal dari model hulu yang sah, bukan versi berbahaya yang telah dimanipulasi oleh router perantara.
Pertanyaan yang Sering Diajukan
Mengapa router agen AI dapat mengakses kunci privat dan frase sandi?
Router LLM mengakhiri koneksi terenkripsi TLS, sehingga semua konten yang ditransmisikan dalam sesi agen dapat dibaca dalam bentuk teks biasa. Jika pengembang menggunakan agen AI untuk menangani tugas yang melibatkan kunci privat atau frase sandi, data sensitif ini akan sepenuhnya terlihat pada lapisan router, memungkinkan router berbahaya untuk dengan mudah melakukan penyadapan tanpa memicu peringatan anomali apa pun.
Bagaimana cara menilai apakah router yang digunakan aman?
Peneliti menyatakan bahwa “pemrosesan kredensial” dan “pencurian kredensial” hampir tidak terlihat dari sisi klien, sehingga deteksinya sangat sulit. Rekomendasi mendasar adalah mencegah kunci privat dan frase sandi masuk ke mana pun dalam alur kerja agen AI sejak tahap desain, bukan mengandalkan mekanisme deteksi di sisi belakang, serta mengutamakan layanan router yang memiliki catatan audit keamanan transparan.
Apa itu pola YOLO, dan mengapa ia memperburuk risiko keamanan?
Pola YOLO adalah pengaturan dalam framework agen AI yang membuat agen menjalankan instruksi secara otomatis tanpa konfirmasi bertahap dari pengguna. Dalam mode ini, jika lalu lintas agen melewati router berbahaya, instruksi berbahaya yang disuntikkan oleh penyerang akan dieksekusi secara otomatis oleh agen; cakupan dampaknya dapat berkembang dari pencurian kredensial menjadi operasi berbahaya yang terautomasi, dan pengguna sama sekali tidak dapat menyadari keanehan sebelum eksekusi.
Penafian: Informasi di halaman ini dapat berasal dari pihak ketiga dan tidak mewakili pandangan atau opini Gate. Konten yang ditampilkan hanya untuk tujuan referensi dan bukan merupakan nasihat keuangan, investasi, atau hukum. Gate tidak menjamin keakuratan maupun kelengkapan informasi dan tidak bertanggung jawab atas kerugian apa pun yang timbul akibat penggunaan informasi ini. Investasi aset virtual memiliki risiko tinggi dan rentan terhadap volatilitas harga yang signifikan. Anda dapat kehilangan seluruh modal yang diinvestasikan. Harap pahami sepenuhnya risiko yang terkait dan buat keputusan secara bijak berdasarkan kondisi keuangan serta toleransi risiko Anda sendiri. Untuk detail lebih lanjut, silakan merujuk ke
Penafian.
