Rickawsb
現在、コンテンツはありません
rickawsb
最近提交IPO的AI芯片新宠Cerebras在硅谷引起了热潮。
其芯片在小模型场景下,推理速度最高可达H100的20倍;而超大规模模型(如400B参数级别),Cerebras CS-3系统的单用户响应速度约为B200的2.4倍。
那么Cerebras究竟是如何做到的呢?它是否会成为英伟达的杀手呢?
我们需从算力演进的本质开始。
AI算力的演进,正在从“算力本身”转向“通信与系统结构”。在这条演进路径上,Cerebras Systems提供了一种完全不同的答案:不是优化分布式,而是尽可能消灭分布式。
一、两条路线:消灭通信 vs 优化通信
当前AI算力本质上分为两种架构哲学:一条是以NVIDIA为代表的路线:
多芯片(GPU),高速互连(NVLink / CPO),scale-out(横向扩展)
另一条是Cerebras路径:单芯片做到极限(wafer-scale)
片内网络替代跨节点通信,scale-up(纵向放大)
核心区别是:一条在解决“如何连接更多芯片”,另一条在解决“如何不需要连接”。
二、为什么这条路现在才成立
wafer-scale并不是新概念,80年代就有人尝试,90年代商业化失败。原因是:
良率无法承受
没有容错机制
软件无法支撑
行业因此形成共识:小die + 高良率 + 分布式。
Cerebras的突破在于三件事同时成立:
1)容错机制工程化
2)片上网络成熟
原文表示其芯片在小模型场景下,推理速度最高可达H100的20倍;而超大规模模型(如400B参数级别),Cerebras CS-3系统的单用户响应速度约为B200的2.4倍。
那么Cerebras究竟是如何做到的呢?它是否会成为英伟达的杀手呢?
我们需从算力演进的本质开始。
AI算力的演进,正在从“算力本身”转向“通信与系统结构”。在这条演进路径上,Cerebras Systems提供了一种完全不同的答案:不是优化分布式,而是尽可能消灭分布式。
一、两条路线:消灭通信 vs 优化通信
当前AI算力本质上分为两种架构哲学:一条是以NVIDIA为代表的路线:
多芯片(GPU),高速互连(NVLink / CPO),scale-out(横向扩展)
另一条是Cerebras路径:单芯片做到极限(wafer-scale)
片内网络替代跨节点通信,scale-up(纵向放大)
核心区别是:一条在解决“如何连接更多芯片”,另一条在解决“如何不需要连接”。
二、为什么这条路现在才成立
wafer-scale并不是新概念,80年代就有人尝试,90年代商业化失败。原因是:
良率无法承受
没有容错机制
软件无法支撑
行业因此形成共识:小die + 高良率 + 分布式。
Cerebras的突破在于三件事同时成立:
1)容错机制工程化
2)片上网络成熟

- 報酬
- いいね
- コメント
- リポスト
- 共有
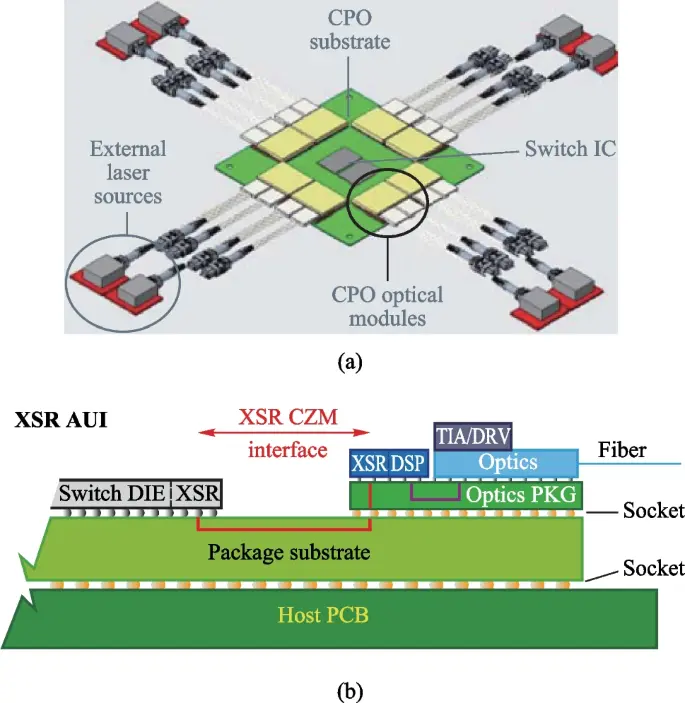
週末深掘:CPO + ELS光源趋势から見た独立レーザーベンダーの位置、境界、そして終局
AI計算能力のボトルネックは計算から帯域幅へと移行している。GPU規模の拡大に伴い、ノード間通信はN²に近い増加を示し、電気インターコネクトは消費電力と距離の上限に達しつつある。光インターコネクトは「選択肢」から「必須」へと変わる。
この過程で、CPO(Co-Packaged Optics)とELS(External Laser Source)が産業チェーンを再構築し始めている:レーザーモジュールは内部から切り離され、システムレベルのリソースとなる。
独立レーザーベンダーSIVEFはこの変化の重要な節目に位置している。
一、SIVEFの事業内容
同社のコアはInPプラットフォームを用いたWDM DFBレーザアレイ。
簡単に言えば:
DFB:安定した単一波長レーザー
WDM:多波長多重化
アレイ:複数レーザーの一体化
本質は「レーザー」自体を売るのではなく、多チャネル光帯域幅を提供することにある。
CPO + ELSアーキテクチャ下では:
従来:各モジュールに一つのレーザー
新アーキテクチャ:一つの光源で複数のチャネルを供給
レーザーは「分散型コンポーネント」から「集中リソース」へと変化し、これが価値の再配分の出発点となる。
二、なぜWDM DFBアレイなのか
AIデータセンターの制約は明確だ:
原文表示AI計算能力のボトルネックは計算から帯域幅へと移行している。GPU規模の拡大に伴い、ノード間通信はN²に近い増加を示し、電気インターコネクトは消費電力と距離の上限に達しつつある。光インターコネクトは「選択肢」から「必須」へと変わる。
この過程で、CPO(Co-Packaged Optics)とELS(External Laser Source)が産業チェーンを再構築し始めている:レーザーモジュールは内部から切り離され、システムレベルのリソースとなる。
独立レーザーベンダーSIVEFはこの変化の重要な節目に位置している。
一、SIVEFの事業内容
同社のコアはInPプラットフォームを用いたWDM DFBレーザアレイ。
簡単に言えば:
DFB:安定した単一波長レーザー
WDM:多波長多重化
アレイ:複数レーザーの一体化
本質は「レーザー」自体を売るのではなく、多チャネル光帯域幅を提供することにある。
CPO + ELSアーキテクチャ下では:
従来:各モジュールに一つのレーザー
新アーキテクチャ:一つの光源で複数のチャネルを供給
レーザーは「分散型コンポーネント」から「集中リソース」へと変化し、これが価値の再配分の出発点となる。
二、なぜWDM DFBアレイなのか
AIデータセンターの制約は明確だ:
- 報酬
- いいね
- コメント
- リポスト
- 共有
少し見てみたところ、今では多くの米国株の有名な大物インフルエンサーが推奨している小型株は、純粋に物語だけだ。
私の第一の思考:価値投資、ギャンブルには参加しない。
私の第二の思考:暗号通貨界の素人プレイヤーとして、無思考で全額投入しなければならない🤣
原文表示私の第一の思考:価値投資、ギャンブルには参加しない。
私の第二の思考:暗号通貨界の素人プレイヤーとして、無思考で全額投入しなければならない🤣
- 報酬
- いいね
- コメント
- リポスト
- 共有
moonshotsチャンネルの今日の見解:
aiはコス定律を無効にするだろう
啓示!
組織の存在理由の一つは、組織内の調整コストが市場取引コストより低いためである
aiが取引コストの削減幅を組織コストの削減幅よりはるかに超えるとき、組織の存在意義は大きく低下する
これは企業にとってもそうであり、国家にとっても同じだ。
原文表示aiはコス定律を無効にするだろう
啓示!
組織の存在理由の一つは、組織内の調整コストが市場取引コストより低いためである
aiが取引コストの削減幅を組織コストの削減幅よりはるかに超えるとき、組織の存在意義は大きく低下する
これは企業にとってもそうであり、国家にとっても同じだ。
- 報酬
- 1
- 1
- リポスト
- 共有
ybaser:
ただ前進し続ける 👊ただ前進し続ける 👊すべての知識(知的)労働者は、AIに置き換えられる
研究も含む
なぜなら、research = 情報処理 + 仮説生成 + 検証。
AIは各部分で人より優れており、さらに急速に強化されている。
たとえ本当の天才レベルの「ひらめき」、例えば一般相対性理論の発見が、最も置き換えが難しいとされる場合でも、そのような研究はごく少数である。
それにもかかわらず、一般相対性理論は人間の脳内のLLMの極致の汎化に相当するのだろうか?
原文表示研究も含む
なぜなら、research = 情報処理 + 仮説生成 + 検証。
AIは各部分で人より優れており、さらに急速に強化されている。
たとえ本当の天才レベルの「ひらめき」、例えば一般相対性理論の発見が、最も置き換えが難しいとされる場合でも、そのような研究はごく少数である。
それにもかかわらず、一般相対性理論は人間の脳内のLLMの極致の汎化に相当するのだろうか?
- 報酬
- いいね
- コメント
- リポスト
- 共有
新記録!20万人口規模の都市レベルの15年超長期電力契約がもたらすAIデータセンターの上下流への影響は何か?
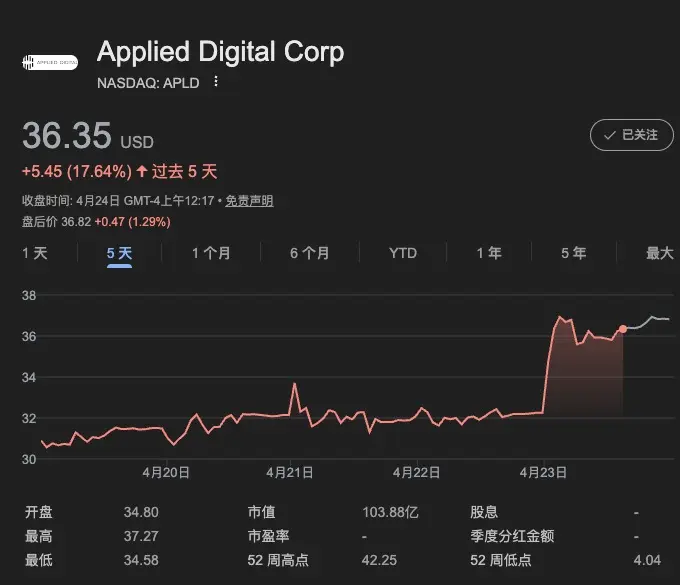
Applied Digital Corporation(apld)は本日、アメリカの投資適格ハイパースケーラーと、300MW、15年契約、総額約75億ドルの長期契約を締結したと発表した。
株価は一気に20%近く上昇した。
300MWの規模はすでに20万人都市の負荷に近く、15年の期間は従来のデータセンター契約を大きく超えている;また、容量を固定したモデルは、GPUや時間単位の料金による計算能力レンタルとは異なる。
これは、「超大規模 + 超長期 + 明確な計算能力用途」のインフラレベルのAI契約において、新たな記録を打ち立てた。
これの背景には、業界の属性の変化がある。これまでのデータセンターは本質的にITサービスであり、過去には5年程度の契約もあったが、拡張は依然として需要に応じて行われ、リソースは移動・交換可能だった;
しかし、今では徐々にインフラ資産へと変化し、電力PPAやエネルギーのような15年の長期契約を用いて供給を固定し始めている。
計算能力はもはや随時調達できるリソースではなく、事前に計画し、事前に確保する生産能力となる。
この変化の本質的な理由は、リソースの希少化にあり、蓄電、チップ、光モジュールと同様に、ハイパースケーラーにとって、事前にロックしなければ将
原文表示Applied Digital Corporation(apld)は本日、アメリカの投資適格ハイパースケーラーと、300MW、15年契約、総額約75億ドルの長期契約を締結したと発表した。
株価は一気に20%近く上昇した。
300MWの規模はすでに20万人都市の負荷に近く、15年の期間は従来のデータセンター契約を大きく超えている;また、容量を固定したモデルは、GPUや時間単位の料金による計算能力レンタルとは異なる。
これは、「超大規模 + 超長期 + 明確な計算能力用途」のインフラレベルのAI契約において、新たな記録を打ち立てた。
これの背景には、業界の属性の変化がある。これまでのデータセンターは本質的にITサービスであり、過去には5年程度の契約もあったが、拡張は依然として需要に応じて行われ、リソースは移動・交換可能だった;
しかし、今では徐々にインフラ資産へと変化し、電力PPAやエネルギーのような15年の長期契約を用いて供給を固定し始めている。
計算能力はもはや随時調達できるリソースではなく、事前に計画し、事前に確保する生産能力となる。
この変化の本質的な理由は、リソースの希少化にあり、蓄電、チップ、光モジュールと同様に、ハイパースケーラーにとって、事前にロックしなければ将
- 報酬
- いいね
- コメント
- リポスト
- 共有
半导体封装の「隠れた中枢」:インライン検査とOSATの再価格設定
半導体産業は重心移動を経験している:性能向上はもはやトランジスタの微細化だけに依存せず、封装にますます依存している。2.5D、3D、HBM、チップレットは本質的に「システム能力」を封装段階に移している。これにより、OSAT(外部委託封装・テスト)の戦略的地位も直接高まっている。
封装の重要性の高まりは、インライン検査の急速な成長をもたらしている。
OSAT(Outsourced Semiconductor Assembly and Test)は二つのことを担当している:
裸ダイを使えるチップに封入(封装)
チップが使えるかどうかの検証(テスト)
過去はこれは低技術・低利益率の工程だった。しかし、AI時代に入って状況は変わった:
マルチダイ集積(チップレット)
HBMの積層
ナノメートル級の位置合わせ要求(ハイブリッドボンディング)
封装は今や次のように変化している:
性能のボトルネック + 良品率のボトルネック + コストのボトルネック
インラインは一つの生産方式:すべての工程を連続して完了し、生産過程でリアルタイムに検査とフィードバックを行う(クローズドループ)
これに対応するもう一つの工程はオフライン:完了後に検査(オープンループ)
先進封装におけるインライ
原文表示半導体産業は重心移動を経験している:性能向上はもはやトランジスタの微細化だけに依存せず、封装にますます依存している。2.5D、3D、HBM、チップレットは本質的に「システム能力」を封装段階に移している。これにより、OSAT(外部委託封装・テスト)の戦略的地位も直接高まっている。
封装の重要性の高まりは、インライン検査の急速な成長をもたらしている。
OSAT(Outsourced Semiconductor Assembly and Test)は二つのことを担当している:
裸ダイを使えるチップに封入(封装)
チップが使えるかどうかの検証(テスト)
過去はこれは低技術・低利益率の工程だった。しかし、AI時代に入って状況は変わった:
マルチダイ集積(チップレット)
HBMの積層
ナノメートル級の位置合わせ要求(ハイブリッドボンディング)
封装は今や次のように変化している:
性能のボトルネック + 良品率のボトルネック + コストのボトルネック
インラインは一つの生産方式:すべての工程を連続して完了し、生産過程でリアルタイムに検査とフィードバックを行う(クローズドループ)
これに対応するもう一つの工程はオフライン:完了後に検査(オープンループ)
先進封装におけるインライ
- 報酬
- 1
- 1
- リポスト
- 共有
ybaser:
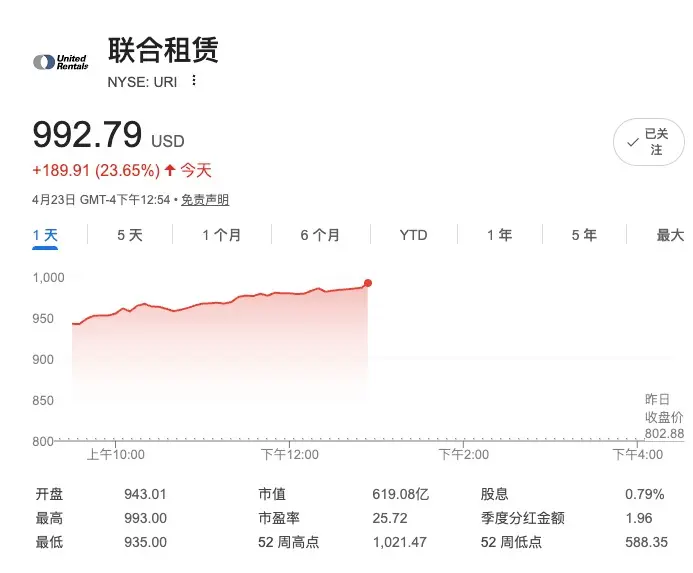
ただ充電して終わり 👊ユナイテッドレンタル (URI)、昨日の決算発表後、今日20%以上の大幅上昇!
これはaidcの激しい計算能力競争の大サイクルの中で、市場が見落としているこれら巨大な存在を支える「重厚な後方支援」だ。
1. 業績概要:史上最高、見通しを引き上げ
URIは今四半期で満点の結果を出した:
売上高と利益: 総売上高は398.5百万ドル、調整後EPSは9.71ドル。
コア効率: 特殊要因を除いたレンタル利益率は継続的に向上し、車両隊の生産性は2.3%増加。
株主還元: 四半期内に自社株買いと配当で5億ドルを還元し、キャッシュフローは極めて潤沢だ。最も重要なシグナルは、経営陣が「大型プロジェクトの勢い」に基づき年間業績見通しを引き上げたことで、強い成長への自信を示している。
2. ビジネスモデル: 「掘削機レンタル」から「システムソリューション」へ
URIの事業は二つの部分で構成される:
一般レンタル: 建築や工業用の基礎設備(高所作業台、土工機械など)をカバー。
専門レンタル: 電力供給(大型発電機)、精密温度管理(工業用HVAC)、流体処理を提供。この「ワンストップ」モデルにより、大規模工事において代替不可能なパートナーとなっている。
3. AIDC: URI成長の「秘密の燃料」
なぜAIDCのインフラ整備がURIにとってこれほど重要なのか?
電力と温度管理に重く依存: AIDCの建設と
原文表示これはaidcの激しい計算能力競争の大サイクルの中で、市場が見落としているこれら巨大な存在を支える「重厚な後方支援」だ。
1. 業績概要:史上最高、見通しを引き上げ
URIは今四半期で満点の結果を出した:
売上高と利益: 総売上高は398.5百万ドル、調整後EPSは9.71ドル。
コア効率: 特殊要因を除いたレンタル利益率は継続的に向上し、車両隊の生産性は2.3%増加。
株主還元: 四半期内に自社株買いと配当で5億ドルを還元し、キャッシュフローは極めて潤沢だ。最も重要なシグナルは、経営陣が「大型プロジェクトの勢い」に基づき年間業績見通しを引き上げたことで、強い成長への自信を示している。
2. ビジネスモデル: 「掘削機レンタル」から「システムソリューション」へ
URIの事業は二つの部分で構成される:
一般レンタル: 建築や工業用の基礎設備(高所作業台、土工機械など)をカバー。
専門レンタル: 電力供給(大型発電機)、精密温度管理(工業用HVAC)、流体処理を提供。この「ワンストップ」モデルにより、大規模工事において代替不可能なパートナーとなっている。
3. AIDC: URI成長の「秘密の燃料」
なぜAIDCのインフラ整備がURIにとってこれほど重要なのか?
電力と温度管理に重く依存: AIDCの建設と
- 報酬
- いいね
- コメント
- リポスト
- 共有
ユナイテッドレンタル (URI)、昨日の決算発表後、今日20%以上の大幅上昇!
これはaidcの激しい計算能力競争の大サイクルの中で、市場が見落としているこれら巨大な存在を支える「重厚な後方支援」だ。
1. 業績概要:史上最高、見通しを引き上げ
URIは今四半期で満点の結果を出した:
売上高と利益: 総売上高は398.5百万ドル、調整後EPSは9.71ドル。
コア効率: 特殊要因を除いたレンタル利益率は継続的に向上し、車両隊の生産性は2.3%増加。
株主還元: 四半期内に株式買い戻しと配当で5億ドルを還元し、キャッシュフローは極めて潤沢だ。最も重要なシグナルは、経営陣が「大型プロジェクトの勢い」に基づき年間業績見通しを引き上げたことで、強い成長への自信を示している。
2. ビジネスモデル: 「掘削機レンタル」から「システムソリューション」へ
URIの事業は二つの部分で構成される:
一般レンタル: 建築や工業用の基礎設備(高所作業台、土工機械など)をカバー。
専門レンタル: 電力供給(大型発電機)、精密温度管理(工業用HVAC)、流体処理を提供。この「ワンストップ」モデルにより、大規模工事において代替不可能なパートナーとなっている。
3. AIDC: URI成長の「秘密の燃料」
なぜAIDCの建設がURIにとってこれほど重要なのか?
電力と温度管理に重く依存: AIDCの建設とテスト
原文表示これはaidcの激しい計算能力競争の大サイクルの中で、市場が見落としているこれら巨大な存在を支える「重厚な後方支援」だ。
1. 業績概要:史上最高、見通しを引き上げ
URIは今四半期で満点の結果を出した:
売上高と利益: 総売上高は398.5百万ドル、調整後EPSは9.71ドル。
コア効率: 特殊要因を除いたレンタル利益率は継続的に向上し、車両隊の生産性は2.3%増加。
株主還元: 四半期内に株式買い戻しと配当で5億ドルを還元し、キャッシュフローは極めて潤沢だ。最も重要なシグナルは、経営陣が「大型プロジェクトの勢い」に基づき年間業績見通しを引き上げたことで、強い成長への自信を示している。
2. ビジネスモデル: 「掘削機レンタル」から「システムソリューション」へ
URIの事業は二つの部分で構成される:
一般レンタル: 建築や工業用の基礎設備(高所作業台、土工機械など)をカバー。
専門レンタル: 電力供給(大型発電機)、精密温度管理(工業用HVAC)、流体処理を提供。この「ワンストップ」モデルにより、大規模工事において代替不可能なパートナーとなっている。
3. AIDC: URI成長の「秘密の燃料」
なぜAIDCの建設がURIにとってこれほど重要なのか?
電力と温度管理に重く依存: AIDCの建設とテスト
- 報酬
- 1
- 1
- リポスト
- 共有
HighAmbition:
ダイヤモンドハンズ 💎テキサス・インスツルメンツ($TXN)の第1四半期決算、予想を大きく上回る:
1株当たり利益(EPS):1.68ドル(予想1.38ドル)
売上高:483億ドル(予想453億ドル)
営業利益:181億ドル(予想154億ドル)
フリーキャッシュフロー:140億ドル(予想120億ドル)
資本支出(CapEx):67.6億ドル(予想68.99億ドル)
シミュレーターチップ収入:392億ドル(予想368億ドル)
第2四半期の業績見通し:
予想1株当たり利益(EPS):1.77–2.05ドル
予想売上高:500億–540億ドル
最も重要なシミュレーション事業さえも、市場の悲観的な見方を明らかに上回った。
決算発表は、3つのより重要なシグナルを示している。
第一に、シミュレーターチップ業界の在庫サイクルはほぼ終了に近づいており、セクター全体に再評価の余地がある。
第二に、工業需要は市場予想よりも強く、世界的な製造業は想像ほど弱くない。
第三に、TXNはサイクルの底でも依然として高い収益性を維持しており、単なるサイクル企業ではなく、構造的な優位性を持つ長期的な勝者であることを示している。
このAIサイクルにおいて、需要の伝達経路は計算能力から電源、次にシミュレーションとパワーデバイスへと伸びている。
TXNはこのチェーンの中下流に位置している。AI投資が継続的に拡大するにつれ、この部分の需要は徐々
原文表示1株当たり利益(EPS):1.68ドル(予想1.38ドル)
売上高:483億ドル(予想453億ドル)
営業利益:181億ドル(予想154億ドル)
フリーキャッシュフロー:140億ドル(予想120億ドル)
資本支出(CapEx):67.6億ドル(予想68.99億ドル)
シミュレーターチップ収入:392億ドル(予想368億ドル)
第2四半期の業績見通し:
予想1株当たり利益(EPS):1.77–2.05ドル
予想売上高:500億–540億ドル
最も重要なシミュレーション事業さえも、市場の悲観的な見方を明らかに上回った。
決算発表は、3つのより重要なシグナルを示している。
第一に、シミュレーターチップ業界の在庫サイクルはほぼ終了に近づいており、セクター全体に再評価の余地がある。
第二に、工業需要は市場予想よりも強く、世界的な製造業は想像ほど弱くない。
第三に、TXNはサイクルの底でも依然として高い収益性を維持しており、単なるサイクル企業ではなく、構造的な優位性を持つ長期的な勝者であることを示している。
このAIサイクルにおいて、需要の伝達経路は計算能力から電源、次にシミュレーションとパワーデバイスへと伸びている。
TXNはこのチェーンの中下流に位置している。AI投資が継続的に拡大するにつれ、この部分の需要は徐々
- 報酬
- 1
- コメント
- リポスト
- 共有
ラムリサーチの決算前予測
LRCXが間もなく発表する決算のポイントは、実はLRCXがAIサイクルの中でどの位置にいるのか、そしてその変化が産業チェーン全体にどのように伝わるのかということにある。
LRCXは単なる装置メーカーではなく、工程の複雑さの恩恵を受ける典型的な企業である。
AIによる変化は、単に計算能力の需要増加だけでなく、チップ製造プロセス自体の複雑さが急速に高まっていることにある:HBMの積層層数の増加、TSV深穴エッチングの難易度の向上、3D NAND層数の物理的限界への接近、2nm/GAA構造の三次元化。これらの変化の共通の結果は、1つのウエハーあたりのエッチングと堆積工程の数が著しく増加し、難易度も高まることだ。
これは、LRCXの成長ロジックが「生産能力の拡大」だけに依存しているのではなく、「工程密度の向上」からより多くの恩恵を受けていることを意味する。
したがって、決算が予想を上回るかどうかは最も重要なポイントではなく、重要なのは期待差がどこから生じているかだ。決算結果に影響を与える核心変数は五つに要約できる:期待がすでに引き上げられているかどうか、注文がスムーズに収益に変わっているかどうか、収益構造がAIや先進パッケージングから来ているかどうか、サービス事業が安定しているかどうか、そして経営陣の指針が保守的かどうか。
しかし、市場の反
原文表示LRCXが間もなく発表する決算のポイントは、実はLRCXがAIサイクルの中でどの位置にいるのか、そしてその変化が産業チェーン全体にどのように伝わるのかということにある。
LRCXは単なる装置メーカーではなく、工程の複雑さの恩恵を受ける典型的な企業である。
AIによる変化は、単に計算能力の需要増加だけでなく、チップ製造プロセス自体の複雑さが急速に高まっていることにある:HBMの積層層数の増加、TSV深穴エッチングの難易度の向上、3D NAND層数の物理的限界への接近、2nm/GAA構造の三次元化。これらの変化の共通の結果は、1つのウエハーあたりのエッチングと堆積工程の数が著しく増加し、難易度も高まることだ。
これは、LRCXの成長ロジックが「生産能力の拡大」だけに依存しているのではなく、「工程密度の向上」からより多くの恩恵を受けていることを意味する。
したがって、決算が予想を上回るかどうかは最も重要なポイントではなく、重要なのは期待差がどこから生じているかだ。決算結果に影響を与える核心変数は五つに要約できる:期待がすでに引き上げられているかどうか、注文がスムーズに収益に変わっているかどうか、収益構造がAIや先進パッケージングから来ているかどうか、サービス事業が安定しているかどうか、そして経営陣の指針が保守的かどうか。
しかし、市場の反

- 報酬
- 1
- 1
- リポスト
- 共有
HighAmbition:
強気市場はピークに達しています 🐂ケビン・ウォッシュの議会証言はかなり強硬ですか?
「金融政策の独立性は極めて重要です。決定は国家の利益を最優先にし、厳密な分析、十分な議論、明確な判断に基づくべきです。」
私は普通だと思います。さもなければ彼は何を言えるでしょうか?
連邦準備制度の独立性を維持することに表立って賛同しなければ、議会の承認を得られるでしょうか?
原文表示「金融政策の独立性は極めて重要です。決定は国家の利益を最優先にし、厳密な分析、十分な議論、明確な判断に基づくべきです。」
私は普通だと思います。さもなければ彼は何を言えるでしょうか?
連邦準備制度の独立性を維持することに表立って賛同しなければ、議会の承認を得られるでしょうか?
- 報酬
- いいね
- コメント
- リポスト
- 共有
訓練不足推論補
推論不足代理補
代理複雜約束補
約束麻煩大家補
だから、加速計算は知能であり、汎用計算もそうだ
AGIへの道のりで、ストレージ、GPU、CPUはすべて絞り尽くされ、深刻な不足に陥る
原文表示推論不足代理補
代理複雜約束補
約束麻煩大家補
だから、加速計算は知能であり、汎用計算もそうだ
AGIへの道のりで、ストレージ、GPU、CPUはすべて絞り尽くされ、深刻な不足に陥る
- 報酬
- いいね
- コメント
- リポスト
- 共有
harness,我最喜欢的翻译是
約束
所以harness engjneer
應該叫做
約束工程
原文表示約束
所以harness engjneer
應該叫做
約束工程
- 報酬
- いいね
- コメント
- リポスト
- 共有
BWX Technologies 最近宣布收购 Precision Components Group,这是一次产能扩张,新增的50万平方英尺厂房和400多名熟练工人,在核能需求重新启动的周期里,是能稳定交付的制造能力的保证。
核能正在进入一个新的上行周期。AI带来的电力需求增长,叠加政策推动的小型模块化反应堆(SMR)和能源结构转型,使核能重新成为“稳定基荷电源”。
供需缺口急剧拉大。尤其是在美国,本土核工业制造能力长期萎缩,具备认证、工艺和经验的生产体系极难复制。核级设备涉及严格的认证体系和极长的验证周期,不是资本投入就能快速扩出来的产能。
这使得行业的竞争逻辑发生变化。和之前的be逻辑类似,重要的是制造和按时交付。BWXT通过这次收购,把自身从“接单能力”进一步推向“交付能力”。
如果用类半导体产业链的视角去看,核能产业链也在逐渐出现类似“ASML / KLA”的角色。真正的核心在那些具备高认证、高复杂制造能力、且产能极难复制的供应层。
BWXT本身就是这一类公司,更接近“复杂度收费者”的角色。类似的还有 Curtiss-Wright,在泵、阀门和控制系统等关键部件上形成长期绑定,一旦进入供应链,生命周期可以锁定几十年。Chart Industries 则属于跨能源体系的设备提供商,类似更广义的“卖水人”。
相比之下,像 Westinghouse Electric Compan
核能正在进入一个新的上行周期。AI带来的电力需求增长,叠加政策推动的小型模块化反应堆(SMR)和能源结构转型,使核能重新成为“稳定基荷电源”。
供需缺口急剧拉大。尤其是在美国,本土核工业制造能力长期萎缩,具备认证、工艺和经验的生产体系极难复制。核级设备涉及严格的认证体系和极长的验证周期,不是资本投入就能快速扩出来的产能。
这使得行业的竞争逻辑发生变化。和之前的be逻辑类似,重要的是制造和按时交付。BWXT通过这次收购,把自身从“接单能力”进一步推向“交付能力”。
如果用类半导体产业链的视角去看,核能产业链也在逐渐出现类似“ASML / KLA”的角色。真正的核心在那些具备高认证、高复杂制造能力、且产能极难复制的供应层。
BWXT本身就是这一类公司,更接近“复杂度收费者”的角色。类似的还有 Curtiss-Wright,在泵、阀门和控制系统等关键部件上形成长期绑定,一旦进入供应链,生命周期可以锁定几十年。Chart Industries 则属于跨能源体系的设备提供商,类似更广义的“卖水人”。
相比之下,像 Westinghouse Electric Compan

- 報酬
- いいね
- コメント
- リポスト
- 共有
私のClaude opus 4.7になった
皆さんも使い始めたでしょうか?
原文表示皆さんも使い始めたでしょうか?
- 報酬
- いいね
- コメント
- リポスト
- 共有
モデルはアプリケーションであり、計算力はモデルであり、一瞬は永遠である
—- mythosリリースの感想
過去数年にわたり、プロンプトワードMCP、ワークフローskillからharness engineeringへの絶え間ない進化を経て、市場はすでにほぼ理解しているはずだ、
モデルはアプリケーションであると。
次に、十分な計算力を持つモデル企業のイテレーション速度がますます速くなるにつれて、市場は徐々に気づくだろう、
計算力はモデルであると、
methosのリリースとともに、計算力の優位性を持つトップモデルがリードを拡大し続け、一時的なリードが超えられない加速度へと変わり、最終的に、
一瞬は永遠である
原文表示—- mythosリリースの感想
過去数年にわたり、プロンプトワードMCP、ワークフローskillからharness engineeringへの絶え間ない進化を経て、市場はすでにほぼ理解しているはずだ、
モデルはアプリケーションであると。
次に、十分な計算力を持つモデル企業のイテレーション速度がますます速くなるにつれて、市場は徐々に気づくだろう、
計算力はモデルであると、
methosのリリースとともに、計算力の優位性を持つトップモデルがリードを拡大し続け、一時的なリードが超えられない加速度へと変わり、最終的に、
一瞬は永遠である
- 報酬
- 2
- コメント
- リポスト
- 共有
モデルはアプリケーションであり、計算能力はモデルであり、一瞬は永遠である
—- mythosリリースの感想
過去数年にわたり、プロンプトワードMCP、ワークフローskillからharness engineeringへの絶え間ない進化を経て、市場はすでに基本的に理解しているはずだ、
モデルはアプリケーションであると。
次に、複数の計算能力を持つモデル企業の進化速度がますます速くなるにつれて、市場は徐々に気づくだろう、
計算能力はモデルであると、
methosのリリースとともに、計算能力の優位性を持つトップモデルがリードを拡大し続け、一時的なリードが超えられない加速度へと変わり、最終的に、
一瞬は永遠である
原文表示—- mythosリリースの感想
過去数年にわたり、プロンプトワードMCP、ワークフローskillからharness engineeringへの絶え間ない進化を経て、市場はすでに基本的に理解しているはずだ、
モデルはアプリケーションであると。
次に、複数の計算能力を持つモデル企業の進化速度がますます速くなるにつれて、市場は徐々に気づくだろう、
計算能力はモデルであると、
methosのリリースとともに、計算能力の優位性を持つトップモデルがリードを拡大し続け、一時的なリードが超えられない加速度へと変わり、最終的に、
一瞬は永遠である
- 報酬
- 1
- コメント
- リポスト
- 共有
以前の俄乌冲突では、民主党がウクライナの戦火を煽り、混乱を引き起こし、その後トランプが撤兵して放置し、同盟国に負担を押し付けた。
今回はイランの時間が足りなかったため、トランプは一つの劇の二つの役割を演じ、直接火をつけて混乱を生み出し、そのまま放置して同盟国に負担を負わせた。
原文表示今回はイランの時間が足りなかったため、トランプは一つの劇の二つの役割を演じ、直接火をつけて混乱を生み出し、そのまま放置して同盟国に負担を負わせた。

- 報酬
- 1
- コメント
- リポスト
- 共有
人気の話題
もっと見る265.4K 人気度
325.75K 人気度
33.96K 人気度
114.56K 人気度
504.43K 人気度
ピン