Google's Gemini 3 Deep Think ยกระดับครั้งใหญ่: ความสามารถในการวิเคราะห์เปรียบเทียบกับ Opus 4.6, GPT-5.2 เพื่อเป็น "AI ที่เก่งด้านงานวิจัยมากที่สุด"
กูเกิลประกาศอัปเดตใหญ่ Gemini 3 Deep Think ในวันที่ 13 โดยในชุดทดสอบ ARC-AGI-2 ซึ่งเป็นการทดสอบเชิงตรรกะที่เน้นความสามารถในการสรุปกฎเกณฑ์จากตัวอย่างหลายๆ ตัว Gemini 3 Deep Think ทำได้ถึง 84.6% ซึ่งสูงกว่าคู่แข่งอย่าง Claude Opus 4.6 (68.8%) และ GPT-5.2 (52.9%) อย่างมาก พร้อมทั้งยังได้ระดับ “ปรมาจารย์ตำนาน” ใน Codeforces
(เรื่องราวก่อนหน้า: การเรียนรู้ของ ChatGPT เปิดตัว: ยามรุ่งอรุณของครูสอนพิเศษ หรือยุคทองของการศึกษา?)
(ข้อมูลเสริม: กูเกิลเปิดตัวอย่างเป็นทางการ “Gemini 3”! ขึ้นเป็น AI ที่ฉลาดที่สุดในโลก จุดเด่นคืออะไร?)
สารบัญบทความ
- ไม่ใช่แค่สอบได้ ยังจับผิดมนุษย์ได้ด้วย
- การเปลี่ยนแปลงของส่วนแบ่งตลาด
- ผลกระทบต่ออุตสาหกรรมคริปโต
- การเริ่มต้นของยุทธศาสตร์วิทยาศาสตร์
กูเกิลในวันนี้ (13) ได้ประกาศอัปเกรดครั้งสำคัญของ Gemini 3 Deep Think ในชุดทดสอบ ARC-AGI-2 ซึ่งเป็นการทดสอบเชิงตรรกะที่เน้นความสามารถในการสรุปกฎเกณฑ์จากตัวอย่างหลายๆ ตัว Gemini 3 Deep Think ทำคะแนนได้ถึง 84.6%
เพื่อเปรียบเทียบ Claude Opus 4.6 (ในโหมด Thinking Max) ได้ 68.8% และ GPT-5.2 (ในโหมด Thinking xhigh) ได้ 52.9% ในขณะที่มนุษย์เฉลี่ยอยู่ที่ประมาณ 60%
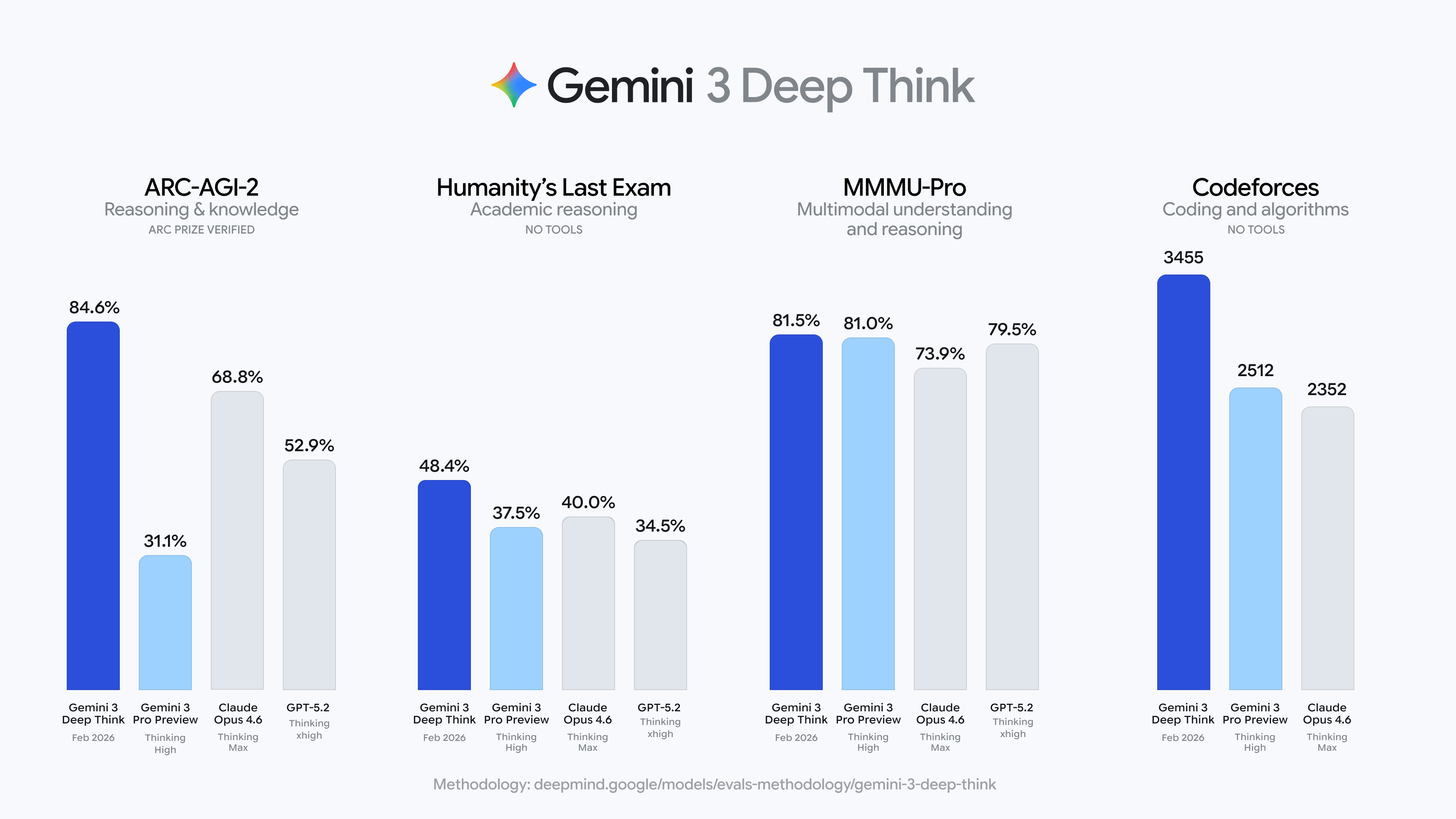
ที่น่าทึ่งยิ่งกว่านั้น ในชุดทดสอบ ARC-AGI-1 รุ่นเดิม Deep Think ทำได้ถึง 96% ซึ่งถือเป็นการผลักดันขีดจำกัดของการทดสอบที่เคยถูกมองว่าเป็น “หนึ่งในข้อสอบที่ยากที่สุดของ AI” ไปจนถึงเพดานสูงสุด
Deep Think ขณะนี้เปิดให้สมาชิก Google AI Ultra ใช้งานผ่าน API สำหรับองค์กรในช่วงเบต้าแรก
ไม่ใช่แค่สอบได้ ยังจับผิดมนุษย์ได้ด้วย
นอกจากผลคะแนนแล้ว กูเกิลยังเผยรายละเอียดว่า Deep Think สามารถตรวจพบข้อผิดพลาดเชิงตรรกะในบทความวิชาการคณิตศาสตร์ที่ผ่านการรีวิวโดยเพื่อนนักวิจัย ซึ่งบทความนี้ได้รับการยืนยันจากนักคณิตศาสตร์จากมหาวิทยาลัย Rutgers
ความสำคัญของกรณีนี้อยู่ที่มันไม่ใช่แค่การแสดงความสามารถในข้อสอบมาตรฐาน แต่เป็นการแสดงความสามารถในสถานการณ์วิทยาศาสตร์จริง การรีวิวโดยเพื่อนนักวิจัยเป็นกลไกควบคุมคุณภาพที่สำคัญที่สุดในวงการวิชาการ หาก AI สามารถสนับสนุนในกระบวนการนี้อย่างมั่นคง มันจะเร่งรัดการวิจัยทางวิทยาศาสตร์ได้มากกว่าการวัดผลคะแนนใดๆ
Deep Think ยังสามารถทำคะแนนระดับเหรียญทองในข้อสอบเขียนของโอลิมปิกฟิสิกส์และเคมีระดับนานาชาติในปี 2025 โดยมีคะแนน Elo ใน Codeforces อยู่ที่ 3,455 ซึ่งเทียบเท่ากับ “ปรมาจารย์ตำนาน” ระดับโลก ซึ่งมีนักเขียนโปรแกรมมนุษย์เพียงไม่กี่คนเท่านั้นที่สามารถไปถึงระดับนี้ได้
และใน “การสอบสุดท้ายของมนุษยชาติ” ซึ่งเป็นข้อสอบที่ออกแบบโดยผู้เชี่ยวชาญจากหลายสาขา เพื่อให้ AI ทำได้ยากที่สุด Deep Think ก็ทำได้ 48.4% (โดยไม่ใช้เครื่องมือเสริม) ซึ่งเป็นสถิติใหม่
การเปลี่ยนแปลงของส่วนแบ่งตลาด
การแข่งขันด้านเทคโนโลยีของบริษัทยักษ์ใหญ่ด้าน AI กำลังเปลี่ยนแปลงภาพรวมตลาดอย่างรวดเร็ว ส่วนแบ่งตลาดของ ChatGPT ลดลงจากจุดสูงสุด 87% เหลือประมาณ 68% ขณะที่ Gemini ขึ้นมาเกิน 18% จากน้อยกว่า 5% และ Claude ของ Anthropic ก็ยังคงแย่งชิงตลาดระดับองค์กรอย่างต่อเนื่อง
จุดแข็งของกูเกิลในเกมนี้คือความสามารถในการกระจายสินค้า Gemini ถูกฝังอยู่ในระบบ Android เบราว์เซอร์ Chrome Google Workspace และเครื่องมือค้นหา ซึ่งหมายความว่าแม้ความสามารถของโมเดลจะเทียบเท่าคู่แข่ง แต่กูเกิลก็สามารถใช้ช่องทางการเข้าถึงเพื่อดึงดูดผู้ใช้ได้
แต่ข้อได้เปรียบด้านการกระจายสินค้าก็เป็นดาบสองคม หากประสบการณ์ใช้งาน Gemini ไม่ดีพอ ก็อาจทำให้เสียความเชื่อมั่นของผู้ใช้ได้เร็วกว่าใคร เพราะผู้ใช้เป็น “ผู้รับ” ที่ไม่ได้เลือกเอง ในขณะที่ผู้ใช้ของ OpenAI เป็นกลุ่มที่จ่ายเงินเอง จึงมีความอดทนและความผูกพันสูงกว่า
ผลกระทบต่ออุตสาหกรรมคริปโต
ทุกครั้งที่มีการอัปเกรดในสงครามอาวุธ AI ความต้องการโครงสร้างพื้นฐานด้านการคำนวณก็จะเพิ่มขึ้น ค่าใช้จ่ายในการฝึกโมเดลระดับแนวหน้าก็พุ่งสูงจากหลักร้อยล้านดอลลาร์ในปี 2024 ไปสู่หลักพันล้านในปี 2026 ซึ่งส่งผลต่อสองเรื่องหลัก
เรื่องแรก: การเปลี่ยนแปลงของเหมืองบิทคอยน์ เมื่อกำไรจากการขุดลดลง (เช่น มอร์แกน สแตนลีย์ คาดการณ์ว่าต้นทุนการผลิต BTC อยู่ที่ 77,000 ดอลลาร์ ขณะที่ราคาบิทคอยน์อยู่ราว 66,000 ดอลลาร์) เหมืองขนาดใหญ่ที่มีโครงสร้างพื้นฐานด้านคำนวณจำนวนมากก็เริ่มเปลี่ยนไปให้บริการด้าน AI แทน
ไม่ใช่การ “ถอนตัว” แต่เป็น “เปลี่ยนสายงาน” จากการขุดบิทคอยน์เป็นการให้บริการสัญญาเช่าใช้พลังคำนวณ AI
เรื่องที่สอง: การเล่าเรื่องของโทเคน AI ทุกครั้งที่กูเกิล, OpenAI หรือ Anthropic เปิดตัวอัปเกรดสำคัญ โทเคนที่เกี่ยวข้องกับ AI บนบล็อกเชน เช่น สัญญาเช่าใช้การคำนวณแบบกระจายศูนย์ ก็จะมีการเก็งกำไรระยะสั้น
แต่พื้นฐานของโทเคนเหล่านี้ยังคงมีปัญหาอยู่ คือ การคำนวณแบบกระจายศูนย์ในด้านดีเลย์และความสามารถในการรับส่งข้อมูล ยังห่างไกลจากความต้องการของการฝึก AI ระดับองค์กรอยู่มาก เรื่องราวอาจวิ่งเร็ว แต่โครงสร้างพื้นฐานยังตามไม่ทัน
การเริ่มต้นของยุทธศาสตร์วิทยาศาสตร์
การอัปเกรดของ Deep Think ทำให้กูเกิลกลับมาอยู่ในตำแหน่งผู้นำในการแข่งขัน AI อย่างน้อยในด้านการสรุปเชิงตรรกะและวิทยาศาสตร์ แต่ถ้าสังเกตคำประกาศของกูเกิลอย่างละเอียด จะพบว่ามีการเปลี่ยนทิศทางเล็กน้อยจากการเน้น “AI ที่ฉลาดที่สุด” ไปเป็น “AI ที่เกิดมาเพื่อวิทยาศาสตร์”
เมื่อข้อสอบมาตรฐานของ AI ยิ่งเต็มไปด้วยความแออัดและความแตกต่างยากขึ้น การอ้างว่า “AI ของฉันช่วยทำวิจัยทางวิทยาศาสตร์” กลายเป็นข้อเสนอที่น่าดึงดูดมากกว่าการเน้น “คะแนนสูงสุดในข้อสอบ” หาก Deep Think สามารถสนับสนุนการตรวจสอบโดยเพื่อนนักวิจัยอย่างมั่นคง เร่งการค้นพบยา หรือช่วยในโมเดลฟิสิกส์ที่มนุษย์มองข้าม ก็จะเป็นคุณค่าที่สำคัญกว่าการจัดอันดับในตารางคะแนนเสียอีก
คำถามคือ จาก “สามารถทำคะแนนสูงในข้อสอบ” ไปสู่ “สามารถสนับสนุนงานวิจัยทางวิทยาศาสตร์ในสถานการณ์จริง” ระยะห่างอาจไกลกว่าที่กูเกิลบอกไว้ เพราะข้อสอบมีคำตอบแน่นอน แต่ในวิทยาศาสตร์ไม่มีเสมอไป

btc.bar.articles
ตลาดคริปโตเห็นการฟื้นตัวแม้ความกลัวในช่วงความวุ่นวายทางภูมิรัฐศาสตร์
บริษัทจดทะเบียนในตลาดหุ้นสหรัฐ AEHL เปิดตัวแผนการจัดสรรสินทรัพย์ดิจิทัล "แผนการอัจฉริยะ" และดำเนินการซื้อ BTC ครั้งแรกมูลค่า 1 ล้านดอลลาร์สหรัฐ
กองทุน ETF บิตคอยน์สดของสหรัฐฯ ไหลออก 2.066 พันล้านดอลลาร์ในเดือนกุมภาพันธ์
21财经:香港จะให้คำแนะนำเพื่อชี้แจงทะเบียนผู้ถือใบรับรองหนี้ในสมุดบัญชีแบบกระจายศูนย์ที่สามารถใช้ได้
Bitmine กลับมาซื้ออีกครั้ง! Tom Lee เชื่อมั่นว่า Ethereum มี "3 ปัจจัยบวก" สนับสนุน