In-Depth Analysis of Nesa: Why Does the AI You Use Daily Need Privacy Protection?
This report is authored by Tiger Research. While most people use AI daily, they rarely consider where their data flows. The question Nesa raises is: what happens when you start to confront this issue?
Key Points
- AI has become integrated into daily life, but users often overlook how data is transmitted through centralized servers
- Even the acting director of the US CISA inadvertently leaked confidential documents to ChatGPT
- Nesa reconstructs this process through pre-transmission data transformation (EE) and cross-node splitting (HSS-EE), ensuring no single party can view the raw data
- Academic certification (COLM 2025) and real-world enterprise deployment (Procter & Gamble) give Nesa a first-mover advantage
- Whether the broader market will choose decentralized privacy AI over the familiar centralized APIs remains a critical question
1. Is your data secure?

Source: CISA
In January 2026, Madhu Gottumukkala, acting director of the US cybersecurity agency CISA, uploaded sensitive government documents to ChatGPT simply to summarize and organize contract-related information.
This leak went undetected by ChatGPT, and OpenAI did not report it to the government. Instead, it was caught by the agency’s internal security system and triggered an investigation for violating security protocols.
Even the top US cybersecurity officials use AI daily and have accidentally uploaded confidential materials.
We all know most AI services store user inputs encrypted on central servers. But this encryption is inherently reversible. Under lawful authorization or emergency circumstances, data can be decrypted and disclosed without users knowing what’s happening behind the scenes.
2. Privacy AI for everyday use: Nesa
AI has become part of daily routines—summarizing articles, coding, drafting emails. The real concern, as shown in the previous case, is that even confidential files and personal data are handed over to AI with little awareness of the risks.
The core issue: all this data passes through the service provider’s central server. Even if encrypted, the decryption keys are held by the provider. Why should users trust this arrangement?
User input data can be exposed to third parties through various channels: model training, security audits, legal requests. In enterprise versions, organizational admins can access chat logs; in personal versions, data may also be legally shared under authorized circumstances.

Since AI is now deeply embedded in daily life, it’s time to seriously reconsider privacy issues.
Nesa is a project designed to fundamentally change this structure. It builds a decentralized infrastructure that enables AI inference without entrusting data to a central server. User inputs are processed in encrypted form, and no single node can view the raw data.
3. How does Nesa solve these problems?
Imagine a hospital using Nesa. A doctor wants AI to analyze a patient’s MRI images to detect tumors. In existing AI services, the images are sent directly to OpenAI or Google servers.
With Nesa, the images are mathematically transformed before leaving the doctor’s computer.
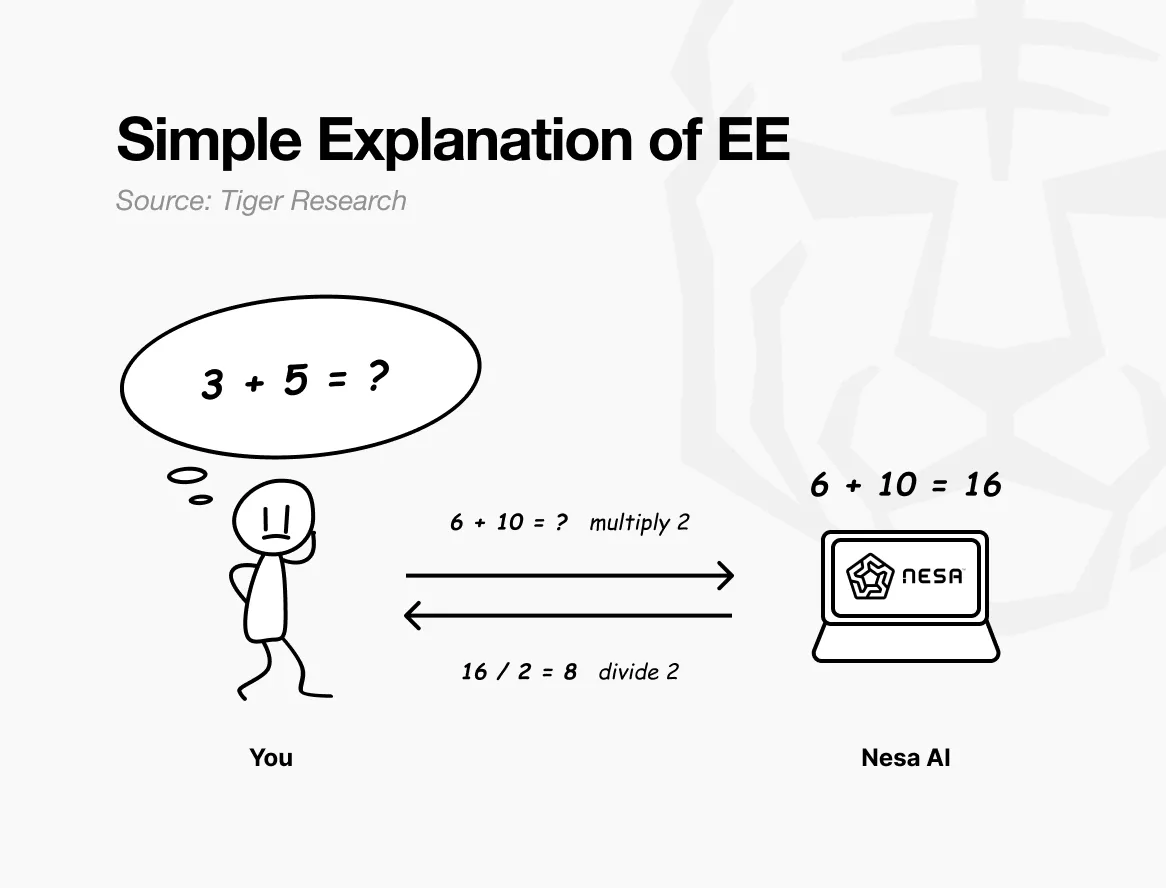
For a simple analogy: suppose the original question is “3 + 5 = ?”. Sending it directly makes it clear what you’re calculating.
But if you multiply each number by 2 before sending, the recipient sees “6 + 10 = ?” and returns 16. You then divide the result by 2 to get 8—which matches the answer to the original question. The recipient performs the calculation without ever knowing your original numbers 3 and 5.
This is exactly what Nesa’s equivariant encryption (EE) achieves. Data undergoes a mathematical transformation before transmission, and the AI model computes on the transformed data.
The user then applies an inverse transformation to obtain the final result, which is identical to what would have been obtained using the raw data. Mathematically, this property is called equivariance: whether you transform then compute, or compute then transform, the final result remains consistent.
In practice, the transformation is far more complex than simple multiplication—it’s tailored to the internal structure of the AI model. Because the transformation aligns perfectly with the model’s processing flow, accuracy is unaffected.
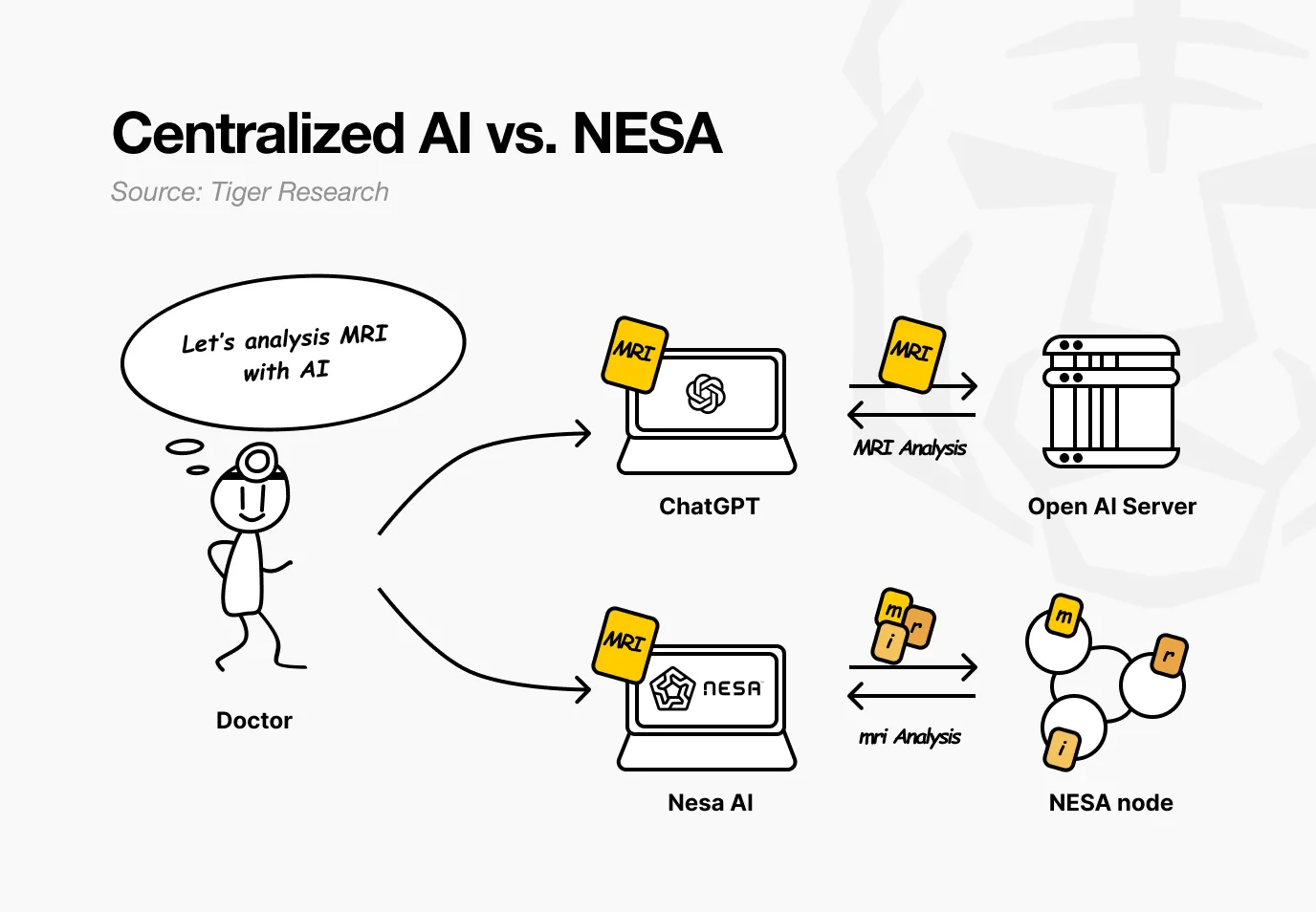
Returning to the hospital scenario: for the doctor, the entire process remains unchanged—upload the image, receive the result, just as before. The difference is that no node in the middle can see the patient’s original MRI.
Nesa goes even further. EE alone can prevent nodes from viewing raw data, but the transformed data still exists in full on a single server.
HSS-EE (Homomorphic Secret Sharing on Encrypted Embeddings) further splits the transformed data.
Continuing the analogy: EE is like applying a multiplication rule before sending the exam paper; HSS-EE is tearing the transformed paper into two halves—sending one part to node A, the other to node B.
Each node can only answer its own part and cannot see the complete question. Only when both parts’ answers are combined can the full result be obtained—and only the original sender can perform this merging.
In short: EE transforms data so the raw content cannot be seen; HSS-EE further splits the transformed data so it can never be fully present in any one place. This double layer of privacy protection significantly enhances security.
4. Will privacy protection slow down performance?
Stronger privacy often means slower performance—this has been a long-standing rule in cryptography. Fully Homomorphic Encryption (FHE), for example, is 10,000 to 1,000,000 times slower than standard computation, making real-time AI services impossible.
Nesa’s equivariant encryption (EE) takes a different approach. To use the math analogy: multiplying by 2 before sending and dividing by 2 after is a negligible cost.
Unlike FHE, which transforms the entire problem into a completely different mathematical system, EE adds a lightweight transformation layer on top of existing computations.
Performance benchmark data:
- EE: latency increase of less than 9% on LLaMA-8B, with accuracy matching the original model at over 99.99%
- HSS-EE: inference time of 700 to 850 milliseconds per run on LLaMA-2 7B
Additionally, MetaInf, a meta-learning scheduler, further optimizes overall network efficiency. It evaluates model size, GPU specs, and input features to automatically select the fastest inference method.
MetaInf achieves 89.8% accuracy in choosing the optimal method, with speeds 1.55 times faster than traditional ML selectors. This result has been published at COLM 2025 and recognized by the academic community.
These data come from controlled testing environments. More importantly, Nesa’s inference infrastructure is already deployed in real enterprise settings, validating production-level performance.
5. Who is using it? How?

There are three ways to access Nesa.
First is Playground. Users can directly select and test models on the web without any development background. You can experience the full process of inputting data and viewing outputs from various models.
This is the fastest way to understand how decentralized AI inference actually works.
Second is Pro subscription. $8 per month, including unlimited access, 1,000 fast inference points per month, custom model pricing control, and a dedicated model showcase page.
This tier is designed for individual developers or small teams who want to deploy and monetize their own models.
Third is Enterprise edition. Not a publicly listed price but a customized contract. Includes SSO/SAML support, optional data storage regions, audit logs, fine-grained access control, and annual billing.
Starting at $20 per user per month, but actual terms depend on scale. It’s tailored for organizations integrating Nesa into their internal AI workflows, providing API access and organizational management via a dedicated agreement.
In summary: Playground for exploration, Pro for individual or small team development, Enterprise for organizational deployment.
6. Why do tokens matter?
Decentralized networks lack a central authority. Entities running servers and verifying results are distributed worldwide. This naturally raises the question: why would anyone keep their GPU running to process AI inference for others?
The answer is economic incentive. In Nesa’s network, this incentive is the $NES token.
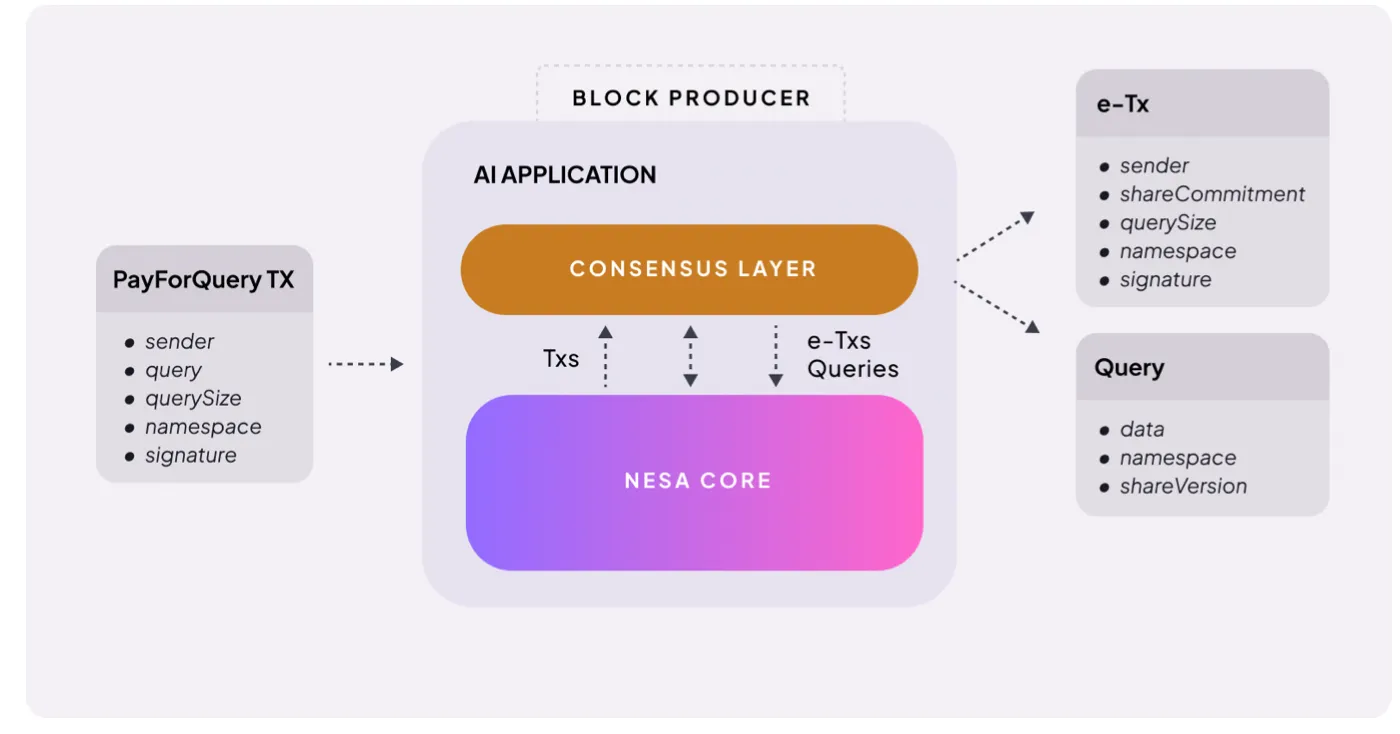
Source: Nesa
The mechanism is straightforward. When a user initiates an AI inference request, they pay a fee. Nesa calls this PayForQuery, composed of a fixed transaction fee plus a variable fee proportional to data volume.
Higher fees mean higher priority—similar to gas fees on blockchain.
These fees are received by miners. To participate, miners must stake a certain amount of $NES—risking their tokens before being assigned tasks.
If a miner returns incorrect results or fails to respond, their stake is penalized; if they process accurately and promptly, they earn higher rewards.
$NES also functions as a governance token. Holders can submit proposals and vote on core network parameters like fee structures and reward ratios.
In short, $NES plays three roles: as a payment method for inference requests, as collateral and rewards for miners, and as a participation credential for network governance. Without tokens, nodes won’t operate; without nodes, privacy AI cannot exist.
It’s important to note that the token economy depends on certain preconditions:
- Sufficient demand for inference services—otherwise, rewards lose meaning
- Rewards are meaningful—miners stay engaged
- Adequate number of miners—network quality is maintained
This creates a positive feedback loop: demand drives supply, and supply sustains demand—but initiating this cycle is the hardest part.
Enterprise clients like P&G are already deploying the network in production, which is a positive sign. But whether the token’s value and mining rewards can stay balanced as the network scales remains to be seen.
7. The necessity of privacy AI
Nesa aims to address a clear problem: changing the structural pattern where user data is exposed to third parties when using AI.
Its technical foundation is solid and reliable. The core encryption technologies—equivariant encryption (EE) and HSS-EE—are rooted in academic research. The inference optimization scheduler MetaInf has been published at COLM 2025.
This isn’t just citing papers; the team has designed protocols and implemented them in the network.
In decentralized AI projects, few can verify their own cryptographic primitives at an academic level and deploy them into operational infrastructure. Large enterprises like P&G are already running inference tasks on this infrastructure—an important signal for early-stage projects.
That said, limitations are also clear:
- Market scope: primarily enterprise clients; average users are unlikely to pay for privacy at this stage
- Product experience: Playground resembles a Web3/investment interface rather than everyday AI apps
- Scale validation: controlled benchmarks ≠ thousands of concurrent nodes in production
- Market timing: demand for privacy AI exists, but decentralized privacy AI remains unproven; enterprises still prefer centralized APIs
Most companies are accustomed to centralized APIs, and blockchain-based infrastructure still has high entry barriers.
We live in an era where even US cybersecurity officials upload confidential files to AI. The demand for privacy AI is real and will only grow.
Nesa offers academically validated technology and operational infrastructure to meet this need. Despite limitations, it already has a head start over other projects.
When the privacy AI market truly opens, Nesa will likely be among the first names mentioned.