內部人士透露 DeepSeek V4 將在程式碼編寫方面超越 Claude 和 ChatGPT,並在數週內推出
Decrypt
簡要說明
- DeepSeek V4 可能在數週內推出,目標是達到精英級的程式碼性能。
- 內部人士聲稱它可能在長上下文程式碼任務中超越 Claude 和 ChatGPT。
- 開發者已經在期待潛在的顛覆性變革。
據報導,DeepSeek 計劃在2月中旬左右推出其 V4 模型,如果內部測試結果具有指標性,矽谷的 AI 巨頭應該會感到緊張。 這家總部位於杭州的 AI 初創公司可能會在農曆新年(自然是2月17日左右)左右發布一款專為程式碼任務設計的模型,根據 The Information 的報導。擁有直接知情人士透露,V4 在內部基準測試中超越了 Anthropic 的 Claude 和 OpenAI 的 GPT 系列,尤其是在處理極長的程式碼提示時表現出色。 當然,目前尚未公開任何關於該模型的基準或資訊,因此無法直接驗證這些說法。DeepSeek 也未證實這些傳聞。
儘管如此,開發者社群並未等待官方消息。Reddit 的 r/DeepSeek 和 r/LocalLLaMA 已經開始熱烈討論,用戶正在囤積 API 點數,X 上的愛好者也迅速分享他們的預測,認為 V4 可能鞏固 DeepSeek 作為一個不願遵循矽谷百億美元規則的勇敢黑馬的地位。
Anthropic 阻止了 Claude 訂閱在第三方應用如 OpenCode 中的使用,並據報導切斷了 xAI 和 OpenAI 的存取權。
Claude 和 Claude Code 很棒,但還沒有達到 10 倍的優勢。這只會促使其他實驗室加快他們的程式碼模型/代理的開發速度。
DeepSeek V4 有傳言將於…
— Jin Yuchen (@Yuchenj_UW) 2026年1月9日
這並非 DeepSeek 的首次顛覆。當公司在2025年1月推出其 R1 推理模型時,引發了全球市場的 $1 兆級拋售。 原因是什麼?DeepSeek 的 R1 在數學和推理基準測試中與 OpenAI 的 o1 模型相匹配,據報導其開發成本僅為 $6 百萬美元——約是競爭對手花費的 68 倍。其 V3 模型後來在 MATH-500 基準測試中達到 90.2%,遠超 Claude 的 78.3%,而最新的“V3.2 Speciale”版本進一步提升了性能。
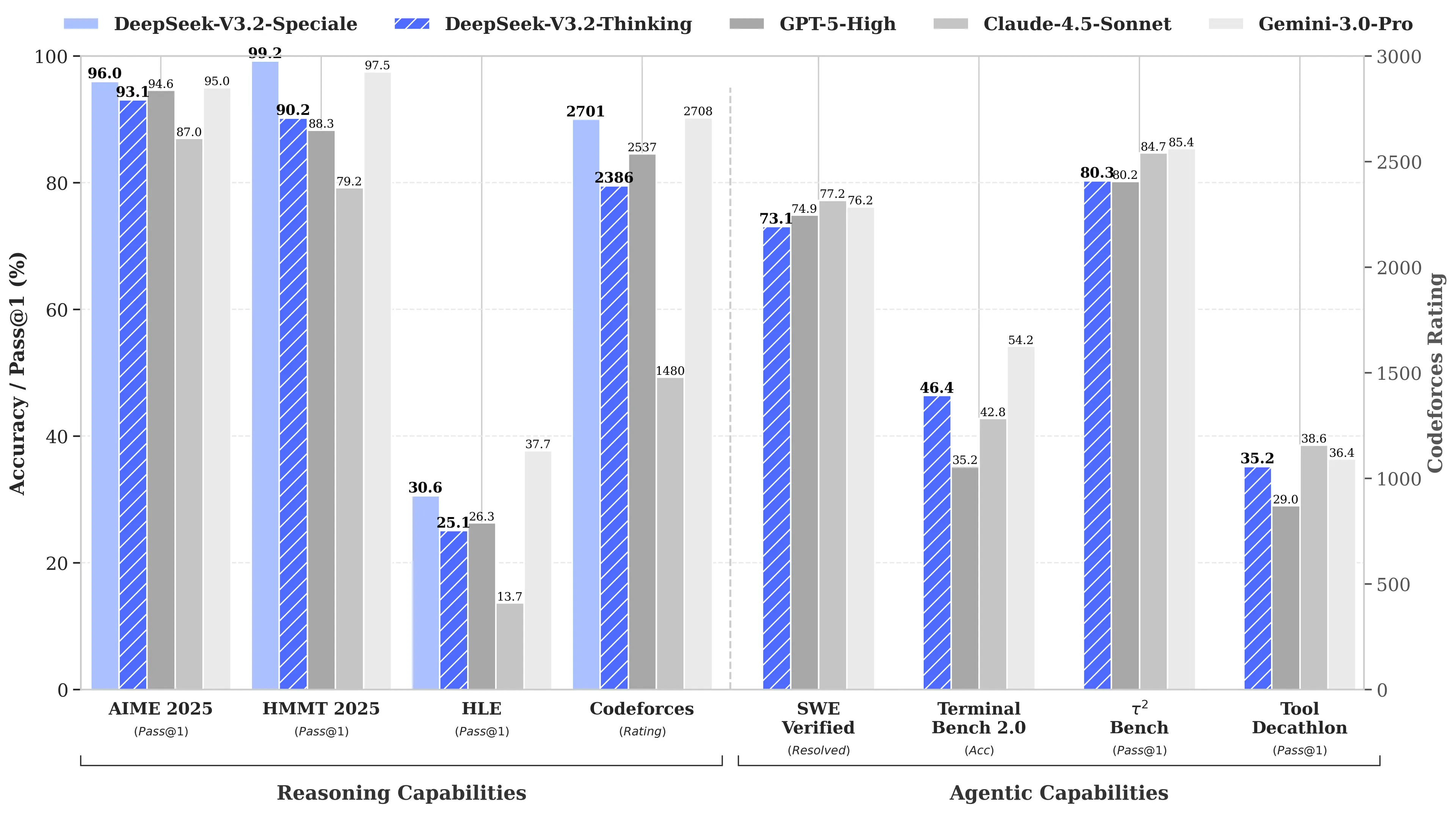
圖片:DeepSeek
V4 的程式碼專注將是策略性轉變。雖然 R1 強調純推理——邏輯、數學、正式證明——V4 則是一個混合模型 (推理與非推理任務),專為企業開發者市場設計,在該市場中,高精度的程式碼生成直接轉化為收入。
若要 claiming 霸主地位,V4 需要超越 Claude Opus 4.5,目前該模型在 SWE-bench Verified 記錄中以 80.9% 領先。但如果以往的發佈經驗作為指標,即使面臨中國 AI 實驗室的各種限制,這也並非不可能實現。
不那麼秘密的秘訣
假設傳聞屬實,這個小型實驗室如何能達成如此成就?
該公司的秘密武器可能藏在其1月1日的研究論文中:Manifold-Constrained Hyper-Connections,或稱 mHC。由創始人梁文峰共同撰寫,這種新的訓練方法解決了擴展大型語言模型的根本問題——如何在不使模型不穩定或訓練爆炸的情況下擴大模型容量。
傳統的 AI 架構將所有資訊強制通過一條狹窄的通道。mHC 將該通道擴展為多個流,能在不導致訓練崩潰的情況下交換資訊。
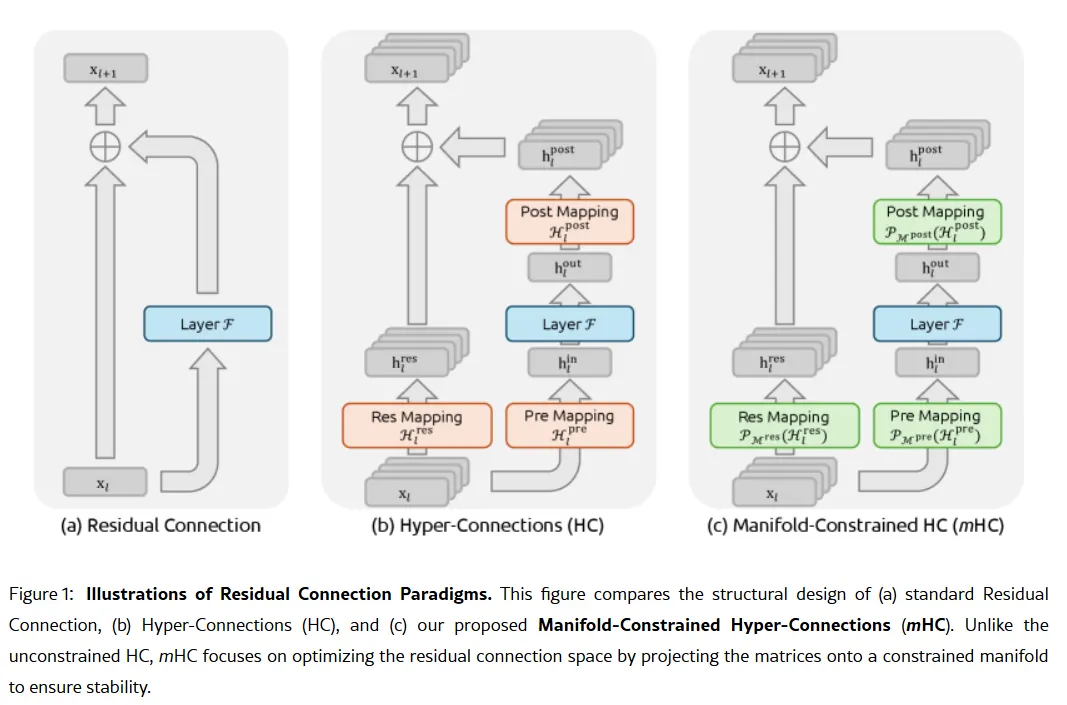
圖片:DeepSeek
Counterpoint Research 的 AI 主要分析師 Sun Wei 在 Business Insider 的評論中稱 mHC 為“令人震驚的突破”。她表示,這項技術顯示 DeepSeek 能“繞過計算瓶頸,並實現智慧的飛躍”,即使在由於美國出口限制而限制了先進晶片的情況下。 Omdia 的首席分析師蘇俊傑指出,DeepSeek 願意公開其方法,顯示出“對中國 AI 產業的新信心”。該公司開源的策略使其成為開發者的寵兒,他們認為這代表了 OpenAI 曾經的模樣,在轉向封閉模型和數十億美元募資之前。
並非所有人都相信。有些 Reddit 開發者抱怨 DeepSeek 的推理模型在簡單任務上浪費計算資源,而批評者則認為該公司基準測試並未反映現實世界的複雜性。一篇標題為“DeepSeek 很爛——我也不再假裝它不爛”的 Medium 文章在2025年4月迅速傳播,指控這些模型產出“充滿錯誤的模板化廢話”和“幻覺式的庫”。
DeepSeek 也帶有包袱。隱私問題一直困擾著該公司,一些政府禁止使用 DeepSeek 的原生應用。該公司與中國的關係以及對模型審查的疑慮,為技術辯論增添了地緣政治的摩擦。
儘管如此,動能是不可否認的。DeepSeek 已在亞洲廣泛採用,如果 V4 在程式碼方面能如預期般表現,西方的企業採用也可能隨之而來。
圖片:微軟
還有時間點的因素。根據 Reuters,DeepSeek 原本計劃在2025年5月推出 R2 模型,但在創始人梁文峰對其性能不滿後延長了開發時間。現在,V4 預計在2月推出,R2 可能在8月跟進,該公司正以一個顯示緊迫感或自信的速度前進——也許兩者兼具。
免責聲明:本頁面資訊可能來自第三方,不代表 Gate 的觀點或意見。頁面顯示的內容僅供參考,不構成任何財務、投資或法律建議。Gate 對資訊的準確性、完整性不作保證,對因使用本資訊而產生的任何損失不承擔責任。虛擬資產投資屬高風險行為,價格波動劇烈,您可能損失全部投資本金。請充分了解相關風險,並根據自身財務狀況和風險承受能力謹慎決策。具體內容詳見聲明。
留言
0/400
00001cl
· 01-15 04:46
又幾把遙遙領先了