أطلقت DeepSeek إصداراتٍ تجريبية من DeepSeek-V4-Pro وDeepSeek-V4-Flash في 24 أبريل 2026، وكلاهما نماذج مفتوحة الأوزان تحتوي على نوافذ سياق بمليون توكن وتسعير أقل بكثير من البدائل الغربية المتقاربة. تبلغ تكلفة نموذج V4-Pro $1.74 لكل مليون توكن إدخال و$3.48 لكل مليون توكن إخراج—أي تقريبًا 1/20 من السعر الذي يطلبه Claude Opus 4.7 و أقل بنسبة 98% من GPT-5.5 Pro، وفقًا للمواصفات الرسمية للشركة.
بنية النموذج والحجم
يتميز DeepSeek-V4-Pro بـ 1.6 تريليون معامل إجمالي، ما يجعله أكبر نموذج مفتوح المصدر في سوق نماذج LLM حتى الآن. ومع ذلك، يتم تفعيل 49 مليار معامل فقط لكل تمريرة استدلال، باستخدام ما تسميه DeepSeek نهج Mixture-of-Experts الذي تم تحسينه منذ V3. يتيح هذا التصميم أن يبقى النموذج بكاملَه خاملاً بينما يتم تفعيل الشرائح ذات الصلة فقط لأي طلب معيّن، مما يقلل تكاليف الحوسبة مع الحفاظ على سعة المعرفة.
يعمل DeepSeek-V4-Flash على نطاق أصغر بإجمالي 284 مليار معامل و13 مليار معامل نشط. ووفقًا لاختبارات DeepSeek القياسية، فإنه “يحقق أداءً استدلاليًا متكافئًا مع إصدار الـ Pro عند تزويده بميزانية تفكير أكبر”.
يدعم كلا النموذجين مليون توكن من السياق كميزة قياسية—أي تقريبًا 750,000 كلمة، أو تقريبًا مجموع ثلاثية “Lord of the Rings” بالكامل مع نص إضافي.
ابتكار تقني: آليات الانتباه على نطاق واسع
عالجت DeepSeek مشكلة التوسع الحسابي الكامنة في معالجة السياق طويل المدى عبر اختراع نوعين جديدين من آليات الانتباه، كما هو موضح في الورقة التقنية للشركة المتاحة على GitHub.
تواجه آليات الانتباه المعيارية في الذكاء الاصطناعي مشكلة توسع قاسية: في كل مرة يتضاعف فيها طول السياق، ترتفع تكلفة الحوسبة تقريبًا إلى أربعة أضعاف. تتضمن حل DeepSeek نهجين متكاملين:
الانتباه المتباعد المضغوط يعمل على خطوتين. فهو يقوم أولاً بضغط مجموعات من التوكنات—على سبيل المثال، كل 4 توكنات—في إدخال واحد. ثم بدلًا من الانتباه إلى جميع الإدخالات المضغوطة، يستخدم “Lightning Indexer” لاختيار النتائج الأكثر صلة فقط لأي استعلام معيّن. يؤدي ذلك إلى تقليص نطاق انتباه النموذج من مليون توكن إلى مجموعة أصغر بكثير من الأجزاء المهمة.
الانتباه المضغوط بشدة يتبع نهجًا أكثر صرامة، حيث يقوم بطيّ كل 128 توكنًا في إدخال واحد دون اختيار متباعد. وعلى الرغم من أن هذا يؤدي إلى فقدان تفاصيل دقيقة، فإنه يوفر نظرة عالمية رخيصة جدًا. تعمل آليتا الانتباه في طبقات متناوبة، مما يتيح للنموذج الحفاظ على كلٍ من التفاصيل والملخص.
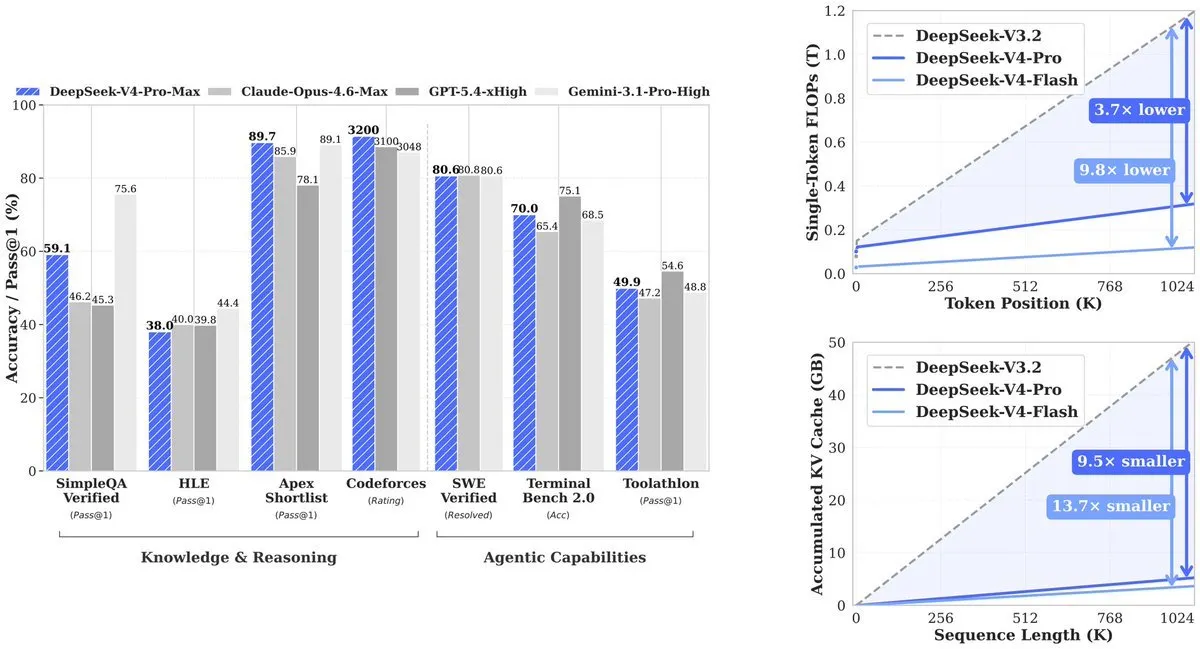
الناتج: يستخدم V4-Pro 27% من الحوسبة التي احتاجها سلفه (V3.2). ينخفض KV cache—وهو الذاكرة اللازمة لتتبع السياق—إلى 10% من V3.2. ويدفع V4-Flash الكفاءة إلى أبعد من ذلك: 10% من الحوسبة و7% من الذاكرة مقارنةً بـ V3.2.
الأداء في الاختبارات والتموقع التنافسي
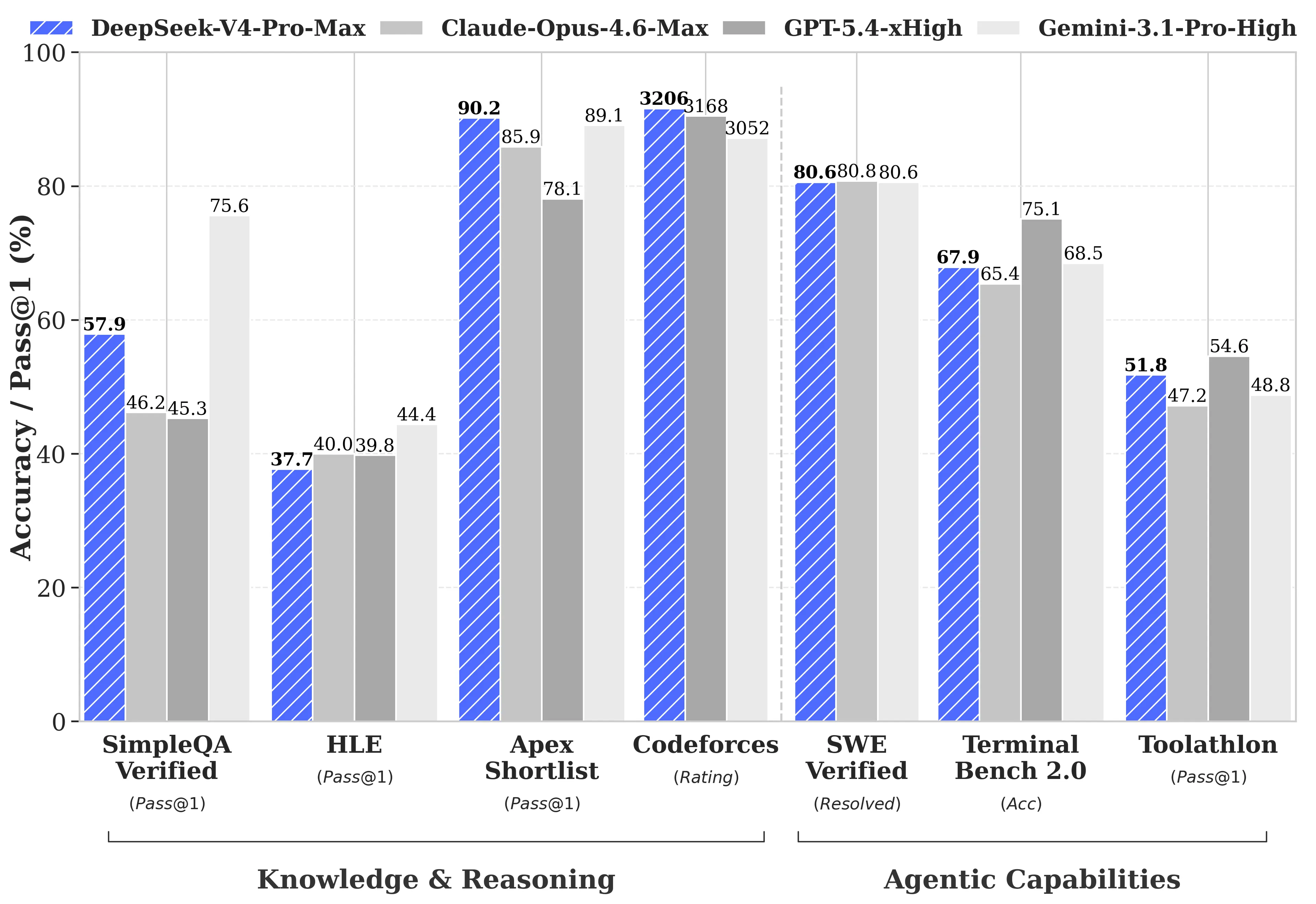
نشرت DeepSeek مقارنات شاملة للأداء القياسي ضد GPT-5.4 وGemini-3.1-Pro، بما في ذلك المجالات التي يتأخر فيها V4-Pro عن المنافسين. في مهام الاستدلال، يتأخر استدلال V4-Pro عن GPT-5.4 وGemini-3.1-Pro بحوالي ثلاثة إلى ستة أشهر، وفقًا للتقرير التقني من DeepSeek.
أين يتفوق V4-Pro:
- Codeforces (برمجة تنافسية): سجل V4-Pro 3,206، أي في حدود المركز 23 بين المشاركين البشر الفعليين في المسابقات
- Apex Shortlist (مشكلات رياضيات وSTEM مُنسقة): معدل اجتياز 90.2% مقابل 85.9% لِـ Opus 4.6 و78.1% لِـ GPT-5.4
- SWE-Verified (حل قضايا GitHub): 80.6%، متطابقًا مع Claude Opus 4.6
أين يتأخر V4-Pro:
- MMLU-Pro (تعدد المهام): Gemini-3.1-Pro عند 91.0% مقابل V4-Pro عند 87.5%
- GPQA Diamond (المعرفة الخبرية): Gemini عند 94.3 مقابل V4-Pro عند 90.1
- Humanity’s Last Exam (مستوى التخرج): Gemini-3.1-Pro عند 44.4% مقابل V4-Pro عند 37.7%
في مهام السياق طويل المدى، يتصدر V4-Pro نماذج open-source ويتفوق على Gemini-3.1-Pro في CorpusQA (محاكاة تحليل وثائق واقعي عند مليون توكن) لكنه يخسر أمام Claude Opus 4.6 في MRCR، الذي يقيس استرجاع معلومات محددة مدفونة بعمق داخل نص طويل.
قدرات الوكلاء والترميز
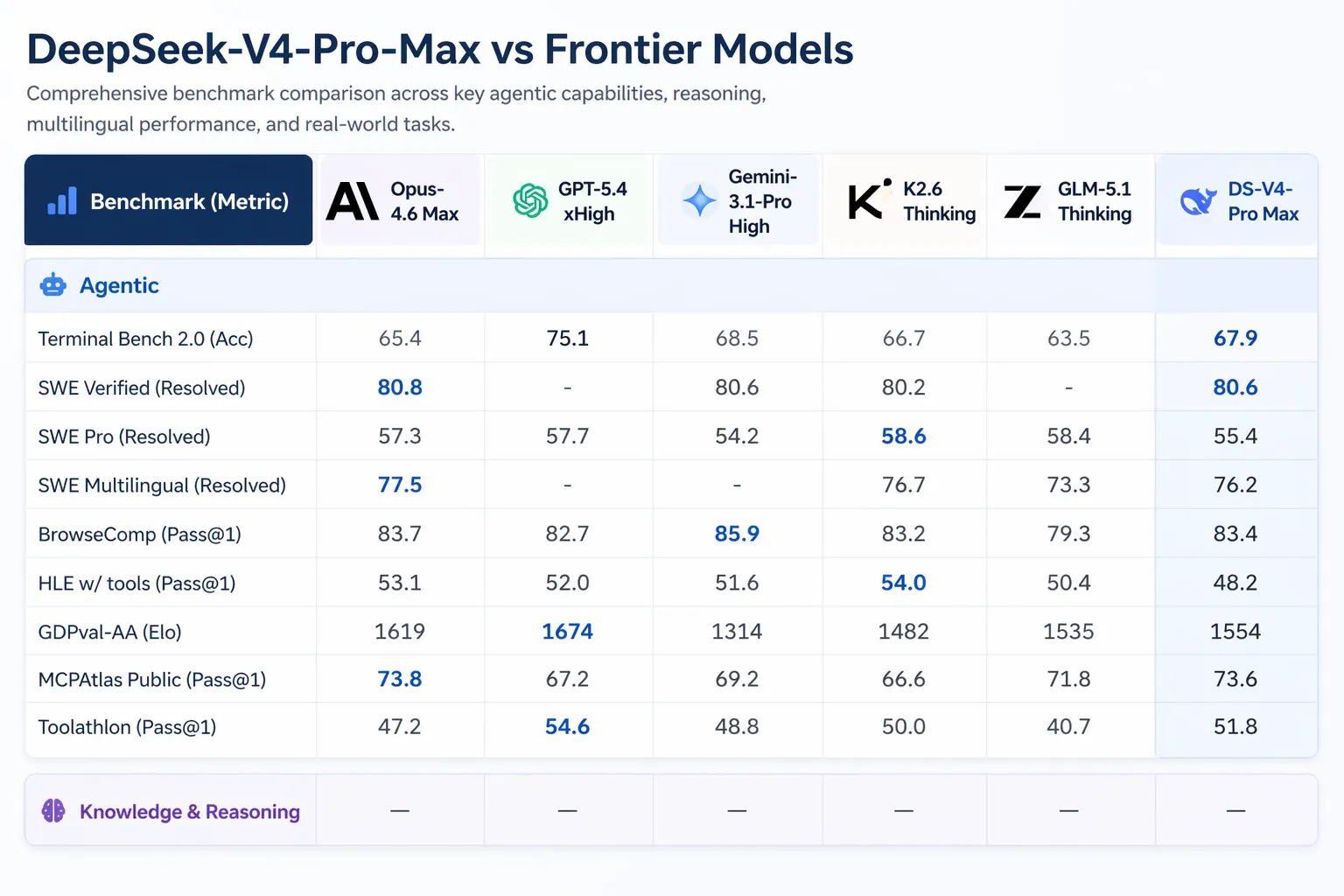
يمكن لـ V4-Pro التشغيل في Claude Code وOpenCode وأدوات ترميز ذكاء اصطناعي أخرى. ووفقًا لمسح DeepSeek الداخلي لِـ 85 مطورًا استخدموا V4-Pro باعتباره وكيل الترميز الأساسي لديهم، قال 52% إنه جاهز ليكون النموذج الافتراضي لديهم، وقال 39% إنهم يميلون إلى نعم، وأقل من 9% قالوا لا. أشارت الاختبارات الداخلية لـ DeepSeek إلى أن V4-Pro يتفوق على Claude Sonnet ويقترب من Claude Opus 4.5 في مهام الترميز الوكيلية.
احتل Artificial Analysis المركز الأول لـ V4-Pro بين جميع نماذج open-weight في GDPval-AA، وهو معيار يختبر أعمال معرفة ذات قيمة اقتصادية عبر مهام التمويل والقانون والبحث. سجل V4-Pro-Max 1,554 Elo، متقدمًا على GLM-5.1 (1,535) وMiniMax’s M2.7 (1,514). تسجل Claude Opus 4.6 1,619 في نفس المعيار.
يقدم V4 “التفكير المتداخل”، والذي يحتفظ بسلسلة التفكير الكاملة عبر نداءات الأدوات. في النماذج السابقة، عندما يقوم الوكيل بعدة نداءات أدوات—مثل البحث في الويب، ثم تشغيل كود، ثم البحث مرة أخرى—كان يتم مسح سياق تفكير النموذج بين الجولات. يحافظ V4 على استمرارية التفكير عبر الخطوات، مما يمنع فقدان السياق في سير العمل الآلي المعقد.
المشهد التنافسي وسياق التسعير
يأتي إصدار V4 في ظل نشاط كبير في مجال الذكاء الاصطناعي. فقد شحنت Anthropic Claude Opus 4.7 في 16 أبريل 2026. وأطلق OpenAI GPT-5.5 في 23 أبريل 2026، مع تسعير GPT-5.5 Pro عند $30 لكل مليون توكن إدخال و $180 لكل مليون توكن إخراج. يتفوق GPT-5.5 على V4-Pro في Terminal Bench 2.0 (82.7% مقابل 70.0%)، والذي يختبر سير عمل معقدة لوكلاء سطر أوامر.
أصدرت Xiaomi MiMo V2.5 Pro في 22 أبريل 2026، مقدمة قدرات multimodal كاملة (image, audio, video) عند $1 إدخال و $3 إخراج لكل مليون توكن. وأصدرت Tencent Hy3 في نفس يوم GPT-5.5.
ولأخذ منظور التسعير: لاحظ الرئيس التنفيذي لـ Cline، Saoud Rizwan، أنه لو أن Uber استخدمت DeepSeek بدلًا من Claude، لكان ميزانيتها للذكاء الاصطناعي في عام 2026—ويُقال إنها كافية لأربعة أشهر من الاستخدام—قد استمرت سبع سنوات.
النشر والتوفر
كلا من V4-Pro وV4-Flash مرخصان وفقًا لترخيص MIT ومتاحتان على Hugging Face. تكون النماذج نصية فقط حاليًا؛ وقد ذكرت DeepSeek أنها تعمل على قدرات multimodal. يمكن تشغيل كلا النموذجين مجانًا على عتاد محلي أو تخصيصهما بناءً على احتياجات الشركة.
تقوم نقاط النهاية deepseek-chat وdeepseek-reasoner الحالية لدى DeepSeek بالفعل بتوجيه المرور إلى V4-Flash في وضعي عدم التفكير والتفكير على التوالي. ستتقاعد نقاط النهاية القديمة deepseek-chat وdeepseek-reasoner في 24 يوليو 2026.
درّبت DeepSeek V4 جزئيًا على رقائق Huawei Ascend، متجاوزةً قيود التصدير الأمريكية. وصرحت الشركة بأنه بمجرد تفعيل 950 عقدًا فائقة جديدة في وقت لاحق من عام 2026، سينخفض سعر نموذج الـ Pro المنخفض أصلًا أكثر.
الآثار العملية
بالنسبة للشركات، قد تتغير حسابات تكلفة-منفعة التسعير. يجعل نموذج يتصدر معايير open-source بسعر 1.74 دولار لكل مليون توكن إدخال معالجة مستندات واسعة النطاق، والمراجعة القانونية، وخطوط توليد الأكواد أرخص بشكل ملحوظ من ستة أشهر سابقة. يتيح سياق مليون توكن معالجة قواعد كود كاملة أو ملفات تنظيمية في طلب واحد بدلًا من تقسيمها عبر مكالمات متعددة.
بالنسبة للمطورين وبناة الأفراد، يُعد V4-Flash هو الاعتبار الأساسي. بسعر 0.14 دولار للإدخال و0.28 دولار للإخراج لكل مليون توكن، فهو أرخص من النماذج التي كانت تُعتبر خيارات ميزانية قبل عام، بينما يتعامل مع معظم المهام التي يديرها إصدار الـ Pro.
إخلاء المسؤولية: قد تكون المعلومات الواردة في هذه الصفحة من مصادر خارجية ولا تمثل آراء أو مواقف Gate. المحتوى المعروض في هذه الصفحة هو لأغراض مرجعية فقط ولا يشكّل أي نصيحة مالية أو استثمارية أو قانونية. لا تضمن Gate دقة أو اكتمال المعلومات، ولا تتحمّل أي مسؤولية عن أي خسائر ناتجة عن استخدام هذه المعلومات. تنطوي الاستثمارات في الأصول الافتراضية على مخاطر عالية وتخضع لتقلبات سعرية كبيرة. قد تخسر كامل رأس المال المستثمر. يرجى فهم المخاطر ذات الصلة فهمًا كاملًا واتخاذ قرارات مدروسة بناءً على وضعك المالي وقدرتك على تحمّل المخاطر. للتفاصيل، يرجى الرجوع إلى
إخلاء المسؤولية.