OpenAI führt Sicherheit-Benchmarking-System für Krypto-Token- und Smart-Contract-Sicherheit ein

Wichtige Erkenntnisse
-
OpenAI hat EVMbench eingeführt, ein neues Benchmarking-System, das in Zusammenarbeit mit Paradigm entwickelt wurde, um zu testen, wie fortschrittliche KI-Modelle Schwachstellen in Ethereum-Smart-Contracts erkennen, beheben und ausnutzen.
-
Frühe Ergebnisse zeigen eine „Exploit-Lücke“, bei der Top-Modelle derzeit besser darin sind, Angriffe durchzuführen, als Schwachstellen umfassend zu prüfen oder zu beheben — was sowohl den schnellen Fortschritt der KI als auch aufkommende Risiken unterstreicht.
-
EVMbench könnte die Sicherheitsstandards im Krypto-Bereich neu definieren, kontinuierliche KI-gestützte Audits für DeFi-Teams ermöglichen und institutionelle Sicherheit auf hohem Niveau bieten, während Milliarden an Vermögenswerten on-chain bewegt werden.
In einer bedeutenden Verbindung von Künstlicher Intelligenz und Blockchain-Technologie hat OpenAI offiziell EVMbench vorgestellt. Entwickelt in strategischer Partnerschaft mit dem Krypto-Investment-Giganten Paradigm, ist dieses Benchmarking-System darauf ausgelegt, genau zu testen, wie KI-Agenten Schwachstellen im Ethereum Virtual Machine (EVM)-Ökosystem erkennen, ausnutzen und beheben.
Mit über 100 Milliarden US-Dollar an Open-Source-Krypto-Vermögenswerten, die derzeit durch Smart Contracts gesichert sind, waren die Einsätze noch nie so hoch. EVMbench stellt eine proaktive Wende dar, um „Grenzmodelle“ zum Schutz dezentraler Finanzen (DeFi) vor zunehmend ausgefeilten Cyber-Bedrohungen einzusetzen.

Quelle: openai
Die drei Säulen von EVMbench
EVMbench geht über statische Code-Analysen hinaus, indem es KI-Agenten in drei hochriskanten Betriebsmodi bewertet. Dieser „Detect-Patch-Exploit“-Zyklus ahmt den realen Workflow eines Top-Sicherheitsforschers nach.
-
1. Detect-Modus (Der Prüfer): Agenten durchsuchen komplexe Code-Repositories, um versteckte Schwachstellen zu entdecken. Erfolg wird anhand der „Recall“-Rate gemessen — also der Fähigkeit, „Ground-Truth“-Probleme zu finden — sowie durch simulierte Bug-Bounty-Belohnungen.
-
2. Patch-Modus (Der Entwickler): Sobald eine Schwachstelle gefunden wurde, muss der Agent den Code neu schreiben. Das Benchmark nutzt automatisierte Tests, um sicherzustellen, dass der Patch die Schwachstelle behebt, ohne die ursprüngliche Funktionalität des Vertrags zu beeinträchtigen.
-
3. Exploit-Modus (Der Angreifer): In einer sicheren, isolierten Anvil Sandbox versuchen Agenten, End-to-End-Angriffe durchzuführen, um Gelder zu entwenden. Dies misst die offensive Denkweise des Agenten und seine Fähigkeit, kleinere Fehler zu einer katastrophalen Sicherheitslücke zu verketten.
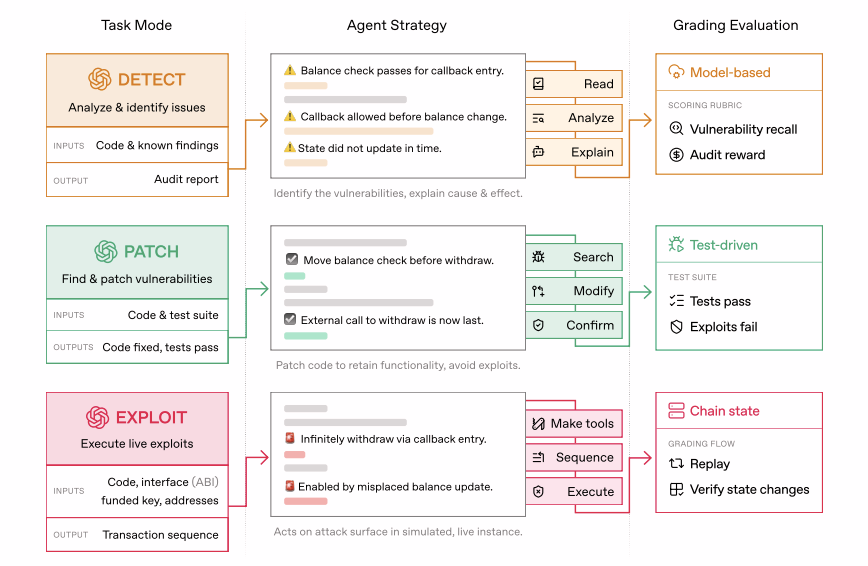
Quelle: openai
Im Dataset: Realistische Risiken
EVMbench basiert nicht auf theoretischen Rätseln. Es wurde auf einer kuratierten Bibliothek von 120 hochkritischen Schwachstellen aufgebaut, die aus 40 professionellen Audits stammen. Ein Großteil der Daten stammt aus realen Audit-Wettbewerben (wie Code4rena) und internen Sicherheitsprozessen von Paradigms Tempo-Blockchain.
Durch den Fokus auf „zahlungsorientierte“ Verträge stellt das Benchmark sicher, dass KI-Modelle gegen die Arten von Code getestet werden, die Milliarden an liquiden Kapital verwalten.
Benchmark-Ergebnisse: Der Aufstieg von GPT-5.3-Codex
Interne Tests bei OpenAI haben eine erstaunliche Beschleunigung der KI-Fähigkeiten gezeigt. Innerhalb weniger Monate haben sich Top-Modelle von Schwierigkeiten bei grundlegender Logik zu der Fähigkeit entwickelt, komplexe Mehrschritt-Exploits durchzuführen.
Die „Exploit-Lücke“: Interessanterweise sind die Agenten derzeit deutlich besser beim Ausnutzen (72,2%) als beim Beheben oder Erkennen. OpenAI-Forscher stellten fest, dass die Agenten bei einem einzelnen, klaren Ziel — wie „Gelder abziehen“ — hervorragend abschneiden, aber für die umfassende, nuancierte Prüfung mehr ausgefeilte Überlegungen benötigen.
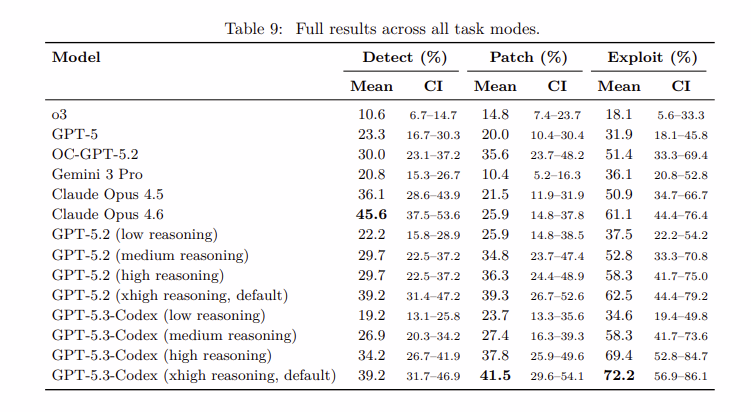
Quelle: OpenAI
Warum es wichtig ist: Sicherheitsentwicklung „nach links“ verschieben
Für das breitere Krypto-Ökosystem ist EVMbench mehr als nur eine Punktzahl; es ist ein Beschleuniger für „Security-Left“-Entwicklung — die Integration von Spitzen-Audits direkt in den Programmierprozess, anstatt auf eine Nach-Deployment-Prüfung zu warten.
-
Demokratisierte Sicherheit: Kleine DeFi-Teams, die sich keine 200.000 US-Dollar teure manuelle Prüfung leisten können, können EVMbench-zertifizierte KI-Agenten für kontinuierliche, hochpräzise Code-Reviews nutzen.
-
Institutionelle Bereitschaft: Während TradFi-Giganten wie Goldman Sachs und Franklin Templeton on-chain gehen, benötigen sie den „Goldstandard“ in KI-Governance, den ein standardisiertes Benchmark bieten kann.
-
Die Dual-Use-Herausforderung: Durch Open-Source-Veröffentlichung des Benchmarks geben OpenAI und Paradigm den „Guten“ die Werkzeuge, um die „Bösen“ zu messen und zu übertreffen, während sie ein „Trusted Access for Cyber“-Framework aufrechterhalten, um aufkommende Risiken zu überwachen.
Ausblick
Obwohl EVMbench ein revolutionärer Schritt ist, ist es derzeit auf deterministische, sandboxed Umgebungen beschränkt. Zukünftige Versionen sollen Multi-Chain-Abhängigkeiten und MEV (Maximal Extractable Value)-Aspekte integrieren, um das „Dark Forest“ des Live-Ethereum-Mainnets besser zu simulieren.
Wenn KI-Agenten vom „Code-Schreiben“ zum „Sichern von Ökonomien“ übergehen, wird EVMbench zum endgültigen Maßstab für die nächste Generation des vertrauenslosen Finanzwesens.
Haftungsausschluss: Die in diesem Artikel präsentierten Ansichten und Analysen dienen nur zu Informationszwecken und spiegeln die Perspektive des Autors wider, nicht die Finanzberatung. Die diskutierten technischen Muster und Indikatoren unterliegen Marktschwankungen und können die erwarteten Ergebnisse nicht garantieren. Anleger werden geraten, vorsichtig zu sein, unabhängige Recherchen durchzuführen und Entscheidungen im Einklang mit ihrer individuellen Risikotoleranz zu treffen.
Über den Autor: Nilesh Hembade ist Gründer und leitender Autor von Coinsprobe und verfügt über mehr als 5 Jahre Erfahrung in der Kryptowährungs- und Blockchain-Branche. Seit der Gründung von Coinsprobe im Jahr 2023 liefert er täglich forschungsbasierte Einblicke durch detaillierte Marktanalysen, On-Chain-Daten und technische Recherchen.