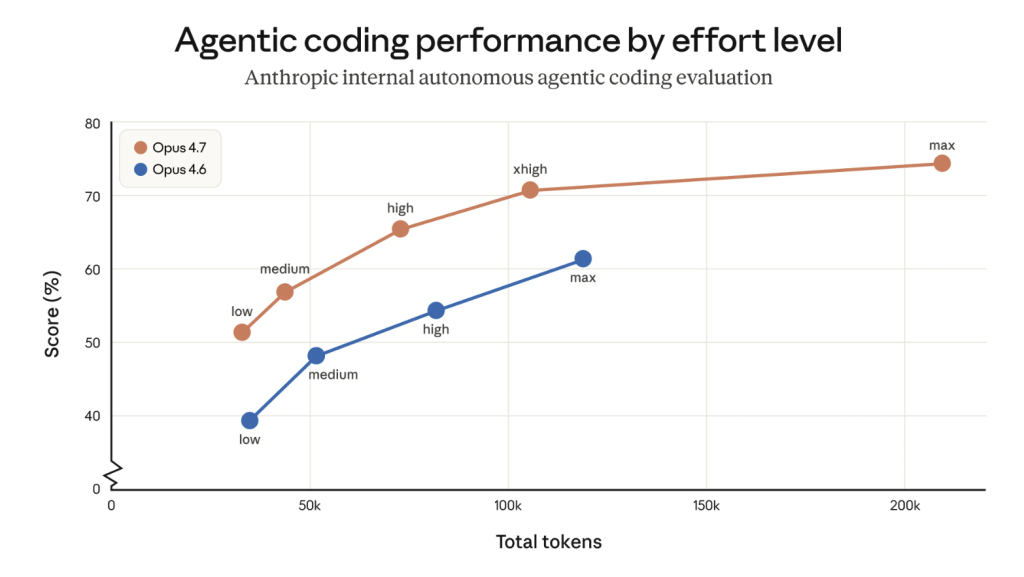
A Anthropic lançou uma versão atualizada de seu modelo carro-chefe, o Claude Opus 4.7, em 16 de abril (horário local). Em comparação com o modelo Opus 4.6 anterior, o Opus 4.7 demonstra “melhorias significativas” em capacidades avançadas de engenharia de software, especialmente em tarefas difíceis, com maior rigor e consistência em operações complexas e de longa duração, além de capacidades aprimoradas de visão. No entanto, a Anthropic deliberadamente enfraqueceu as capacidades de ataque e defesa em cibersegurança do modelo durante o treinamento e introduziu mecanismos de segurança para detectar e bloquear automaticamente solicitações proibidas ou de alto risco.
Desempenho e Benchmarks
Nos testes de benchmark, o Opus 4.7 obteve pontuações geralmente mais altas do que o Opus 4.6 anterior e o GPT-5.4 dos concorrentes. No entanto, a Anthropic enfatizou que as capacidades gerais do Opus 4.7 não correspondem ao modelo mais poderoso da empresa, o Claude Mythos Preview. De acordo com a Anthropic: “Ao implantar e operar esses mecanismos de proteção no mundo real, acumularemos experiência para, no fim, permitir um lançamento mais amplo de modelos no nível Mythos.”
Implantação e Preços
O Opus 4.7 já está em funcionamento em todos os produtos Claude e interfaces de API, integrados ao Amazon Bedrock, ao Google Cloud Vertex AI e aos serviços da Microsoft Foundry. A precificação permanece consistente com o Opus 4.6: $5 por milhão de tokens de entrada e $25 por milhão de tokens de saída.
Mudanças no Consumo de Tokens
Duas mudanças no Opus 4.7 em comparação ao Opus 4.6 afetarão o uso de tokens. Primeiro, o Opus 4.7 usa um tokenizer atualizado, melhorando como o modelo processa o texto. Porém, isso significa que entradas idênticas podem consumir mais tokens—aproximadamente 1 a 1,35 vezes o consumo da geração anterior.
Segundo, o Opus 4.7 realiza mais raciocínio em um nível mais alto de “intensidade de pensamento”, especialmente em rodadas subsequentes de cenários agenticos. Isso melhora a confiabilidade em problemas complexos, mas gera tokens adicionais de saída.
 Maior consumo de tokens do Opus 4.7. Fonte: Anthropic
Maior consumo de tokens do Opus 4.7. Fonte: Anthropic
Análise de Mercado e Contexto
Analistas caracterizam o Opus 4.7 como um modelo “transitório”. O analista de investimentos Adam Button observou que o lançamento do Opus 4.7 reforça a narrativa da Anthropic em torno de “modelos de aparência divina” como o Mythos e confirma o ceticismo do mercado: modelos pagos disponíveis publicamente são essencialmente versões “lite” limitadas por mecanismos de segurança.
Histórico da Empresa e Marco Financeiro
A Anthropic, fundada em 2021 por ex-funcionários da OpenAI, desenvolve a série Claude de grandes modelos de linguagem. Em 6 de abril, a Anthropic anunciou que sua receita anualizada (ARR) excedeu $300 bilhão, um aumento significativo em relação a $9 bilhão no fim de 2025. A empresa está buscando ativamente uma oferta pública inicial.
Preocupações com Risco de Cibersegurança
Executivos da Anthropic têm repetidamente alertado sobre o impacto da IA na cibersegurança. De acordo com reportagens datadas de 10 de abril (horário local), a secretária do Tesouro dos EUA, Yellen, e o presidente do Federal Reserve, Powell, realizaram uma reunião de emergência com líderes de Wall Street em 7 de abril para discutir como o mais recente modelo de IA Mythos da Anthropic poderia aumentar os riscos de cibersegurança. A Anthropic afirmou que o Mythos não é adequado para lançamento ao público porque o modelo poderia ser usado de forma indevida por criminosos cibernéticos e espiões. A empresa está fornecendo acesso seletivo ao Mythos para as principais empresas globais de cibersegurança e software.
Aviso: As informações nesta página podem ser provenientes de terceiros e não representam as opiniões ou pontos de vista da Gate. O conteúdo exibido nesta página é apenas para referência e não constitui aconselhamento financeiro, de investimento ou jurídico. A Gate não garante a exatidão ou integridade das informações e não será responsável por quaisquer perdas decorrentes do uso dessas informações. Os investimentos em ativos virtuais apresentam altos riscos e estão sujeitos a uma volatilidade de preços significativa. Você pode perder todo o capital investido. Por favor, compreenda completamente os riscos envolvidos e tome decisões prudentes com base em sua própria situação financeira e tolerância ao risco. Para mais detalhes, consulte o
Aviso Legal.
Related Articles
Ações dos EUA Abrem em Alta e Queda: Dow Sobe 0,22%, Nasdaq Cai 1,18% em Meio à Venda no Setor de Tecnologia
Mensagem do Gate News, 28 de abril — As ações dos EUA abriram em alta e queda hoje, com o índice de referência ( Dow Jones Industrial Average) de 30 grandes empresas dos EUA( subindo 0,22%, o S&P 500 )amplo benchmark de ações dos EUA( caindo 0,52% e o Nasdaq Composite )índice com forte peso em tecnologia recuando 1,18%.
A venda em massa em ações de tecnologia foi desencadeada por relatórios de que a OpenAI não conseguiu atingir suas metas de receita e de usuários. A Nvidia caiu 3,5%, a AMD caiu 6% e a Oracle recuou 5,9%. O iShares Semiconductor ETF fundo negociado em bolsa que acompanha empresas de semicondutores despencou 4%.
GateNews1h atrás
Liquid capta $18M na Série Seed para expandir a plataforma de trading multiativos
Mensagem do Gate News, 28 de abril — A Liquid, uma plataforma de trading multiativos não custodial, encerrou uma rodada de financiamento Série Seed de $18 milhões, co-liderada pela Left Lane Capital e pela Neo. A rodada também contou com a participação da Paradigm, General Catalyst, Haun Ventures, K5 Global, SV Angel, AntiFund e Sunflo
GateNews1h atrás
Citi ajusta a avaliação do mercado de IA para US$ 4,2 trilhões e prevê CapEx de 8,9 trilhões
Citi 27 de abril informou que ajustou para cima o mercado global de IA em 2030 para US$ 4,2 trilhões e a IA para empresas para US$ 1,9 trilhão; o CapEx também aumentou para US$ 8,9 trilhões em 2026-2030. O mais notável é que o segmento de IA para empresas foi revisado para cima em 58%, o que representa uma velocidade de adoção muito acima do esperado. Os vetores incluem a automação da programação de IA e a difusão do CapEx na camada de aplicação; a receita anualizada do 1T de 2026 da Anthropic atingiu US$ 30 bilhões, indicando crescimento. Para as ações de tecnologia de Taiwan, a alta do CapEx é um catalisador positivo para as demandas de chips e de encapsulamento na cadeia downstream.
ChainNewsAbmedia1h atrás
MIIT da China Aprova 690 Padrões da Indústria, Incluindo a Especificação do Sistema de Imagens de Síntese Profunda de IA
Mensagem do Gate News, 28 de abril — O (Ministério da Indústria e da Tecnologia da Informação da China) MIIT aprovou 690 padrões da indústria, incluindo a "Especificação Técnica do Sistema de Imagens de Síntese Profunda de IA", segundo um comunicado oficial.
Os padrões aprovados abrangem vários setores: indústria química 56 padrões, petroquímica 11, metalurgia ferrosa 81, metais não ferrosos 61, metais preciosos 4, materiais de construção 61, terras raras 9, máquinas 120, automotivo 46, indústria leve 4, têxteis 92, produtos militares e civis 1, eletrônicos 35 e telecomunicações 109. Além disso, foi aprovada uma emenda a um padrão da indústria de telecomunicações intitulada "Guia de Classificação e Arquivamento para Proteção de Segurança de Redes de Telecomunicações e Redes de Internet".
O MIIT também aprovou 28 versões em língua estrangeira de padrões da indústria, incluindo metais não ferrosos 2 versões, terras raras 1 e telecomunicações 25. A emenda do padrão entrará em vigor na data de sua publicação.
GateNews1h atrás
Meituan Lança Silenciosamente o Modelo de IA LongCat-2.0-Preview Com Trilhão de Parâmetros, Sem Anúncio Oficial
Mensagem da Gate News, 28 de abril — A Meituan lançou silenciosamente um novo modelo de IA, LongCat-2.0-Preview, na sua plataforma de API LongCat, com um registro de atualização datado de 20 de abril, mas não fez nenhum anúncio oficial nem publicou relatório técnico. Diferentemente dos modelos anteriores da série LongCat
GateNews2h atrás
