Google 的 Gemini 3 Deep Think 大升级:推理能力碾压 Opus 4.6、GPT-5.2,旨在成为“最擅长科研的 AI”
動區BlockTempo
BTC-3%
谷歌发布 Gemini 3 Deep Think 重大更新,在 ARC-AGI-2 测试中以 84.6% 大幅超越 Claude Opus 4.6(68.8%)和 GPT-5.2(52.9%),同时在 Codeforces 达到“传奇宗师”等级。
(前情提要:ChatGPT 学习模式问世:家教的黄昏,还是黄金教育时代的黎明?)
(背景补充:Google 正式推出“Gemini 3”!登顶全球最聪明 AI 模型,有什么亮点?)
本文目录
- 不只会考试,还会抓人类的错
- 市场份额的地壳变动
- 对加密产业的涟漪效应
- 科学决胜局才刚开始
今天(13日)谷歌发布了 Gemini 3 Deep Think 的重大升级。在 ARC-AGI-2(一个专门防止 AI 背题库的推理测试,不考你知道多少,考你能不能从几个范例中自己归纳出规则)测试中,Gemini 3 Deep Think 拿下了 84.6%。
作为参照,Claude Opus 4.6(Thinking Max 模式)获得 68.8%,GPT-5.2(Thinking xhigh 模式)为 52.9%,而人类平均约 60%。
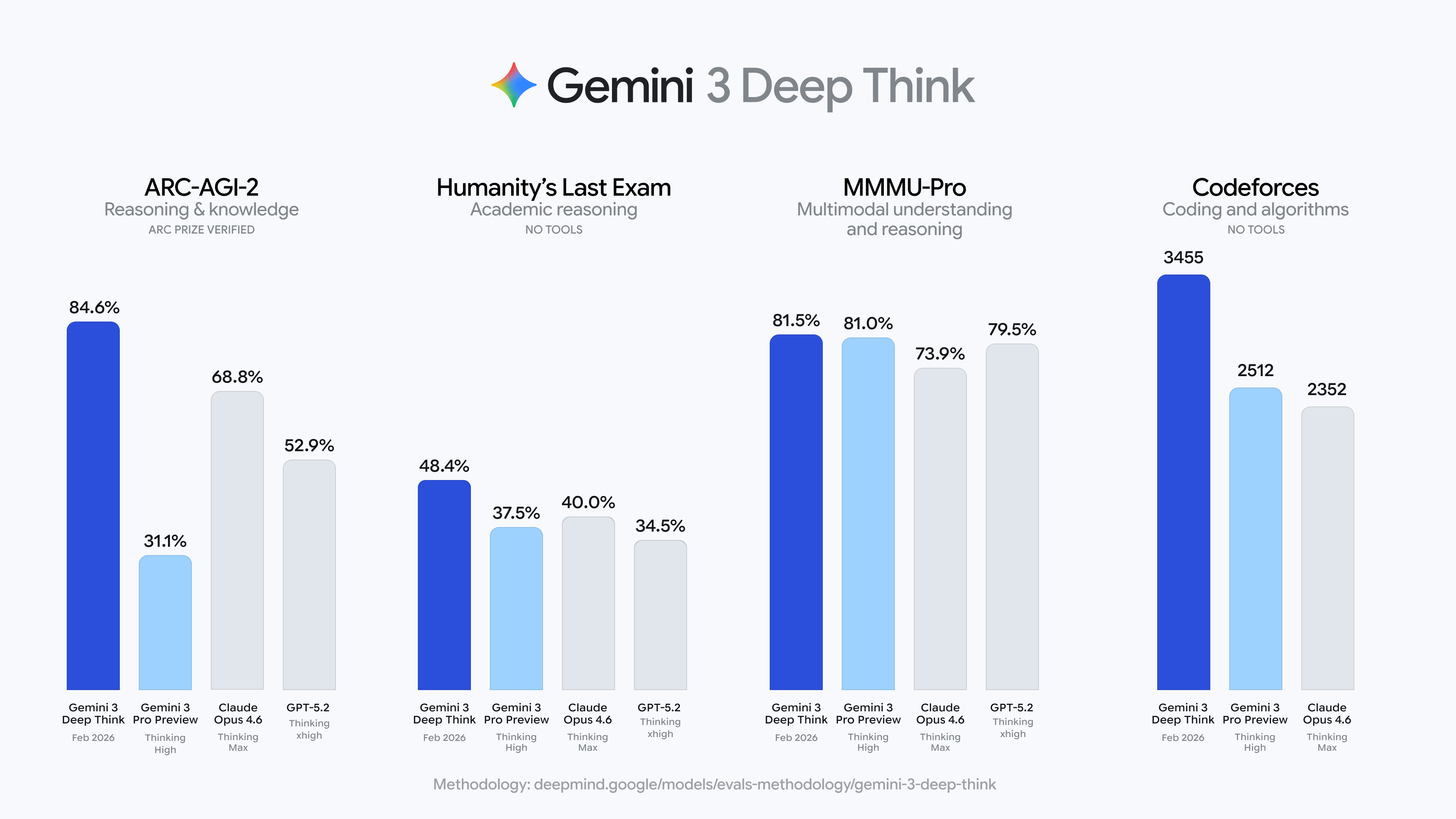
更令人惊讶的是,在原版 ARC-AGI-1 上,Deep Think 拿到 96%,基本上把这个曾被视为“AI 最难考试之一”的基准测试考到了天花板。
Deep Think 目前开放给 Google AI Ultra 订阅用户,API 则面向企业开放早期访问。
不只会考试,还会抓人类的错
跑分之外,谷歌在公告中提到一个细节:Deep Think 在审阅一篇经过人类同行评审的数学论文时,成功找出了一个之前所有审稿人都没发现的逻辑漏洞。这篇论文由罗格斯大学(Rutgers University)的数学家确认。
这个案例的重要性在于,它不是模型在标准化测试中的表现,而是在真实的、开放式的科学场景中展现的能力。同行评审是学术界最核心的质量控制机制,如果 AI 能稳定地在这个环节提供有价值的辅助,它对科学研究的加速效应将远超任何跑分所能衡量。
Deep Think 同时在 2025 年国际物理奥林匹克和化学奥林匹克的笔试部分达到金牌水平,在 Codeforces 上的 Elo 评分为 3,455,对应“传奇宗师”等级,全球仅极少数人类程序设计师能达到这个层级。
而在“人类最后的考试”(Humanity’s Last Exam)这个由各领域专家设计、刻意让 AI 难以作答的基准上,Deep Think 拿到 48.4%(不使用工具),也创下新纪录。
市场份额的地壳变动
AI 三巨头的技术竞赛正在改变市场版图。ChatGPT 的市场份额已从巅峰时期的 87% 降至约 68%,而 Gemini 从不到 5% 飙升至超过 18%、Anthropic 的 Claude 则稳步蚕食企业级市场。
谷歌在这场竞赛中的独特优势是分发能力。Gemini 内建在 Android 系统、Chrome 浏览器、Google Workspace 和搜索引擎中,这意味着即使在模型能力上与对手打平,谷歌也能通过渠道优势赢得用户。
但分发优势是双刃剑。如果 Gemini 的体验不够好,它可能会比任何竞品更快地失去用户信任,因为用户是“被动接触”而非“主动选择”。OpenAI 的用户是主动付费的,天生有更高的容忍度和黏性。
对加密产业的涟漪效应
AI 军备竞赛的每一次升级,都在推高对运算基础设施的需求。训练一个前沿模型所需的 GPU 叢集成本已经从 2024 年的数亿美元级别,膨胀到 2026 年的数十亿美元级别。这也直接影响了两件事。
**第一,比特币矿工的转型路径。**当挖矿利润被压缩(摩根大通本周估算 BTC 生产成本降至 7.7 万美元,而币价在 6.6 万附近),拥有大规模算力基础设施的矿工正加速转向 AI 计算服务。
高成本矿企不是“退出”,而是“转业”,从挖比特币变成提供 AI 算力的合约收入。
**第二,AI 代币的叙事。**每当谷歌、OpenAI 或 Anthropic 发布重大升级,链上 AI 相关代币(如去中心化运算协议)通常会出现短期炒作。
但这些代币的基本面问题始终没变:去中心化运算在延迟和吞吐量上,距离企业级 AI 训练的需求还很长一段路要走。叙事可以跑得很快,但基础设施还追不上叙事的速度。
科学决胜局才刚开始
Deep Think 的升级让谷歌再次回到 AI 竞赛的领跑位置,至少在推理和科学领域如此。但如果你仔细看谷歌的公告措辞,会发现一个微妙的定位转变:它不再强调“最聪明的通用 AI”,而是反复提及“为科学而生”。
当通用 AI 的基准测试越来越拥挤、差异化越来越难,“我的 AI 能帮你做科学研究”成为一个比“我的 AI 跑分最高”更有说服力的价值主张。如果 Deep Think 真的能稳定地辅助同行评审、加速药物发现、或在物理模拟中找到人类遗漏的解,这比任何跑分榜单都更有意义。
问题是,从“能在基准测试上拿高分”到“能在真实科学场景中可靠地辅助人类”,中间的距离可能比谷歌暗示的更远,毕竟基准测试有标准答案,科学没有。

免责声明:本页面信息可能来自第三方,不代表 Gate 的观点或意见。页面显示的内容仅供参考,不构成任何财务、投资或法律建议。Gate 对信息的准确性、完整性不作保证,对因使用本信息而产生的任何损失不承担责任。虚拟资产投资属高风险行为,价格波动剧烈,您可能损失全部投资本金。请充分了解相关风险,并根据自身财务状况和风险承受能力谨慎决策。具体内容详见声明。
相关文章
评论
0/400
暂无评论