Phân tích sâu về Nesa: Tại sao AI bạn sử dụng hàng ngày lại cần bảo vệ quyền riêng tư?
Báo cáo này do Tiger Research biên soạn, hầu hết mọi người đều sử dụng AI hàng ngày, nhưng chưa từng nghĩ xem dữ liệu của mình đang chảy về đâu. Câu hỏi mà Nesa đặt ra là: Khi bạn bắt đầu đối mặt với vấn đề này, sẽ xảy ra điều gì?
Các điểm chính
- AI đã trở thành phần không thể thiếu trong cuộc sống hàng ngày, nhưng người dùng thường bỏ qua cách dữ liệu được truyền qua máy chủ trung tâm
- Ngay cả đại diện của CISA – cơ quan an ninh mạng hàng đầu của Mỹ – cũng vô tình để lộ tài liệu mật của chính phủ cho ChatGPT
- Nesa đã tái cấu trúc quy trình này bằng cách sử dụng chuyển đổi dữ liệu trước khi truyền (EE) và phân chia qua các nút (HSS-EE), đảm bảo không bên nào có thể xem được dữ liệu gốc
- Các chứng nhận học thuật (COLM 2025) và triển khai thực tế của doanh nghiệp (P&G) đã giúp Nesa có lợi thế đi trước
- Liệu thị trường rộng lớn hơn có chọn AI quyền riêng tư phi tập trung thay vì API trung tâm quen thuộc, vẫn là câu hỏi then chốt
1. Dữ liệu của bạn có an toàn không?

Nguồn: CISA
Tháng 1 năm 2026, đại diện của CISA – cơ quan an ninh mạng hàng đầu của Mỹ – là Madhu Gottumukkala đã tải lên các tài liệu nhạy cảm của chính phủ lên ChatGPT, chỉ để tổng hợp và sắp xếp các tài liệu hợp đồng liên quan.
Vụ rò rỉ này không bị ChatGPT phát hiện, OpenAI cũng không báo cáo với chính phủ. Thay vào đó, bị hệ thống an ninh nội bộ của tổ chức này phát hiện và do vi phạm quy trình an toàn đã dẫn đến cuộc điều tra.
Ngay cả các quan chức an ninh mạng cao nhất của Mỹ cũng thường xuyên sử dụng AI trong công việc, thậm chí vô tình tải lên tài liệu mật.
Chúng ta đều biết rằng, hầu hết các dịch vụ AI sẽ lưu trữ dữ liệu người dùng dưới dạng mã hóa trên máy chủ trung tâm. Nhưng chính thiết kế của mã hóa này là có thể đảo ngược được. Trong trường hợp được phép hợp pháp hoặc khẩn cấp, dữ liệu có thể bị giải mã và tiết lộ, trong khi người dùng không hề hay biết về điều đó.
2. AI bảo mật cho sử dụng hàng ngày: Nesa
AI đã trở thành phần không thể thiếu trong cuộc sống hàng ngày — tổng hợp bài viết, viết mã, soạn email. Điều đáng lo ngại thực sự là, như ví dụ trên cho thấy, ngay cả các tài liệu mật và dữ liệu cá nhân cũng bị giao cho AI mà người dùng gần như không nhận thức được rủi ro.
Vấn đề cốt lõi là: tất cả dữ liệu này đều phải đi qua máy chủ trung tâm của nhà cung cấp dịch vụ. Dù đã mã hóa, chìa khóa giải mã vẫn nằm trong tay nhà cung cấp. Người dùng có thể tin vào điều gì để chấp nhận sự sắp xếp này?
Dữ liệu người dùng nhập vào có thể bị tiết lộ cho bên thứ ba qua nhiều kênh: huấn luyện mô hình, kiểm tra an ninh, yêu cầu pháp lý. Trong phiên bản doanh nghiệp, quản trị viên tổ chức có thể truy cập lịch sử trò chuyện; trong phiên bản cá nhân, dữ liệu cũng có thể bị chuyển giao hợp pháp.

Khi AI đã ăn sâu vào đời sống hàng ngày, đã đến lúc phải xem xét nghiêm túc vấn đề quyền riêng tư.
Nesa chính là dự án sinh ra để thay đổi hoàn toàn cấu trúc này. Nó xây dựng hạ tầng phi tập trung, cho phép thực hiện suy luận AI mà không cần gửi dữ liệu về trung tâm. Dữ liệu người dùng được xử lý trong trạng thái mã hóa, bất kỳ nút đơn lẻ nào cũng không thể xem được dữ liệu gốc.
3. Nesa giải quyết vấn đề như thế nào
Hãy tưởng tượng một bệnh viện sử dụng Nesa. Bác sĩ muốn AI phân tích hình ảnh MRI của bệnh nhân để phát hiện ung thư. Trong các dịch vụ AI hiện tại, hình ảnh sẽ được gửi trực tiếp đến máy chủ của OpenAI hoặc Google.
Trong khi đó, khi dùng Nesa, hình ảnh đã được thực hiện chuyển đổi toán học trước khi rời khỏi máy tính của bác sĩ.
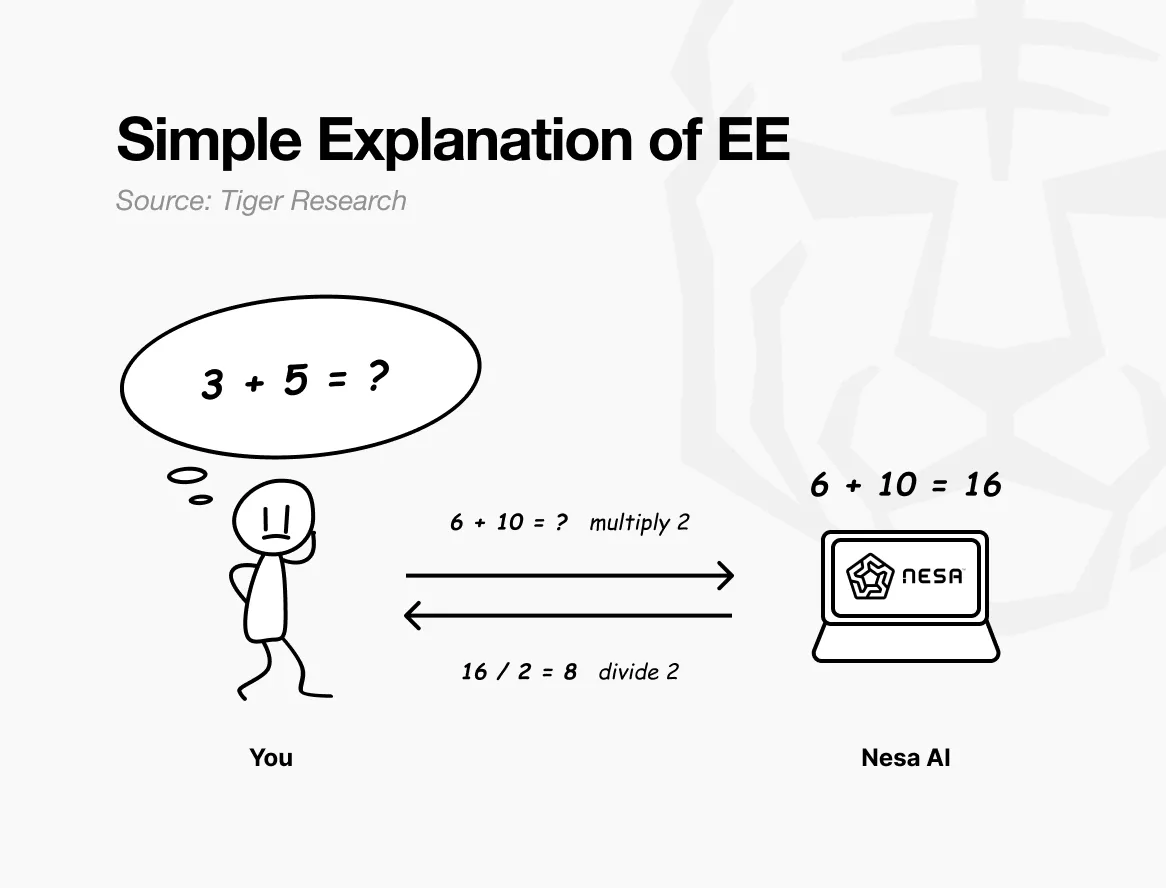
Ví dụ đơn giản: giả sử câu hỏi ban đầu là “3 + 5 = ?” Nếu gửi trực tiếp, bên nhận rõ ràng biết bạn đang tính gì.
Nhưng nếu trước khi gửi, mỗi số được nhân đôi, bên nhận sẽ thấy “6 + 10 = ?” và trả về 16. Bạn chia đôi kết quả để có 8 — hoàn toàn trùng khớp với kết quả tính trực tiếp của câu hỏi ban đầu. Bên nhận đã thực hiện tính toán, nhưng không bao giờ biết được các số ban đầu là gì.
Đây chính là tính biến đổi đồng đẳng (EE) mà Nesa thực hiện. Dữ liệu trước khi truyền đi sẽ qua phép biến đổi toán học, mô hình AI sẽ tính trên dữ liệu đã biến đổi đó.
Người dùng sau đó áp dụng phép nghịch đảo để lấy kết quả, và kết quả cuối cùng hoàn toàn giống như tính trên dữ liệu gốc. Trong toán học, đặc tính này gọi là tính biến đổi đồng đẳng: không phân biệt trước hay sau biến đổi, kết quả vẫn nhất quán.
Trong thực tế, phép biến đổi này phức tạp hơn nhiều so với nhân đôi đơn giản — nó được thiết kế phù hợp với cấu trúc nội tại của mô hình AI. Chính vì phép biến đổi này ăn khớp hoàn hảo với quy trình xử lý của mô hình, độ chính xác không bị ảnh hưởng.
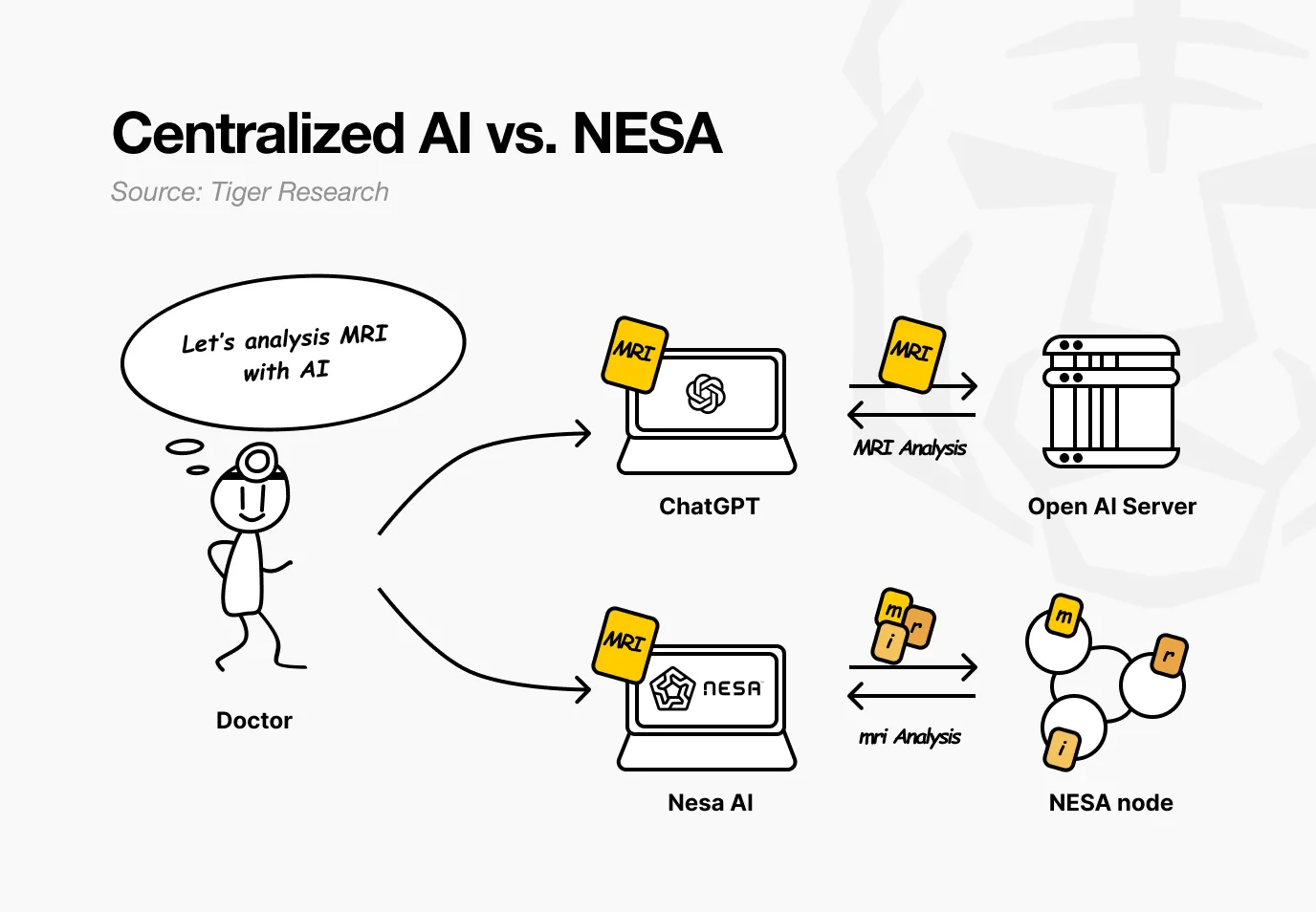
Quay lại ví dụ bệnh viện. Đối với bác sĩ, toàn bộ quy trình không thay đổi — tải hình ảnh lên, nhận kết quả, mọi thứ vẫn như cũ. Điều khác biệt là: bất kỳ nút trung gian nào cũng không thể xem được dữ liệu MRI gốc của bệnh nhân.
Nesa còn tiến xa hơn nữa. Chỉ với EE, có thể ngăn chặn các nút xem dữ liệu gốc, nhưng dữ liệu đã biến đổi vẫn tồn tại đầy đủ trên một máy chủ duy nhất.
HSS-EE (Chia sẻ bí mật đồng đẳng trên mã hóa nhúng) còn chia nhỏ dữ liệu đã biến đổi đó ra nữa.
Tiếp tục ví dụ trước. EE tương đương như việc trước khi gửi đề thi, áp dụng quy tắc nhân; HSS-EE giống như xé đề thi đã biến đổi thành hai phần — phần đầu gửi cho nút A, phần sau gửi cho nút B.
Mỗi nút chỉ có thể trả lời phần của mình, không thể xem toàn bộ đề. Chỉ khi hai phần này hợp lại mới ra được đáp án đầy đủ — và chỉ người gửi ban đầu mới có thể thực hiện thao tác hợp nhất này.
Tóm lại: EE biến đổi dữ liệu, khiến nội dung gốc không thể xem trực tiếp; HSS-EE chia nhỏ dữ liệu đã biến đổi, đảm bảo không bao giờ toàn bộ dữ liệu xuất hiện ở một nơi nào. Bảo vệ quyền riêng tư được tăng cường gấp đôi.
4. Bảo vệ quyền riêng tư có làm chậm hiệu năng không?
Các biện pháp bảo vệ quyền riêng tư mạnh hơn thường đi kèm với hiệu năng chậm hơn — đó là quy luật lâu dài của lĩnh vực mật mã. Phép mã hóa đồng đẳng toàn phần (FHE) nổi tiếng nhất hiện nay chậm hơn so với tính toán thông thường từ 10.000 đến 1.000.000 lần, không thể ứng dụng cho dịch vụ AI thời gian thực.
Trong khi đó, EE của Nesa theo hướng khác. Quay lại ví dụ toán học: nhân đôi trước khi gửi, chia đôi sau khi nhận chỉ mất chút ít công sức.
Khác với FHE biến toàn bộ vấn đề thành một hệ thống toán học hoàn toàn khác, EE chỉ thêm một lớp chuyển đổi nhẹ dựa trên nền tảng tính toán hiện có.
Dữ liệu thử nghiệm:
- EE: độ trễ tăng chưa đến 9%, độ chính xác giữ nguyên, đạt hơn 99.99%
- HSS-EE: trên LLaMA-2 7B, mỗi lần suy luận mất từ 700 đến 850 mili giây
Ngoài ra, MetaInf – bộ điều phối học meta đã tối ưu hóa hiệu quả toàn mạng. Nó đánh giá kích thước mô hình, cấu hình GPU, đặc điểm đầu vào để tự động chọn phương pháp suy luận nhanh nhất.
MetaInf đạt độ chính xác lựa chọn 89.8%, tốc độ nhanh hơn trình chọn truyền thống 1.55 lần. Thành quả này đã được công bố tại COLM 2025, nhận được sự công nhận của giới học thuật.
Các số liệu này đến từ môi trường thử nghiệm kiểm soát. Nhưng quan trọng hơn, hạ tầng suy luận của Nesa đã được triển khai thực tế trong doanh nghiệp, chứng minh hiệu năng vận hành ở cấp độ sản xuất.
5. Ai đang dùng? Dùng như thế nào?

Có ba cách tiếp cận Nesa.
Thứ nhất là Playground. Người dùng có thể truy cập trực tiếp trên web để chọn và thử nghiệm mô hình, không cần kỹ năng lập trình. Bạn có thể trải nghiệm toàn bộ quy trình nhập dữ liệu, xem kết quả của các mô hình.
Đây là cách nhanh nhất để hiểu cách hoạt động của suy luận AI phi tập trung.
Thứ hai là gói Pro. 8 USD mỗi tháng, gồm truy cập không giới hạn, 1.000 điểm suy luận nhanh mỗi tháng, kiểm soát giá mô hình tùy chỉnh, và trang giới thiệu đặc trưng của mô hình.
Gói này dành cho các cá nhân hoặc nhóm nhỏ muốn triển khai, vận hành và kiếm tiền từ mô hình của riêng mình.
Thứ ba là Enterprise. Không phải giá cố định công khai, mà là hợp đồng tùy chỉnh. Bao gồm hỗ trợ SSO/SAML, lựa chọn vùng lưu trữ dữ liệu, nhật ký kiểm tra, kiểm soát truy cập chi tiết, thanh toán theo hợp đồng hàng năm.
Giá khởi điểm là 20 USD mỗi người dùng mỗi tháng, nhưng điều khoản thực tế sẽ thương lượng dựa theo quy mô. Dành cho các tổ chức muốn tích hợp Nesa vào quy trình AI nội bộ, cung cấp API và quản lý tổ chức qua thỏa thuận riêng.
Tóm lại: Playground để trải nghiệm, Pro phù hợp cá nhân hoặc nhóm nhỏ, Enterprise dành cho tổ chức lớn.
6. Tại sao cần token?
Mạng phi tập trung không có quản trị trung tâm. Các thực thể vận hành máy chủ và xác thực kết quả phân tán khắp toàn cầu. Tất nhiên, câu hỏi đặt ra là: tại sao ai đó lại sẵn sàng để GPU của mình hoạt động liên tục, xử lý suy luận AI cho người khác?
Câu trả lời là động lực kinh tế. Trong mạng Nesa, động lực này chính là token $NES.
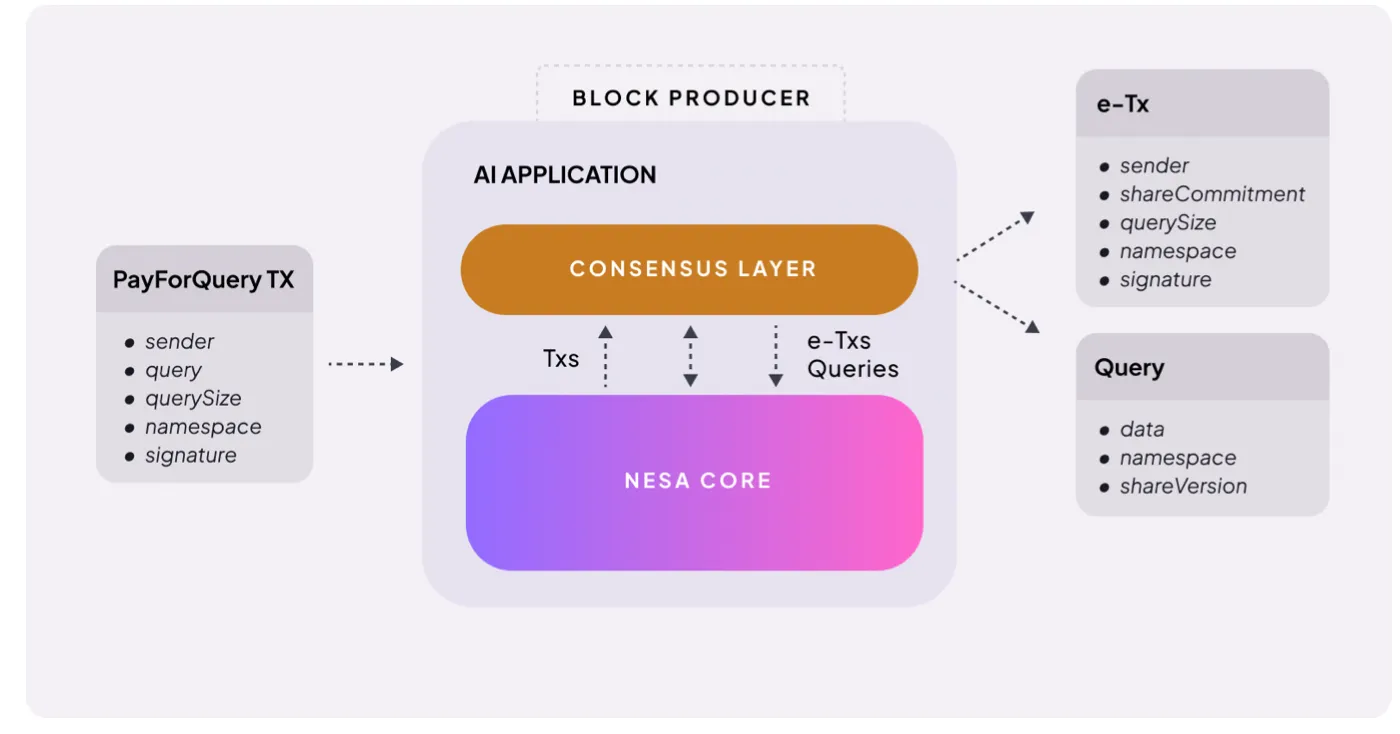
Nguồn: Nesa
Cơ chế rất đơn giản. Khi người dùng gửi yêu cầu suy luận AI, họ phải trả phí. Nesa gọi đó là PayForQuery, gồm phí cố định cho mỗi giao dịch cộng với phí biến đổi tỷ lệ theo lượng dữ liệu.
Phí cao hơn sẽ được ưu tiên xử lý trước — tương tự như nguyên tắc gas trong blockchain.
Các khoản phí này sẽ được các thợ mỏ (miner) nhận. Để tham gia mạng, thợ mỏ phải đặt cọc một lượng $NES nhất định — trước khi nhận nhiệm vụ, họ phải đưa token của mình vào rủi ro.
Nếu thợ mỏ trả kết quả sai hoặc không phản hồi, sẽ bị trừ phần tiền đặt cọc; nếu xử lý chính xác, nhanh chóng, họ sẽ nhận phần thưởng cao hơn.
$NES còn là công cụ quản trị. Người nắm giữ token có thể đề xuất các dự án, bỏ phiếu về các tham số cốt lõi của mạng như phí, phần thưởng.
Tổng thể, $NES đóng vai trò ba trong một: phương thức thanh toán cho yêu cầu suy luận, tài sản thế chấp và phần thưởng cho thợ mỏ, và công cụ tham gia quản trị mạng. Không có token, các nút sẽ không vận hành; không vận hành, AI bảo mật sẽ không thể tồn tại.
Điều cần chú ý là: hoạt động của kinh tế token phụ thuộc vào các điều kiện tiên quyết.
Nhu cầu suy luận phải đủ lớn để phần thưởng có ý nghĩa; phần thưởng có ý nghĩa thì thợ mỏ mới ở lại mạng; số lượng thợ mỏ đủ lớn thì chất lượng mạng mới được duy trì.
Đây là vòng tuần hoàn tích cực: nhu cầu thúc đẩy cung, cung duy trì nhu cầu — nhưng khởi đầu vòng này lại là giai đoạn khó khăn nhất.
Các khách hàng doanh nghiệp như P&G đã bắt đầu sử dụng mạng này trong môi trường sản xuất, là tín hiệu tích cực. Nhưng khi quy mô mạng mở rộng, liệu giá trị token và phần thưởng khai thác có duy trì cân bằng không vẫn còn là câu hỏi.
7. Tại sao cần AI bảo mật quyền riêng tư?
Nesa hướng tới giải quyết rõ ràng vấn đề: thay đổi cấu trúc khiến dữ liệu người dùng không còn bị tiết lộ cho bên thứ ba khi sử dụng AI.
Cơ sở kỹ thuật vững chắc. Các công nghệ mã hóa cốt lõi — đồng đẳng hóa EE và HSS-EE — đều xuất phát từ nghiên cứu học thuật. Bộ điều phối tối ưu hóa suy luận MetaInf đã được trình bày tại COLM 2025.
Đây không chỉ là trích dẫn nghiên cứu. Nhóm nghiên cứu đã trực tiếp thiết kế giao thức, triển khai vào mạng lưới.
Trong các dự án AI phi tập trung, rất ít dự án có thể xác minh được nguyên thủy mã hóa của mình ở cấp độ học thuật, rồi đưa vào hạ tầng vận hành thực tế. Các doanh nghiệp lớn như P&G đã vận hành các tác vụ suy luận dựa trên hạ tầng này — điều này là tín hiệu rất tích cực cho các dự án sơ khai.
Tuy nhiên, cũng rõ ràng về giới hạn:
- Thị trường mục tiêu: ưu tiên khách hàng tổ chức; người dùng cá nhân chưa sẵn sàng trả phí cho quyền riêng tư
- Trải nghiệm sản phẩm: Playground giống như giao diện Web3 hoặc đầu tư hơn là ứng dụng AI hàng ngày
- Xác thực quy mô: thử nghiệm kiểm soát không thể phản ánh vận hành với hàng nghìn nút đồng thời trong môi trường thực tế
- Thời điểm thị trường: nhu cầu AI quyền riêng tư là có thật, nhưng nhu cầu AI quyền riêng tư phi tập trung chưa được xác thực; doanh nghiệp vẫn quen dùng API trung tâm
Hầu hết các doanh nghiệp vẫn quen dùng API trung tâm, hạ tầng dựa trên blockchain vẫn còn nhiều rào cản.
Chúng ta đang sống trong thời đại này: ngay cả các quan chức an ninh mạng Mỹ cũng tải tài liệu mật lên AI. Nhu cầu về AI bảo mật quyền riêng tư đã tồn tại và sẽ ngày càng tăng.
Nesa sở hữu công nghệ đã được học thuật xác thực và hạ tầng vận hành thực tế để đáp ứng nhu cầu này. Dù còn hạn chế, nhưng đã có bước đi dẫn đầu so với các dự án khác.
Khi thị trường AI quyền riêng tư thực sự mở ra, Nesa chắc chắn sẽ là một trong những tên tuổi được nhắc đến đầu tiên.